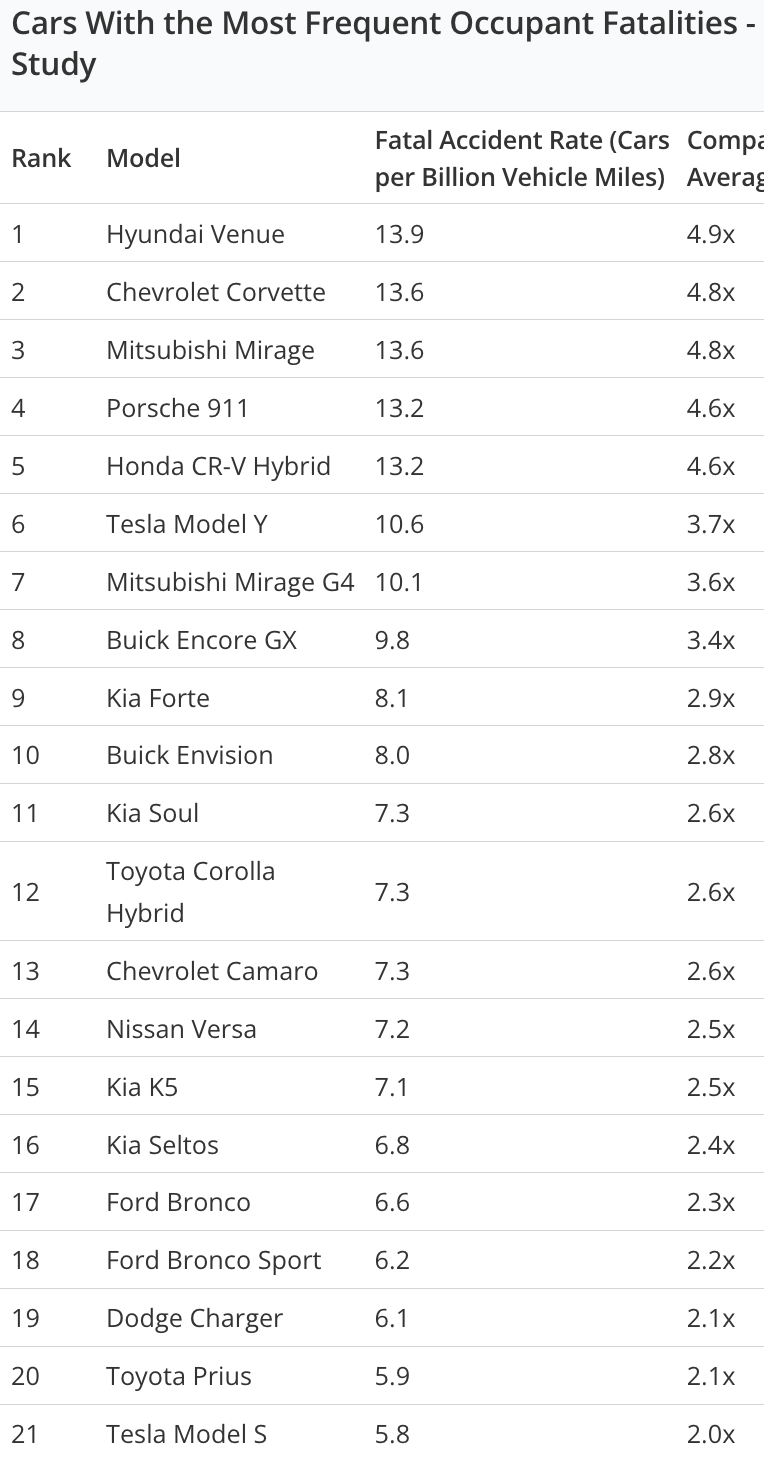
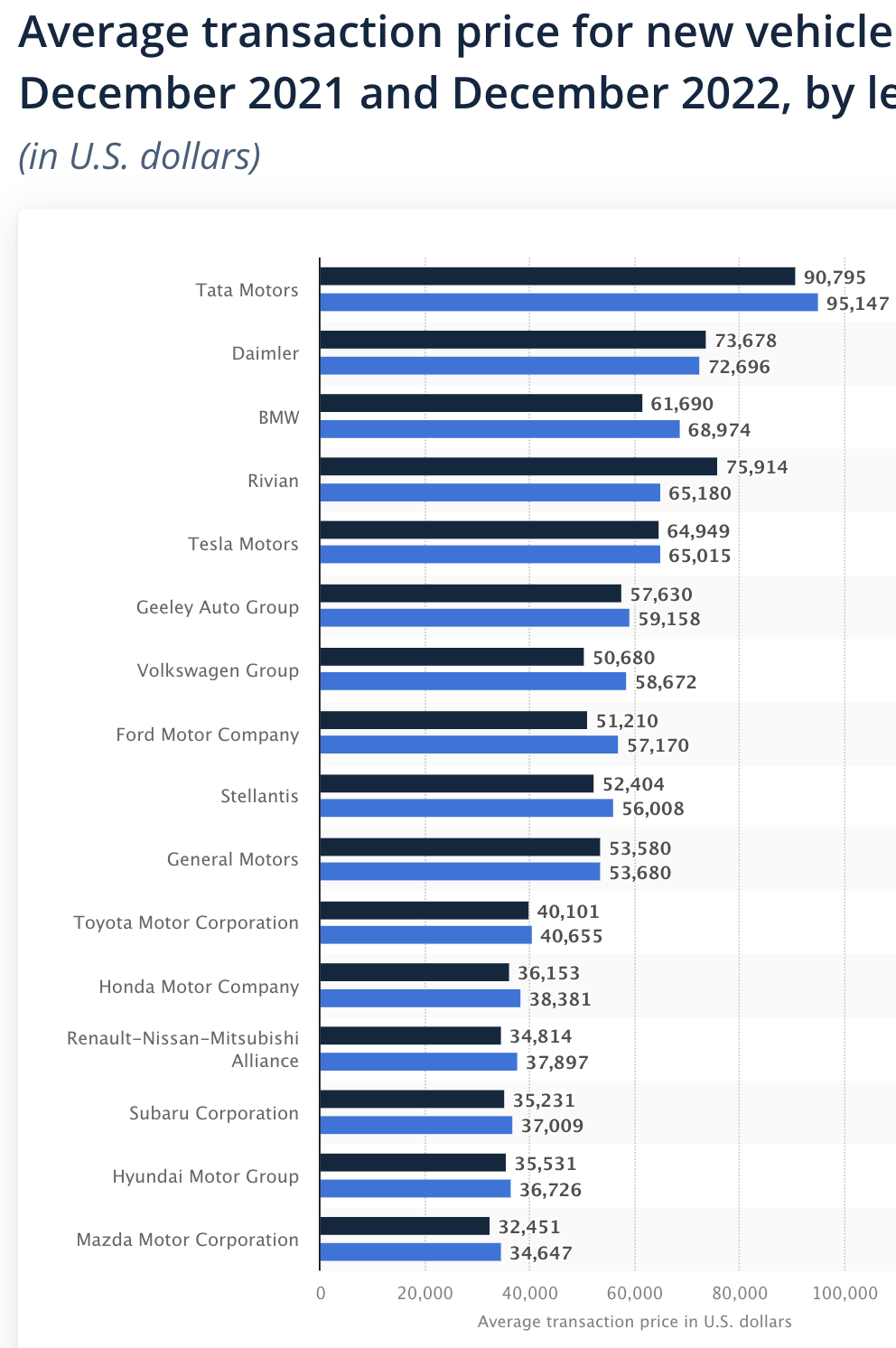
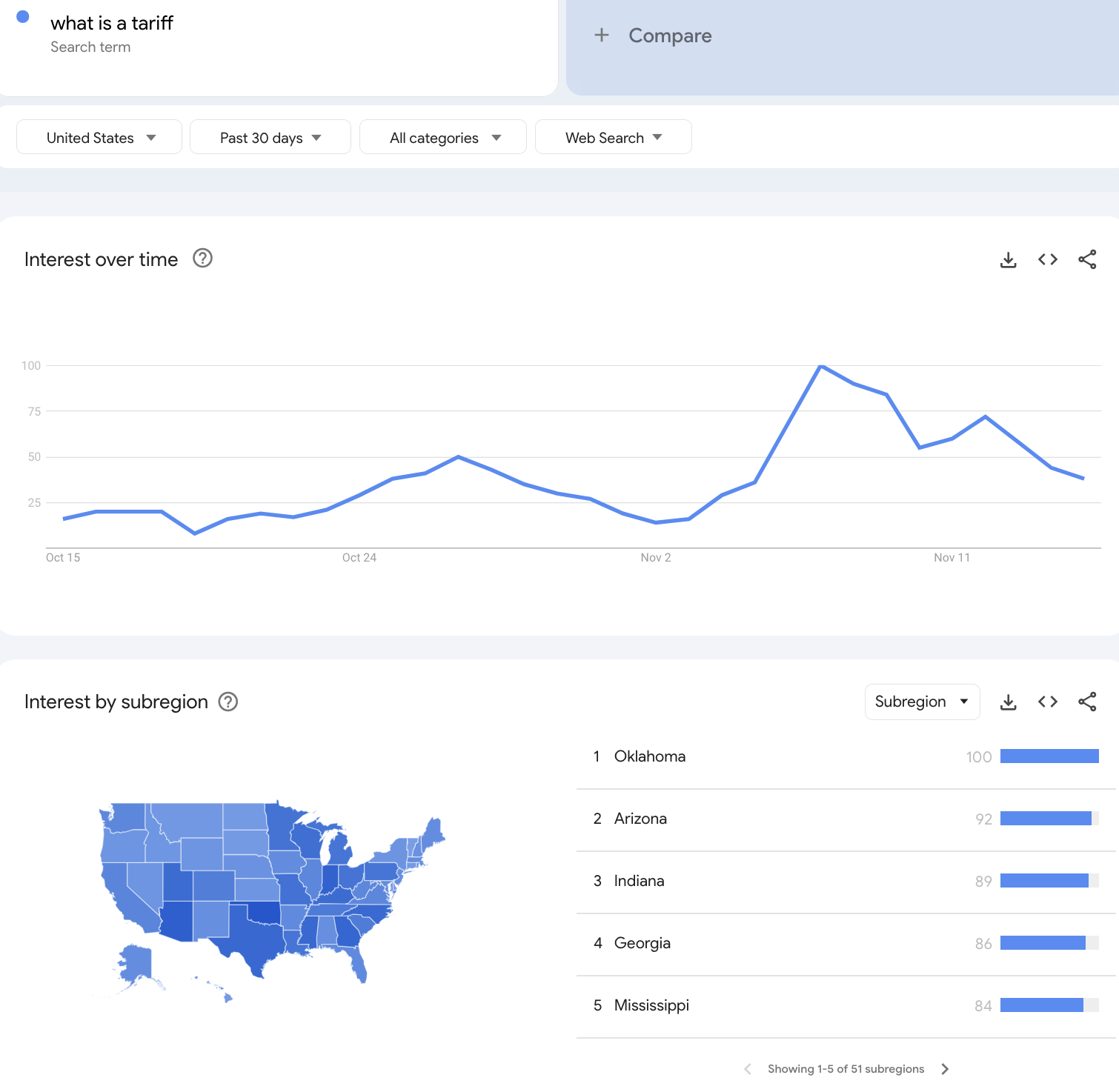
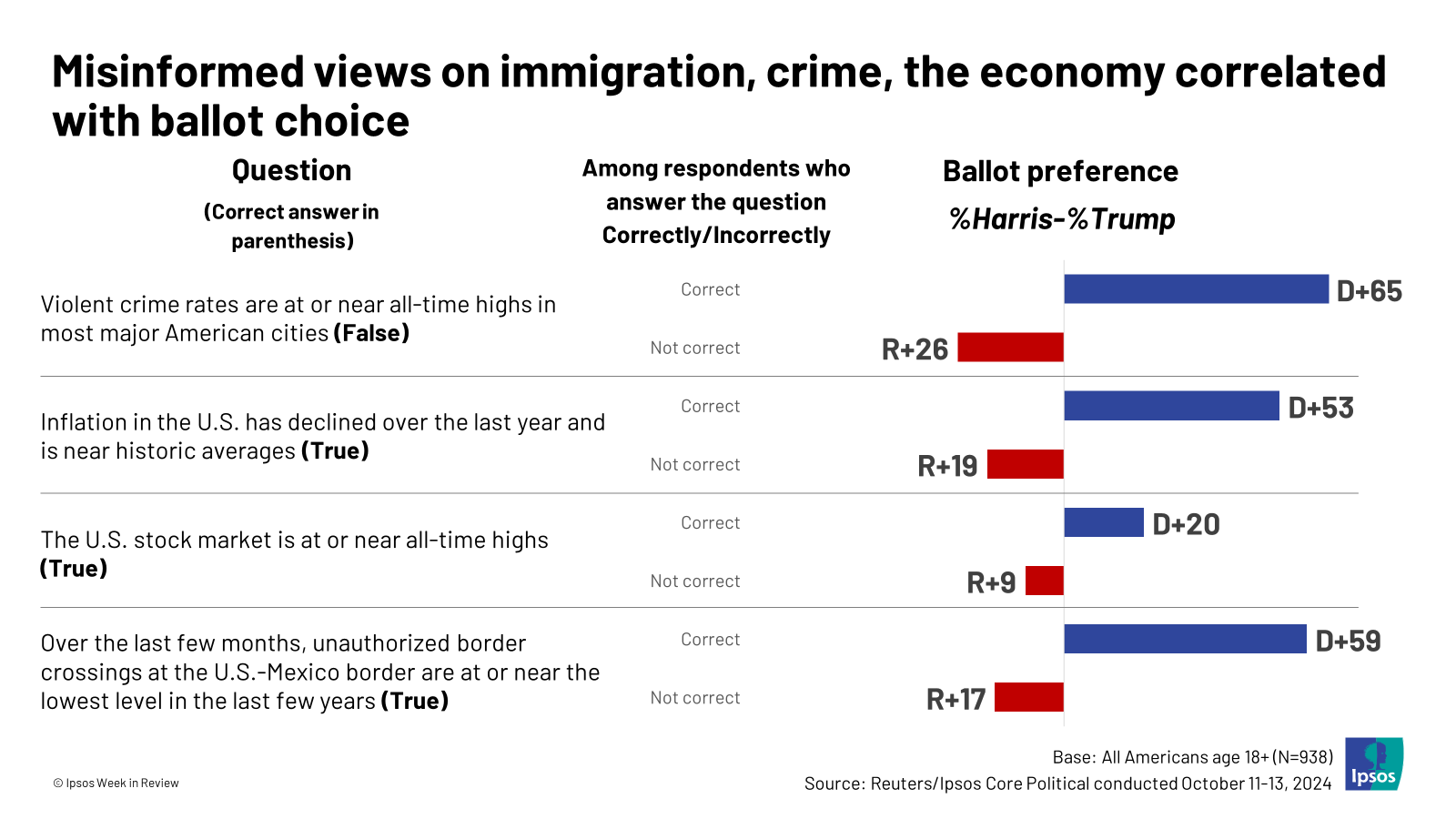
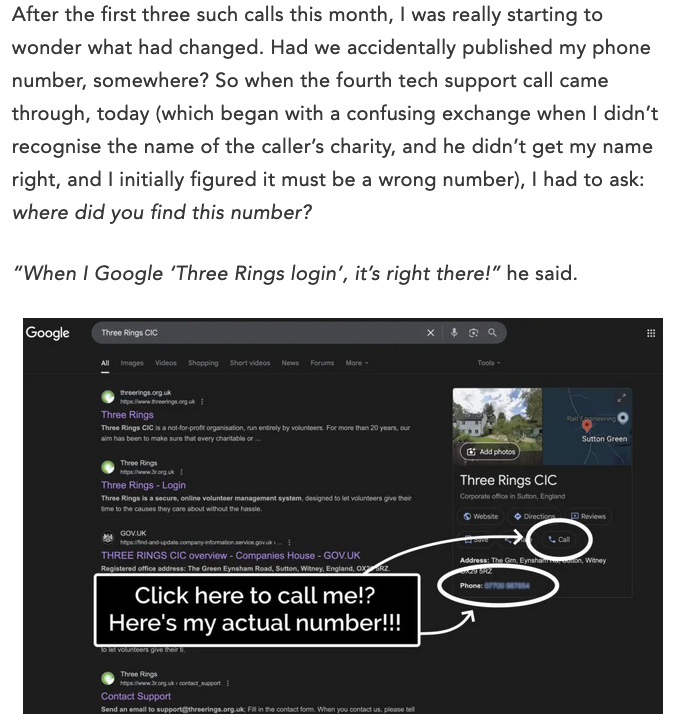
Interesting story about Google publishing someone's phone number on searches for them when they gave the number to Google for account verification/security:
https://danq.me/2025/05/21/google-shared-my-phone-number/
Reminds me of the time a company I worked for (AFAIK) accidentally used phone numbers obtained the same way for ad targeting and got fined $150M
![19. You have a Sandy Bridge processor. You measure the memory latency and find that a read from memory takes 60ns. We have the following loop, where ITERS is some large number
for (size_t i = 0; i < ITERS; i += CACHE_LINE_SIZE) {
cnt += buf[i];
}
A. What parameters do we need to know to guess how long this loop will take to run (assuming everything is warmed up and/or we're observing some kind of steady state behavior) and what are the parameters? [answer at the end to avoid spoilers, feel free to skip to the end if you don't want to search up these parameters]
B. How fast does the loop run?
C. Without trying it out, how accurate do you think ChatGPT, Gemini, etc., are at answering this question?](https://files.mastodon.social/media_attachments/files/114/414/397/986/082/365/original/1280841fcfce4e60.png)

![antirez 3 hours ago | next [–]
About "people still thinking LLMs are quite useless", I still believe that the problem is that most people are exposed to ChatGPT 4o that at this point for my use case (programming / design partner) is basically a useless toy. And I guess that in tech many folks try LLMs for the same use cases. Try Claude Sonnet 3.5 (not Haiku!) and tell me if, while still flawed, is not helpful.
But there is more: a key thing with LLMs is that their ability to help, as a tool, changes vastly based on your communication ability. The prompt is the king to make those models 10x better than they are with the lazy one-liner question. Drop your files in the context window; ask very precise questions explaining the background. They work great to explore what is at the borders of your knowledge. They are also great at doing boring tasks for which you can provide perfect guidance (but that still would take you hours). The best LLMs (in my case just Claude Sonnet 3.5, I must admit) out there are able to accelerate you.
duped 2 hours ago | parent | prev | next [–]
> Try Claude Sonnet 3.5 (not Haiku!) and tell me if, while still flawed, is not helpful.
It's not as helpful as Google was ten years ago. It's more helpful than Google today, because Google search has slowly been corrupted by garbage SEO and other LLM spam, including their own suggestions.
mvkel 1 hour ago | parent | next [–]
I'm surprised at the description that it's "useless" as a programming /...](https://files.mastodon.social/media_attachments/files/113/795/447/771/216/740/original/442392981fe24725.png)