Visit our booth at #railsconf to get your kazoo! Watching us make fools of ourselves is just a bonus.
Adam McCrea
Indie founder & developer at Judoscale (formerly Rails Autoscale).
Who’s ready to party? #railsconf #kazoos
If it’s not at least a little bit cringe, we didn’t go far enough. #railsconf #kazoos #marketing
Marketing technique #77: Humiliate yourself for attention. #railsconf #kazoos
Y’all this is only the beginning. Buckle up! #railsconf #kazoos
@soulcutter Autoscaling is not a silver bullet, for sure. There are good ways to autoscale and less good ways, so I'm not surprised you've gotten burned.
That’s where proactive autoscaling comes in. By targeting, say, 60% utilization, you’re building in 40% headroom for unexpected spikes. You’re trading efficiency (and some cost) for reliability.
🧠 More on the differences and trade-offs: https://judoscale.com/blog/introducing-proactive-autoscaling
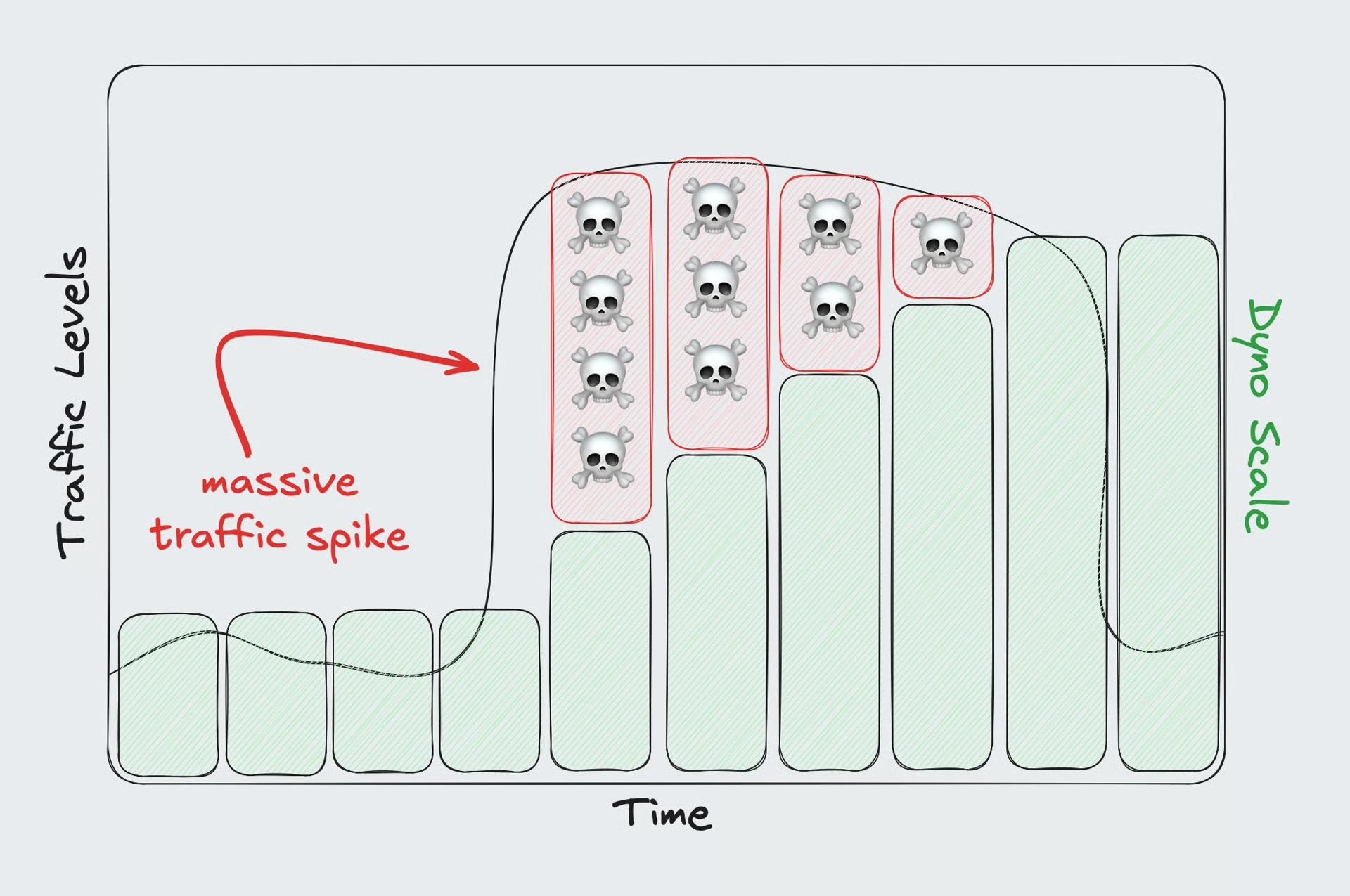
Most autoscalers are reactive—they respond to traffic after it spikes. That’s usually fine… until it’s not.
If your app gets hit with big surges of traffic all at once, even the fastest queue-time autoscaler might not spin up capacity in time to avoid slowdowns or timeouts.
One week until #railsconf! The whole Judoscale team will be there with... kazoos?
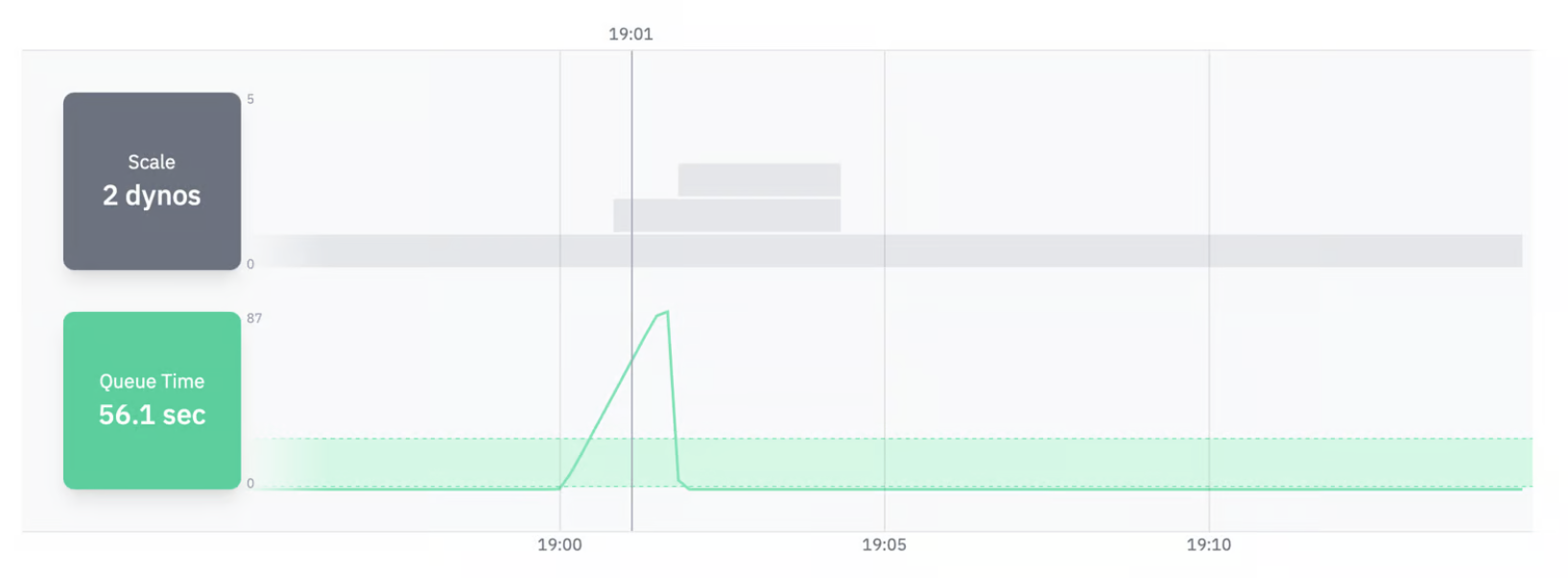
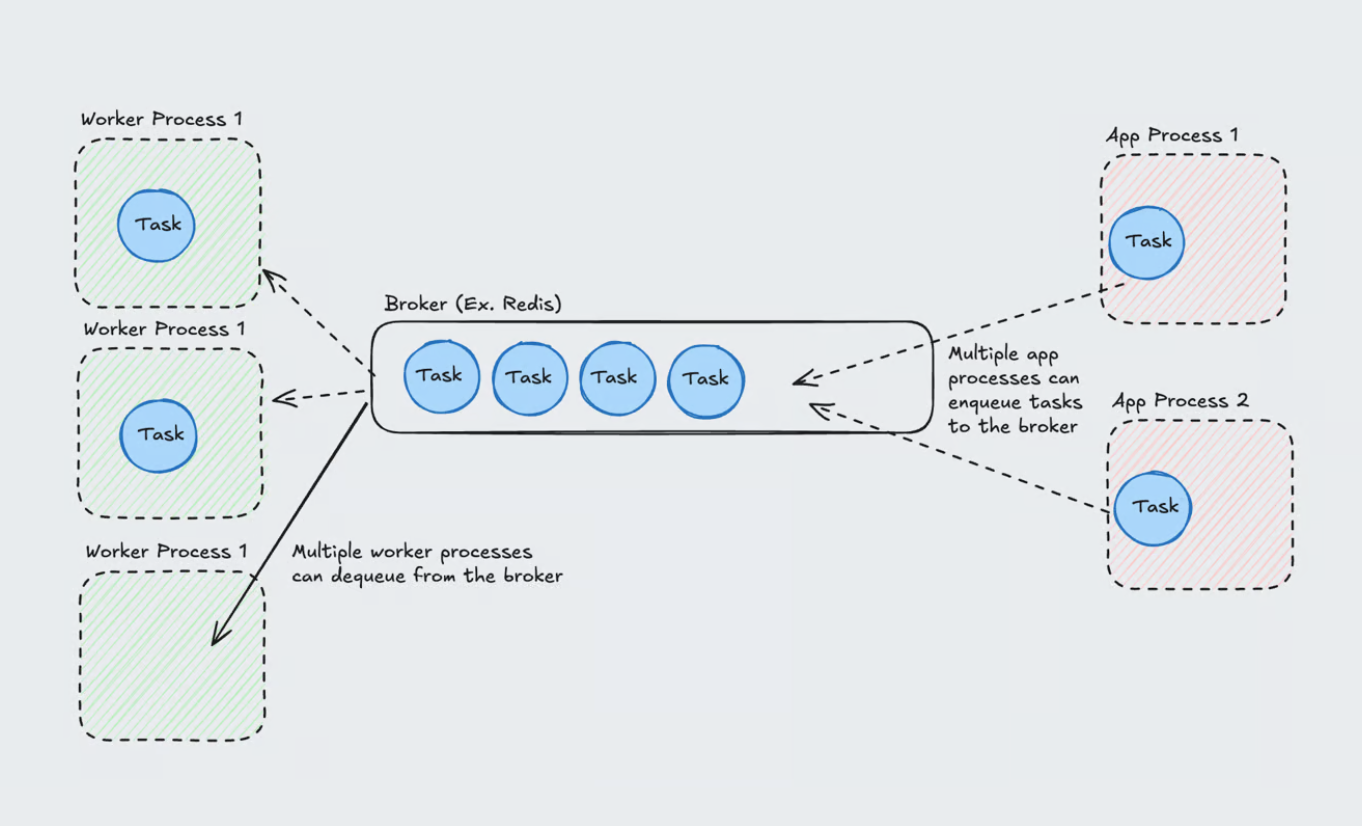
Python task queue pro-tip: Autoscale based on queue latency, not CPU!
Your task queue can back up without CPU spikes, leaving you in the dark.
Check out Jeff's full Celery & RQ comparison here:
https://judoscale.com/blog/choose-python-task-queue
Choosing a Python task queue? Jeff Morhous compared Celery vs RQ:
🧠 Celery: Feature-rich but complex
🚀 RQ: Simple & easy to deploy
Jeff's advice: Most apps do fine with RQ until they need more horsepower. Then consider making the switch to Celery.
🔌 Big news! Custom platform integrations coming soon to Judoscale! Create your own adapter, keep your infrastructure, get all the autoscaling magic.
Message me if you want early access.
What platform would you connect with?
This behavior is confusing at first, but it's actually super cool once you wrangle it.
And with autoscaling in place, we don't really need to worry about it. New machines are being created with fresh burst balances when needed, spreading the load allowing balances to rebuild.
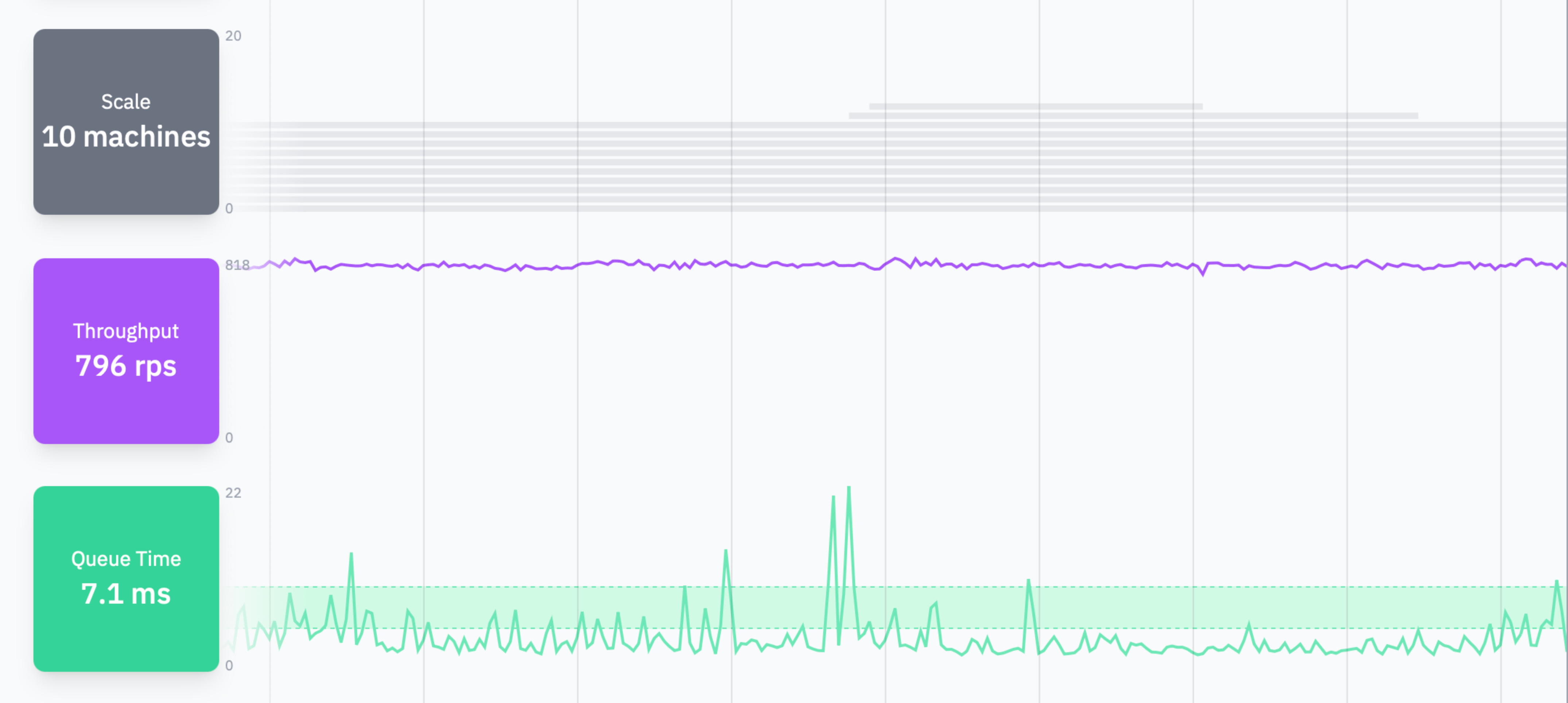
But why do they perform so well at first, only to fall apart after a bit?
It's the bursting!
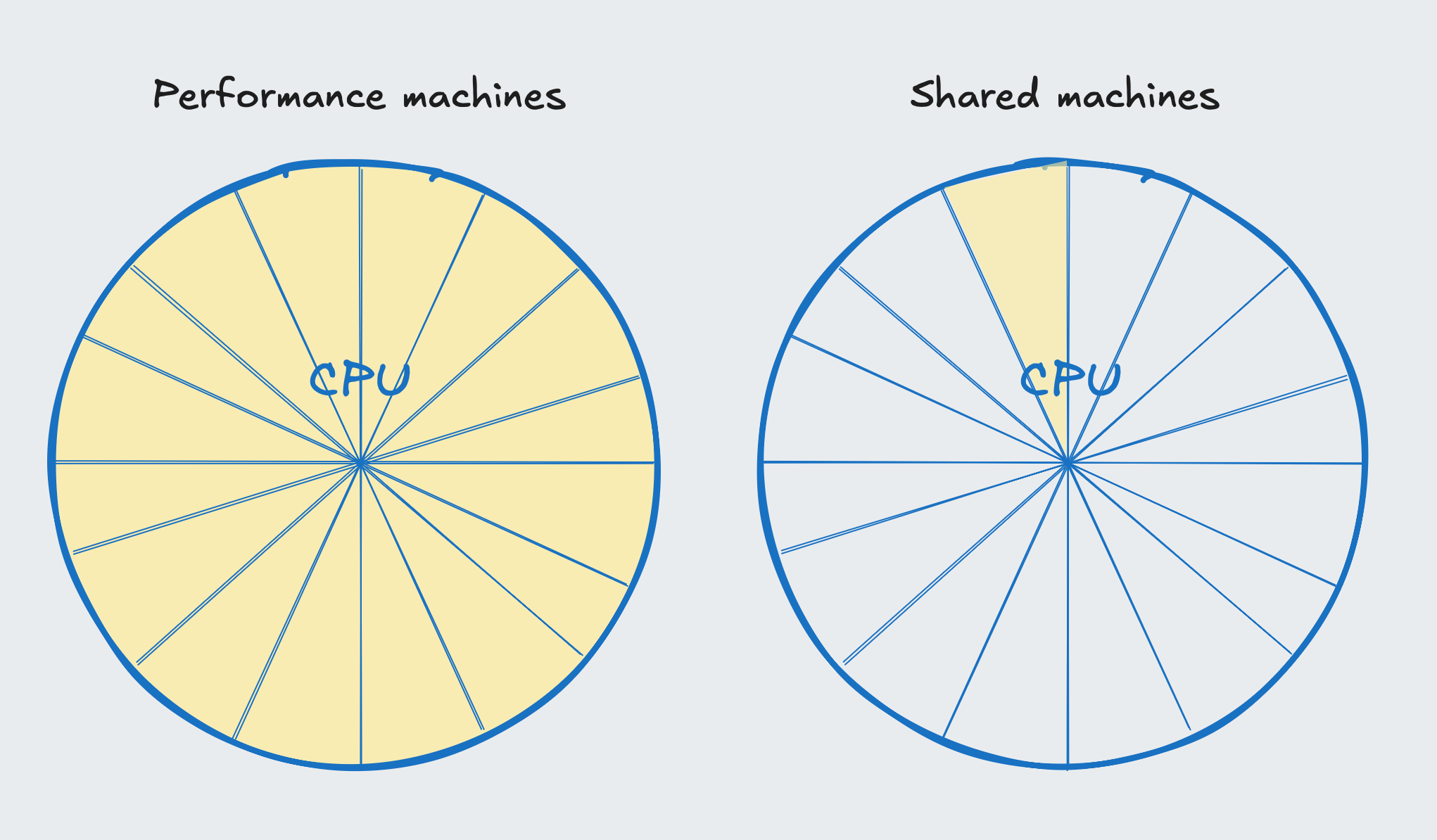
Shared machines have a "burst balance" where they can use 100% CPU. Once the balance is depleted, CPU is throttled to 1/16.
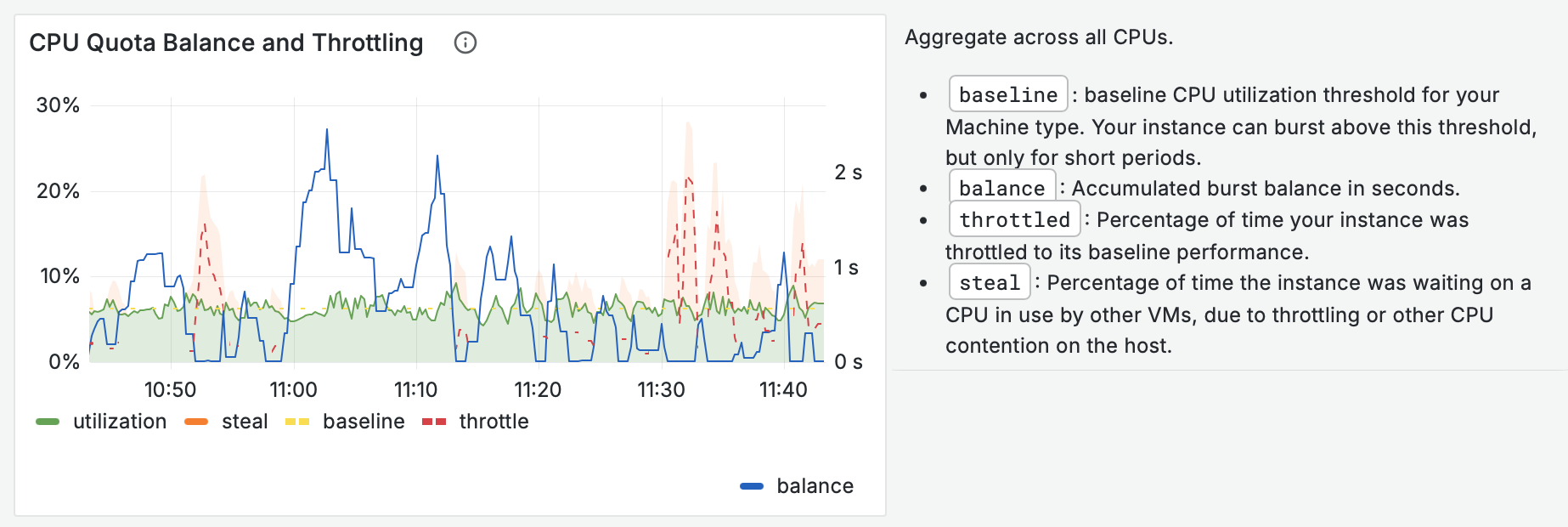
I finally answered my questions about shared CPUs on https://Fly.io:
- How are they so cheap?
- Why do I need so many of them?
- Why does perf tank after 10 minutes?
Turns out it's well-documented: "shared" machines only get 1/16 of each CPU!
⚠️ It's a mistake to ignore these configs. The defaults are NOT what you want.
EXAMPLE: A 4-process, single-threaded web server should use a hard limit of 4 since that's the max concurrent requests. A soft limit of 1-2 would help route requests to less busy machines.
This is the exact config I landed on last week, and it's been a night-and-day difference with our 800 RPS app running on Fly. 🚀
Learn more: https://fly.io/docs/reference/configuration/#services-concurrency
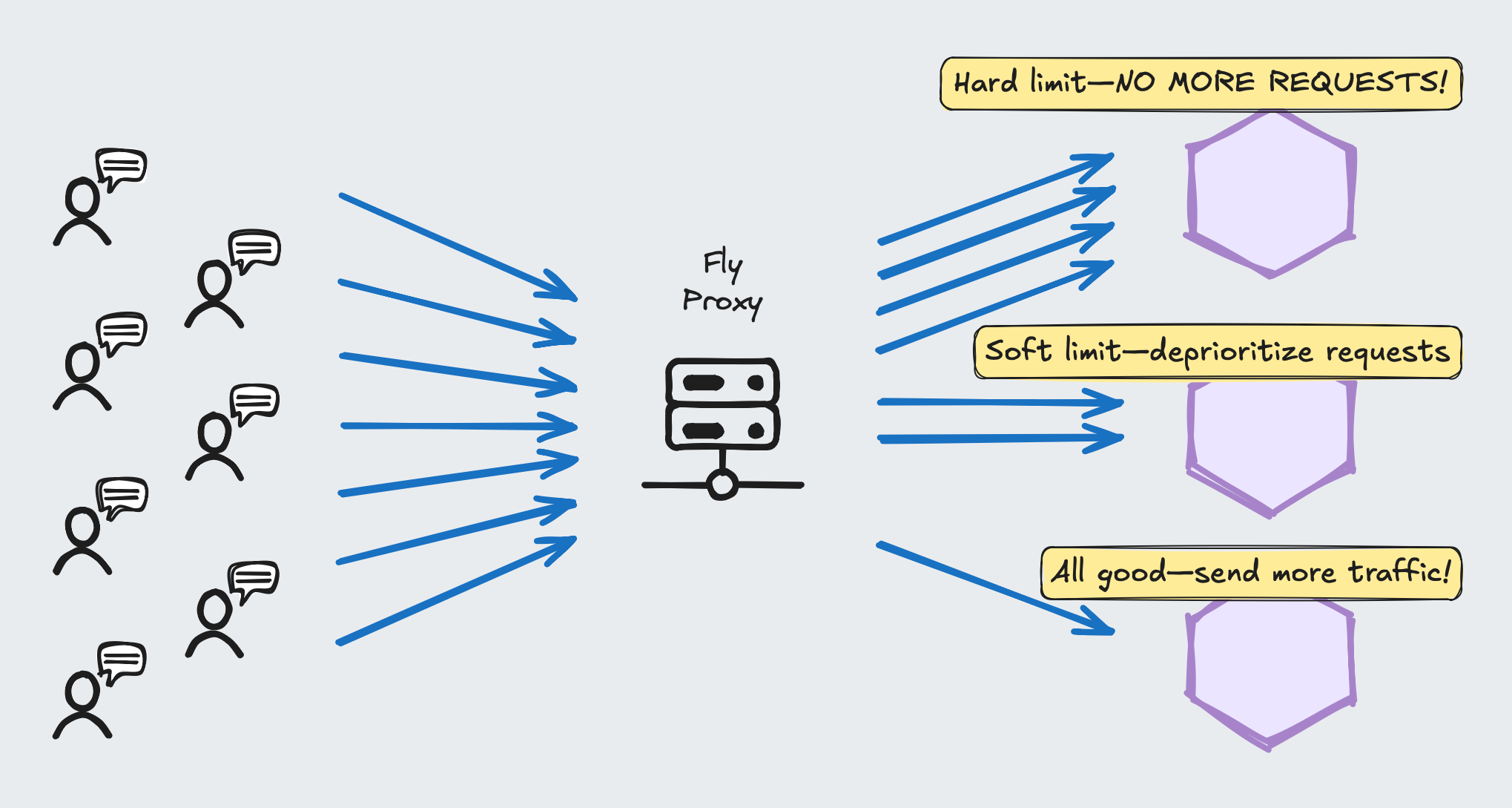
Last week I dug into HTTP routing behavior on https://Fly.io, and it's so cool!
Unlike random routing on platforms like Heroku, Fly can intelligently route requests to machines based on a load. Here are the configs you need to know...

🧸 soft_limit: Traffic to a given machine is deprioritized when the soft limit is met.
🪨 hard_limit: Traffic to a given machine is STOPPED when the hard limit is met.
🔧 concurrency type: How concurrency is measured. Should be "requests" for web servers. NOT THE DEFAULT!
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst