Was 2024 the year of datasets? Is 2025 the year for community-built datasets?
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363
📖🤗 Machine learning Librarian at Hugging Face
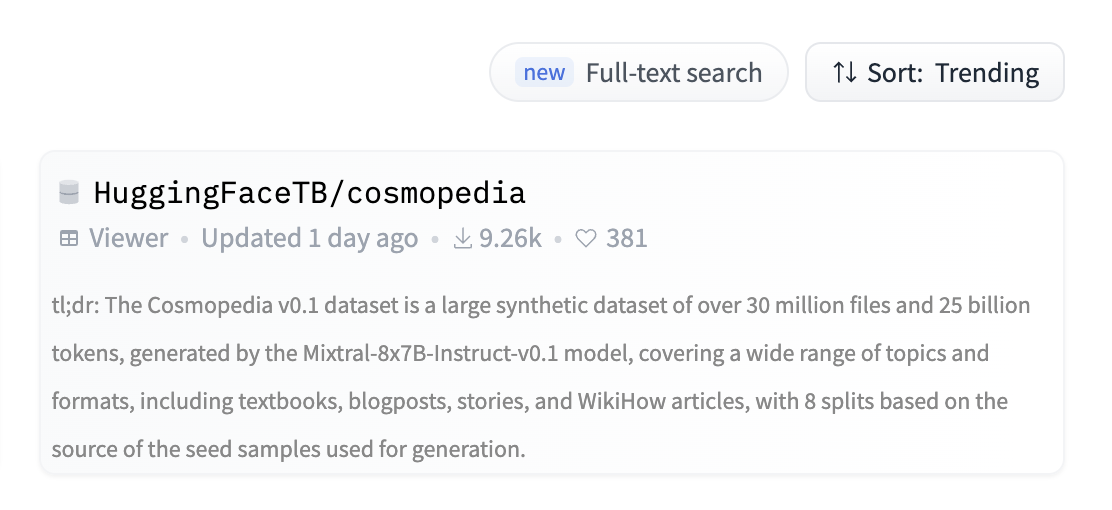
Was 2024 the year of datasets? Is 2025 the year for community-built datasets?
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363
Researchers: Want your ML datasets to have more impact? Share them on @huggingface Hub!
✨ Benefits:
• Visibility in the ML community
• Interactive data viewer
• Support for TB-scale datasets
• Integration with @DataPolars @pandas_dev @duckdb and more
https://huggingface.co/blog/researcher-dataset-sharing
ColPali is revolutionizing multimodal retrieval. Can we make it even more effective with domain-specific fine-tuning?
Check out my latest blog post, where I create a dataset for fine-tuning a ColPali model for a new domain using an open Vision Language Model.
https://danielvanstrien.xyz/posts/post-with-code/colpali/2024-09-23-generate_colpali_dataset.html


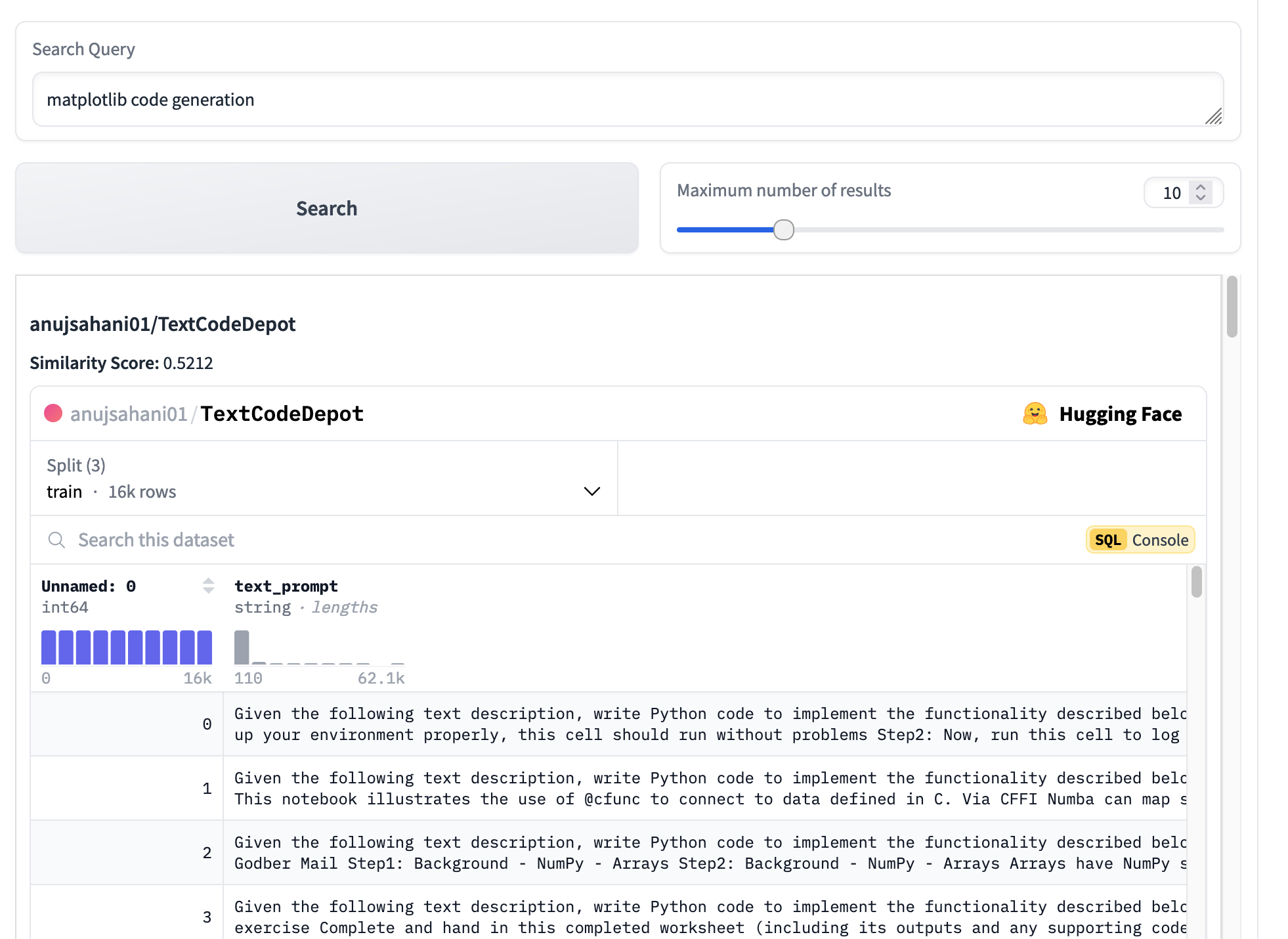
Can we search for datasets on the @huggingface Hub based on their content?
> Some datasets lack good documentation 😢
> The dataset viewer preview offers a wealth of information
🤔 How about: query -> dataset based on structure content?
Check out V1: https://huggingface.co/spaces/librarian-bots/huggingface-datasets-semantic-search
You can help improve this project by rating synthetic user search queries for hub datasets. If you have a @huggingface login, you can start annotating in @argilla_io in < 5 seconds here: https://davanstrien-my-argilla.hf.space/dataset/1100a091-7f3f-4a6e-ad51-4e859abab58f/annotation-mode
I need to do some tidying, but I'll share all the code and in-progress datasets for this soon!
Almost ready: search for a @huggingface dataset on the Hub from information in the datasets viewer preview!
Soon, you can find deep-cut datasets even if they don't have a full dataset card (you should still document your datasets!)
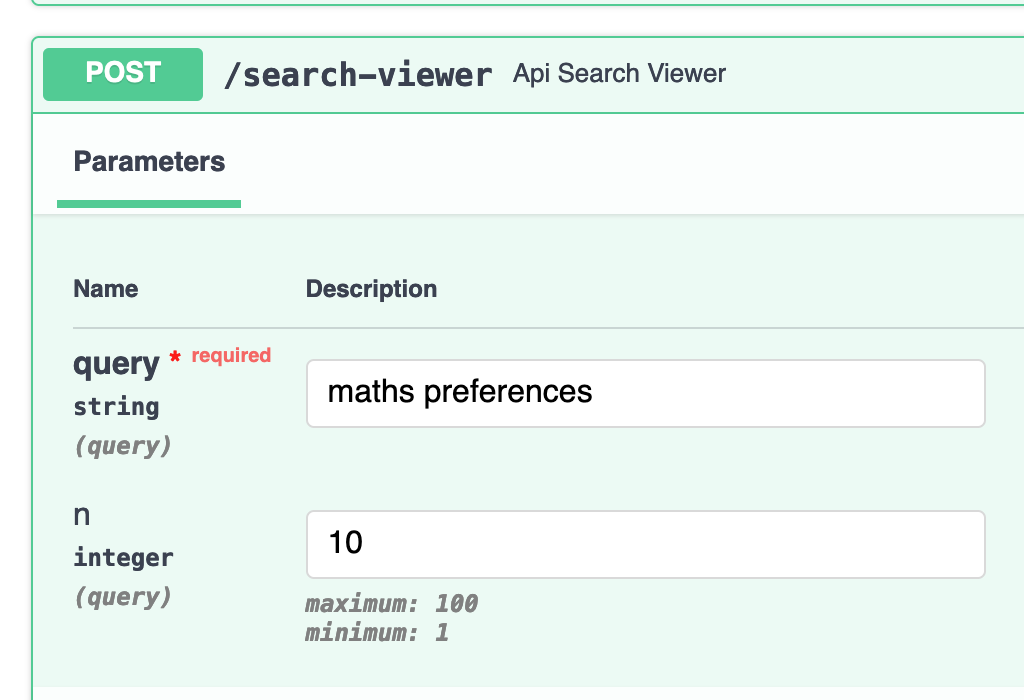
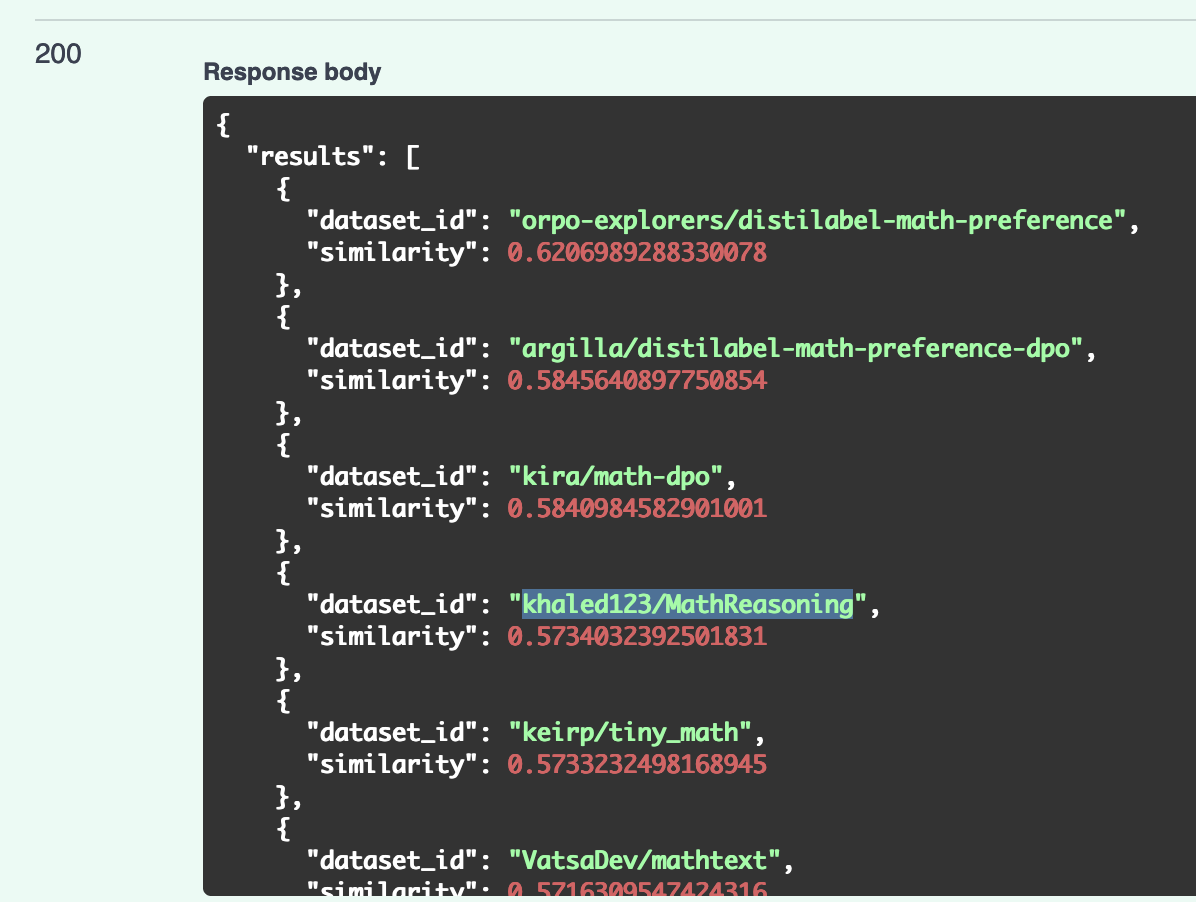
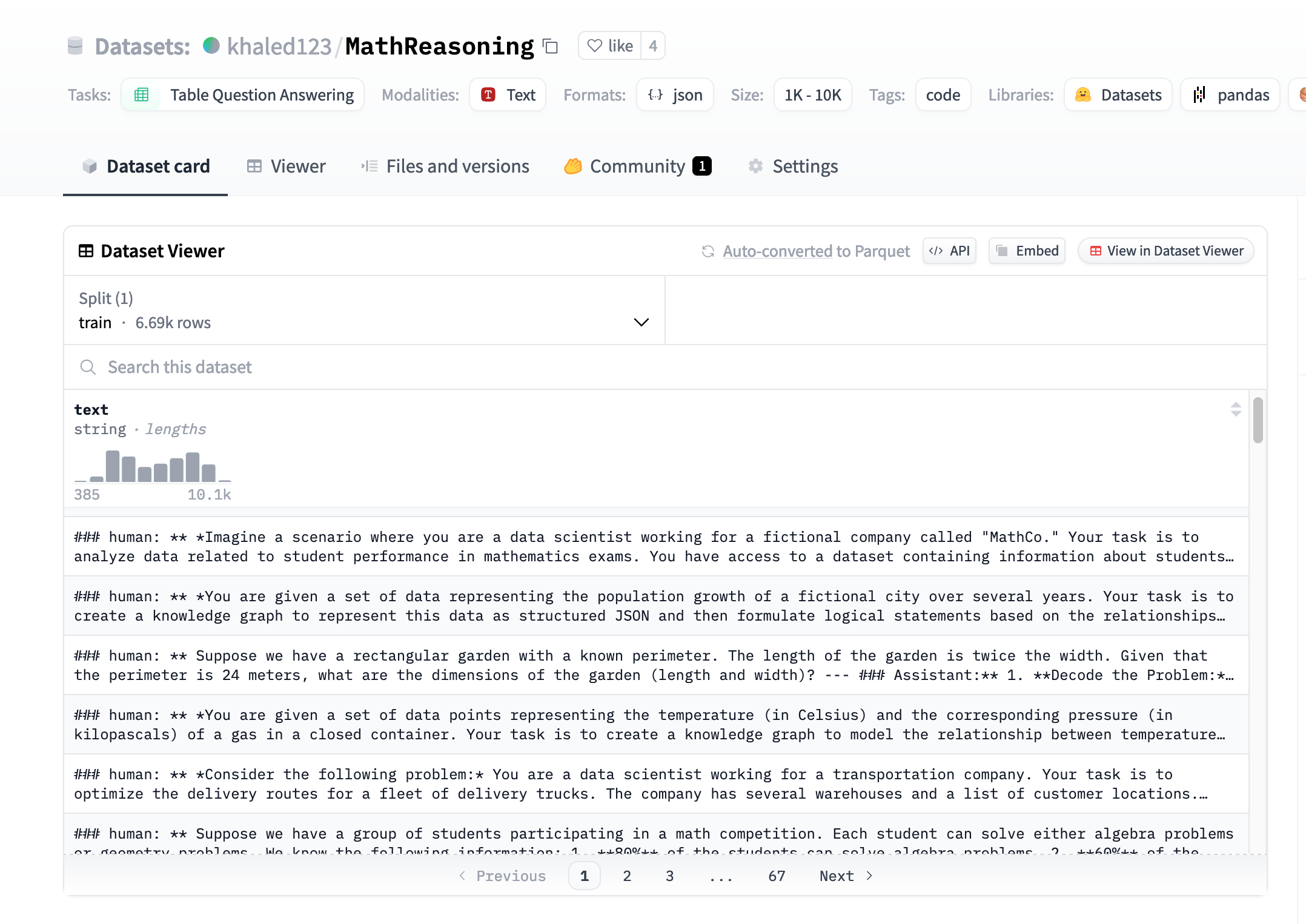
The @huggingface's Semantic Dataset Search is back in action! Find similar datasets by ID or do a semantic search of dataset cards.
Give it a try:
https://huggingface.co/spaces/librarian-bots/huggingface-datasets-semantic-search
@arnicas Occasionally the books sounds interesting but often the blurbs are not very good. Think LLMs are still very lacking in this kind of task tbh.
Is your summer reading list still empty? Curious if an LLM can generate a book blurb you'd enjoy and help build a KTO preference dataset at the same time?
A demo using @huggingface Spaces and @gradio to collect LLM output preferences: https://huggingface.co/spaces/davanstrien/would-you-read-it
SPIQA from @Google is a large-scale question-answering dataset centred on figures, tables, and text paragraphs from scientific research papers in various computer science domains.
https://huggingface.co/datasets/google/spiqa

HelpSteer2 from @nvidia is an open-source dataset to train top-performing reward models!
- 21,362 samples with annotated attributes
- Attributes: Helpfulness, Correctness, Coherence, Complexity, Verbosity
- Multi-turn prompts
- 88.8% on RewardBench
https://huggingface.co/datasets/nvidia/HelpSteer2
Created an "Awesome Synthetic Datasets" list in my ongoing quest to learn more about building synthetic datasets using large language models. Currently includes important tools, datasets, and papers.
Check it out here: https://github.com/davanstrien/awesome-synthetic-datasets
Translations from 56 contributors, based on a dataset by 314 community members! These translations will facilitate the creation of evaluations, experimentation with SPIN, building DPO datasets, and more. Interested in contributing to datasets? https://github.com/huggingface/data-is-better-together
Who wants to be 100!?
https://github.com/huggingface/data-is-better-together
As part of the Multilingual Prompt Evaluation Project (MPEP), we are now automatically exporting the @argilla_io datasets to the @huggingface Hub. We have more than 15 active community-led translation efforts collaborating to enhance datasets for various languages. ❤️
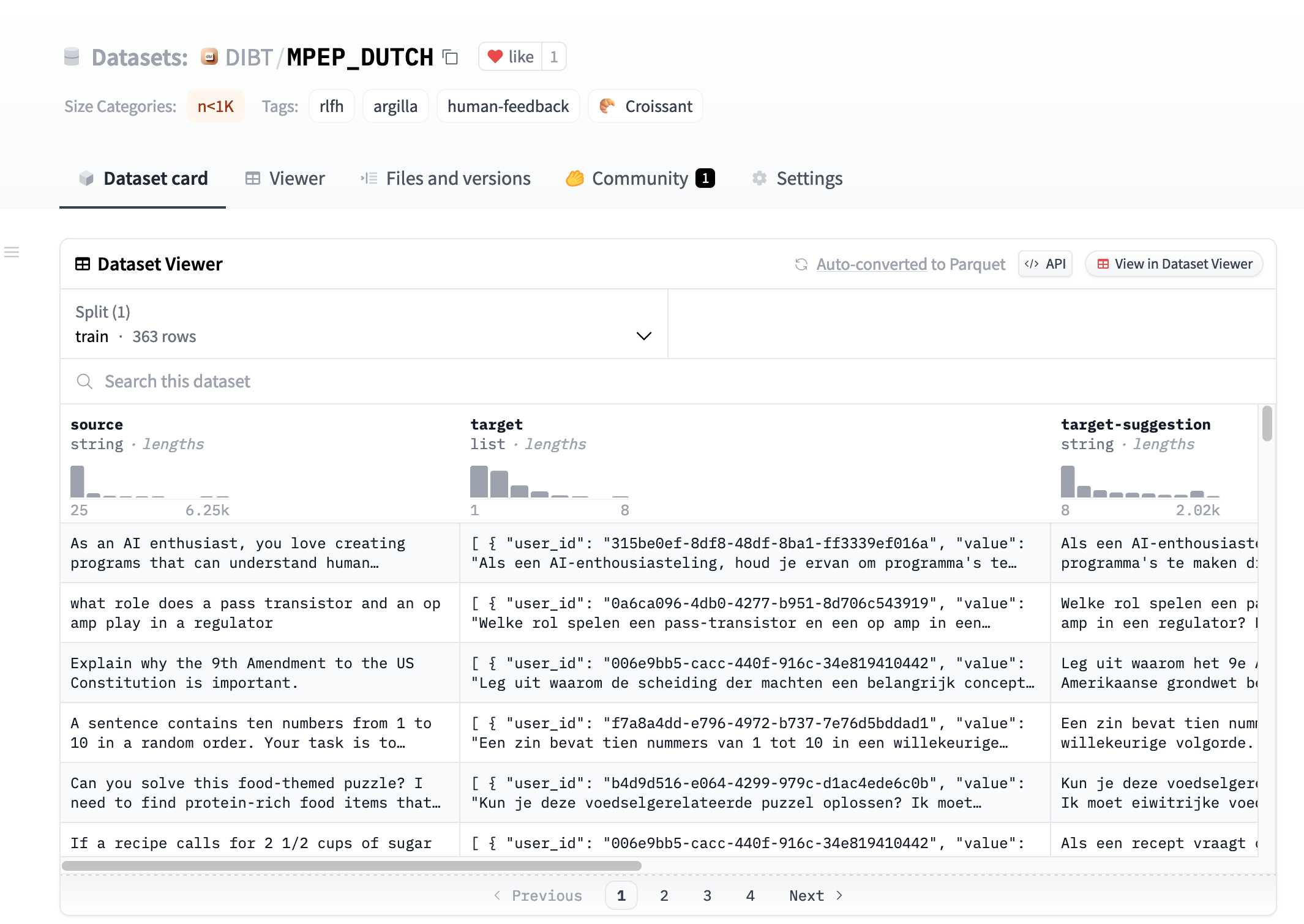

Big thanks to @davidbstein1957 and @ignacio_at_nlp for working on this 🤗
VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs: https://huggingface.co/datasets/xcodemind/vision2ui
Experimenting with TL;DR summaries for @huggingface datasets using a Chrome plugin.