Started a list of open-source LLMs with commercial licenses so you can fine-tune your own applications. Contributions welcome! 🙏
Eugene Yan
Building #recsys & #machinelearning systems at Amazon.
Writing at http://ApplyingML.com & http://eugeneyan.com.
Husband. Pawrent. Operator-Angel. Stoic.
Figuring out what happens next.
I wrote about 9 design patterns in machine learning systems, including HITL, Hard Mining, Cascade, Data Flywheel, Rules Layer, etc.
Each pattern lists their pros & cons, with several industry examples.
What other patterns have you seen? Please share! 🙏
Fun, interactive visualization of the data in Google's C4 (Colossal Clean Crawled Corpus) that's heavily used in LLM training.
Broken down by category and the top sites in each category.
https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/
I had forgotten about this but it looks like my message-in-a-bottle got picked up by the web crawlers.
Also shows how it's not too difficult to add data into a search index that gets blended into an LLM's output. More in Simon's post here: https://simonwillison.net/2023/Apr/14/worst-that-can-happen/
A few more that I'll cover in a write-up:
• Aggregate raw data once: To reduce compute cost
• Evaluate before deploy: For safety and reliability
• Hard mining: To better learn difficult instances
What other design patterns or industry examples are there? Please share!
6. Business Rules: Adding logic or constraints based on domain knowledge and/or business requirements to augment or adjust the output of ML models
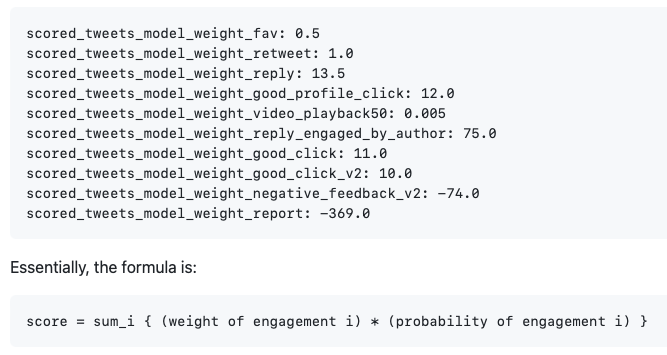
Twitter has various hand-tuned weights when predicting engagement probabilities: https://github.com/twitter/the-algorithm-ml/tree/main/projects/home/recap
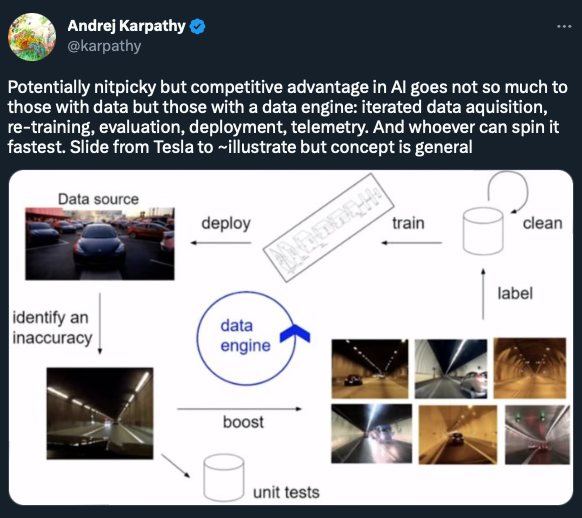
5. Data flywheel: Positive feedback loop where more data improves ML models, which leads to more users and data.
Tesla collects data via cars, finds and labels errors, retrains models, and then deploys to their cars which gather more data.
4. Data Augmentation: Synthetically increase the size and diversity of training data to improve model generalization and reduce overfitting.
DoorDash varied sentence order and randomly removed information such as menu category: https://doordash.engineering/2020/08/28/overcome-the-cold-start-problem-in-menu-item-tagging/

3. Human-in-the-loop: Collecting labeled data from users, annotation services, or domain experts.
Stack Exchange lets users flag posts as spam, and LinkedIn lets users report messages as harassment: https://engineering.linkedin.com/blog/2020/fighting-harassment
Recently, LLMs are applied too: https://twitter.com/eugeneyan/status/1640530851489259522
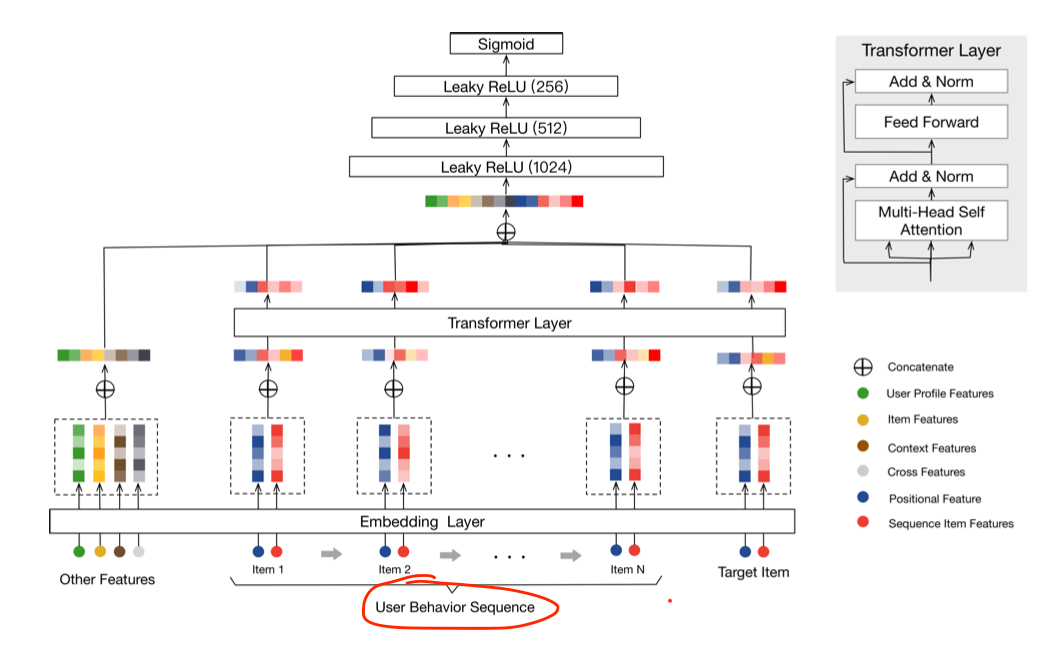
2. Reframing: Redefine the original problem, target, or input to make the problem easier to solve.
Sequential recsys reframed the paradigm from co-occurrence (matrix factorization) to predict-the-next-event (e.g., transformers).
Alibaba's BST: https://arxiv.org/abs/1905.06874
What are some design patterns in machine learning systems?
Here are a few I've seen:
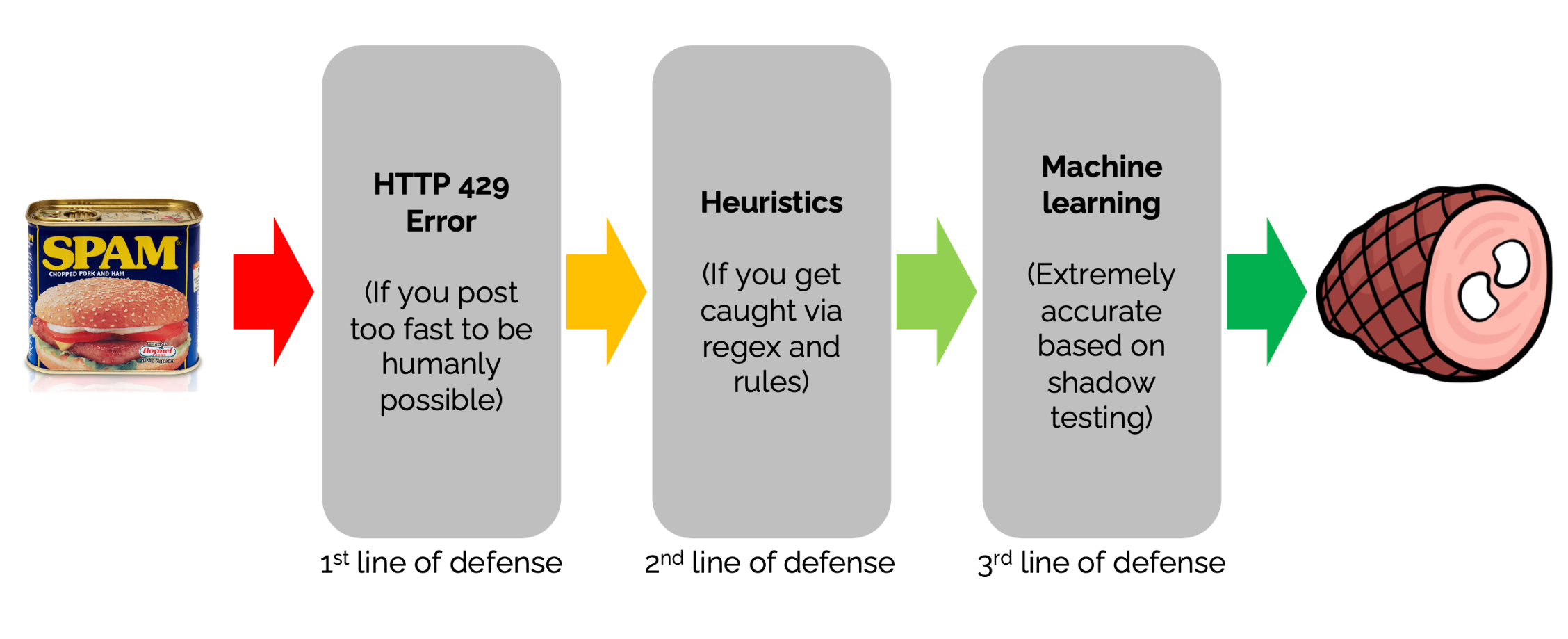
1. Cascade: Break a complex problem into simpler problems. Each subsequent model focuses on more difficult or specific problems.
Stack Exchange has a cascade of defenses against spam: https://stackoverflow.blog/2020/06/25/how-does-spam-protection-work-on-stack-exchange/
Over the past few weekends, I've experimented with using LLMs to build a simple assistant.
Here's a write-up of what I built, how I built them, and their potential. Also, some shortcomings with embedding retrieval, with solutions from search & recsys.
And as this thread comes to an end,
I leave you with other gifts, from our LLM friend.
It all started with getting it to tell the time,
With a little quirk, with a little rhyme.
It can also pose as a hackernews troll,
Slinging mean comments, and being quite an a$$hole.
You'll find that it can be quite witty,
Making up fake quotes from celebrity.
While some use LLMs to disrupt industries and more,
Others build ChatGPT plugins, pushing boundaries galore.
Yet here I am with my Raspberry Pi loose,
Using LLMs to explain headlines via Dr. Seuss.
Correction: I guess all we can say is that it now (only) uses the actual memory required instead of 2x memory required.
Still an awesome improvement nonetheless!
> "The peculiarity here is that tools like htop were reporting the improvement as being an 8x improvement, which is interesting, because RAM use is only 2x better due to my change."
Also shows the importance of valid measurements. And evaluating numbers with some skepticism.
This is why CS fundamentals continue to be crucial: LLaMA 30B only needs 4gb of memory if we use mmap().
Not sure why this works but one reason could be that 30B weights are sparse. Thus, lazy loading the fraction of needed weights reduces memory usage.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst