@kkasianenko_at_aoir Thanks a lot for sharing! Was great to meet you and have a nerdy talk next to a bumber car ride 😅
Ahrabhi Kathirgamalingam
she/her | Researcher at CAIS, Germany | PhD candidate at Computational Comm Science Lab @ University of Vienna | studying marginalization & bias in news media and #ComputationalSocialScience 🔎
Ahrabhi Kathirgamalingam boosted:
Of course, we are also interested in how LLMs deal with the same task. Ahrabhi's findings suggest that variance, or disagreement on marginalising topics also exists with LLMs, driven by model selection or personas that researchers may assign to LLMs. However, in some areas, LLMs are better than human coders at picking up subtle instances of marginalisation. I could write more about this paper as I find it fantastic, but it's better you read it for yourself: https://osf.io/preprints/socarxiv/agpyr
Ahrabhi Kathirgamalingam boosted:
Ahrabhi and team start from the premise that humans disagree on what represents marginalisation in texts due to their positionality (e.g., how often they are targets of racism). This may be seen as a problem when trying to create a gold-standard dataset on these topics, as we would normally want to have a good agreement between human coders that is supposed to reveal "the ground truth". Ahrabhi suggests that we should instead accept the variance and sacrifice the intercoder reliability score.
Ahrabhi Kathirgamalingam boosted:
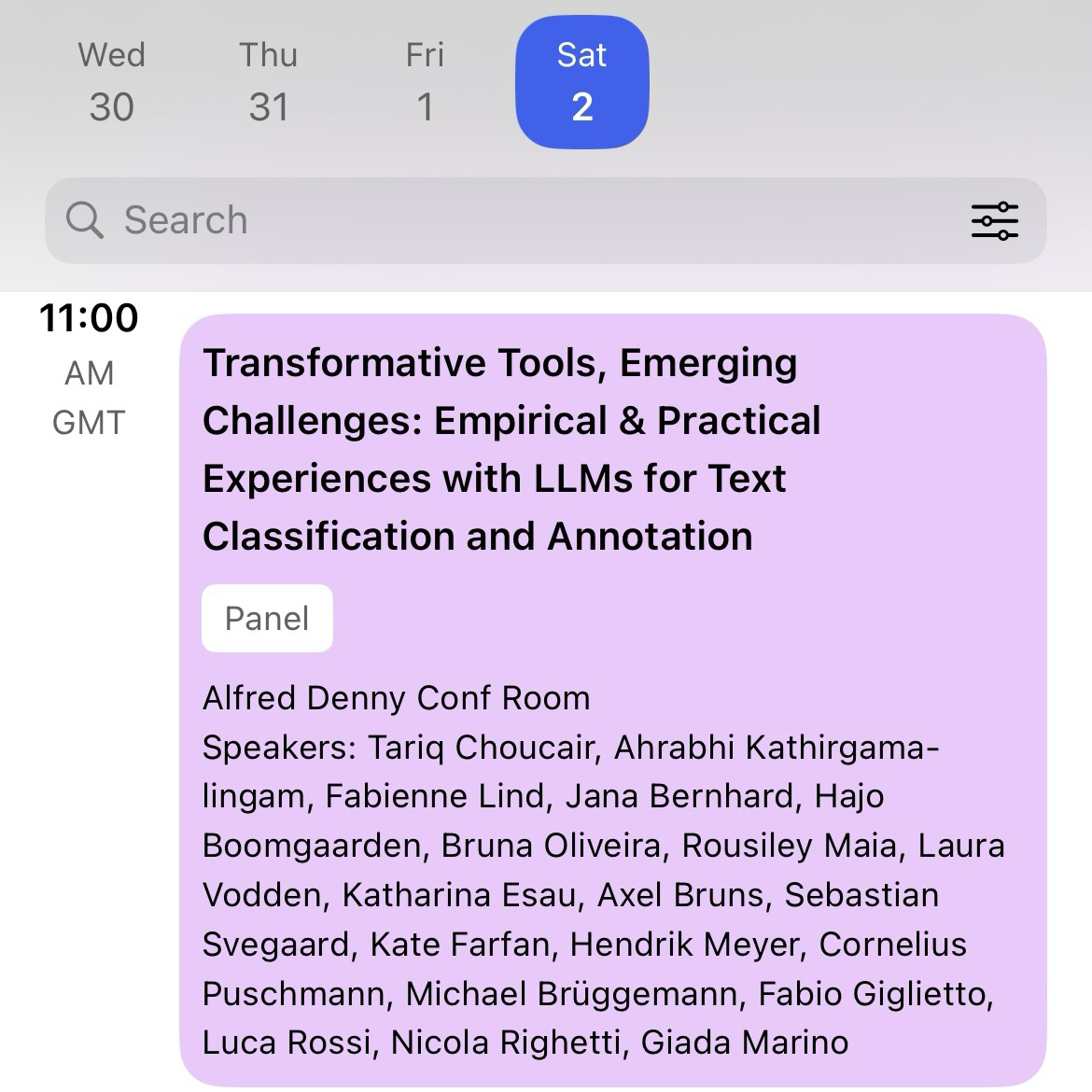
My last session of #AoIR2024 was incredible which is not surprising as it was put together by @qutdmrc's excellent Tariq Chocair. It highlighted multiple practical and normative aspects of the use of LLMs for text classification in the field of internet research. It was kicked off by the fabulous @AhrabhiKat speaking about bias observed in LLMs and human coders when dealing with various constructs of marginalisation (including racism, hate speech, and more)
Can‘t join? Check out our preprint then with Fabienne Lind, Jana Bernhard-Harrer and Hajo G. Boomgaarden: https://osf.io/preprints/socarxiv/agpyr
Thinking about using #LLM for your #textasdata research? …Think twice! And join our panel tomorrow at #aoir2024

Sprache kann Diskriminierung verstärken! – In dieser kurzen Umfrage sammeln wir rassistische Begriffe, die euch in Medien aufgefallen sind. Bitte nehmt teil und teilt die Umfrage gerne in euren Netzwerken. Danke! Ich freue mich über jeden Support für mein Diss-Projekt ❤️ 📝➡️ http://bitly.ws/BYLg
Ahrabhi Kathirgamalingam boosted:
Hey #rstats friends,
want to use some #python tools in your project but keep the rest of your code in R? Have a look at my workshop, organized through Dariia Mykhailyshyna's #WorkshopsForUkraine.
Sign up here: https://docs.google.com/forms/d/e/1FAIpQLSfG7u0HwJIOChwSsCZxolzEd-kH5viLDMaR-z-lhu-2O7ngow/viewform all benefits go to #StandWithUkraine
Ahrabhi Kathirgamalingam boosted:
Die Klimaproteste rund um #Luetzerath sind weltweit Thema in den Medien. Dennoch schränken der Energiekonzern RWE und die Polizei die #Pressefreiheit vor Ort erheblich ein. Die Journalist:innengewerkschaft dju kritisiert das und schickt jetzt einen Beobachter ins Geschehen.
https://netzpolitik.org/2023/klimaproteste-schikanen-und-uebergriffe-gegen-presse-in-luetzerath/
Ahrabhi Kathirgamalingam boosted:
RT @DezimInstitut@twitter.com
Ab sofort können Interessierte über einen Data Explorer tief in die Ergebnisse des ersten #Afrozensus einsteigen und sie für eigene Analysen nutzen. Herzlichen Dank an das Team @EOTOBerlin@twitter.com & @opencitizenship@twitter.com für dieses wichtige Angebot! https://twitter.com/DanielGyamerah/status/1600820510631133185
🐦🔗: https://twitter.com/DezimInstitut/status/1601202267721719808
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst