Valkey Turns One: Community fork of Redis
https://www.gomomento.com/blog/valkey-turns-one-how-the-community-fork-left-redis-in-the-dust/
#ycombinator
Henry Saputra
Working on intersection of system and machine learning
Henry Saputra boosted:
Henry Saputra boosted:
Valkey Turns One: How the Community Fork Left Redis in the Dust
https://www.gomomento.com/blog/valkey-turns-one-how-the-community-fork-left-redis-in-the-dust/
#ycombinator
Henry Saputra boosted:
Microsandbox: Virtual Machines that feel and perform like containers
https://github.com/microsandbox/microsandbox
#ycombinator
Henry Saputra boosted:
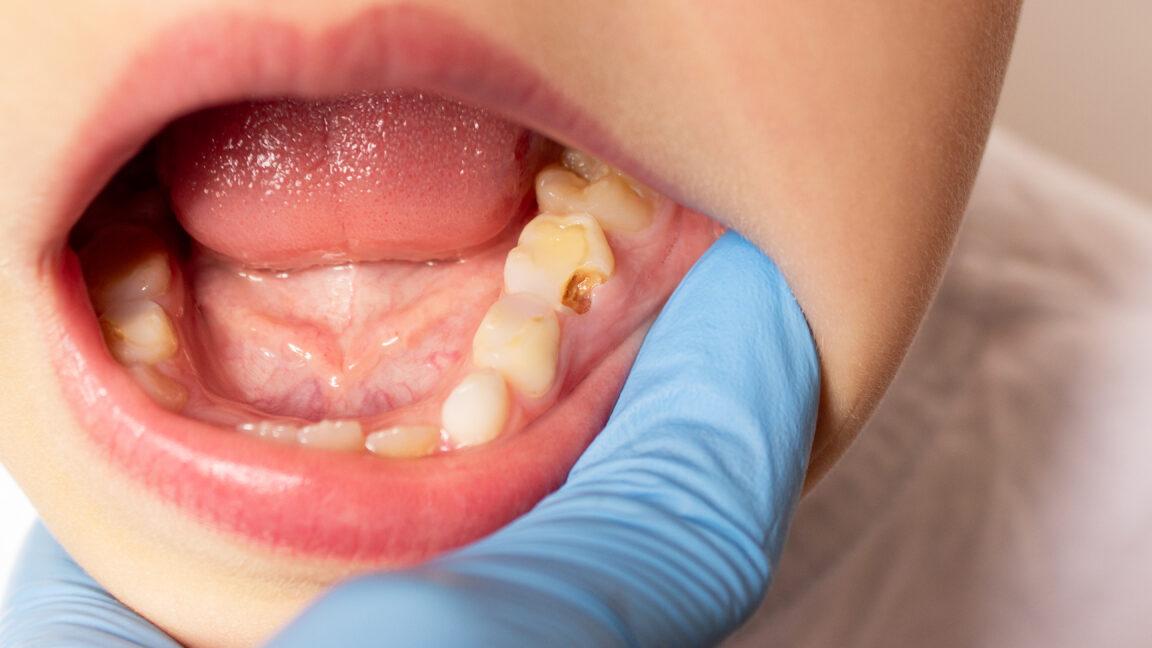
RFK Jr.‘s fluoride ban would ruin 25 million kids’ teeth, cost $9.8 billion
The modeling estimates don't account for other costs, like parents' lost work.
https://arstechnica.com/health/2025/05/rfk-jr-s-fluoride-ban-would-ruin-25-million-kids-teeth-cost-9-8-billion/?utm_brand=arstechnica&utm_social-type=owned&utm_source=mastodon&utm_medium=social
Efficiently Scaling Transformer Inference
Data splitting to avoid information leakage with DataSAIL | Nature Communications
https://www.nature.com/articles/s41467-025-58606-8
Double Descent Demystified: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle
Henry Saputra boosted:
Data breach exposes 184M passwords for Google,Microsoft,Facebook
https://www.zdnet.com/article/massive-data-breach-exposes-184-million-passwords-for-google-microsoft-facebook-and-more/
#ycombinator
Agent Distillation transfers reasoning and task-solving capabilities from large language models to smaller models using enhanced prompts and self-consistent actions, matching performance of larger models on various reasoning tasks.
Paper page - Distilling LLM Agent into Small Models with Retrieval and Code Tools
https://huggingface.co/papers/2505.17612
Oh, Hello, what is this ...
Red Hat Launches the llm-d Community, Powering Distributed Gen AI Inference at Scale
https://www.redhat.com/en/about/press-releases/red-hat-launches-llm-d-community-powering-distributed-gen-ai-inference-scale
NVIDIA Dynamo Accelerates llm-d Community Initiatives for Advancing Large-Scale Distributed Inference | NVIDIA Technical Blog
https://developer.nvidia.com/blog/nvidia-dynamo-accelerates-llm-d-community-initiatives-for-advancing-large-scale-distributed-inference/
Announcing the llm-d community! | llm-d
https://llm-d.ai/blog/llm-d-announce
llm-d is a Kubernetes-native high-performance distributed LLM inference framework
llm-d · GitHub
https://github.com/llm-d
TIL - Amazon SageMaker HyperPod recipes help customers get started with training and fine-tuning popular publicly available foundation models in just minutes, with state-of-the-art performance
KernelLLM, a large language model based on Llama 3.1 Instruct, which has been trained specifically for the task of authoring GPU kernels using Triton. KernelLLM translates PyTorch modules into Triton kernels and was evaluated on KernelBench-Triton
Henry Saputra boosted:
Performance of Confidential Computing GPUs
Gemma 3n model overview | Google AI for Developers
https://ai.google.dev/gemma/docs/gemma-3n
AI Hallucination Cases Database – Damien Charlotin
https://www.damiencharlotin.com/hallucinations/
Henry Saputra boosted:
AI Hallucination Cases Database
https://www.damiencharlotin.com/hallucinations/
#ycombinator
Parents will always be parenting ...
https://www.reddit.com/r/outofcontextcomics/s/YlVMtmAfw0
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst