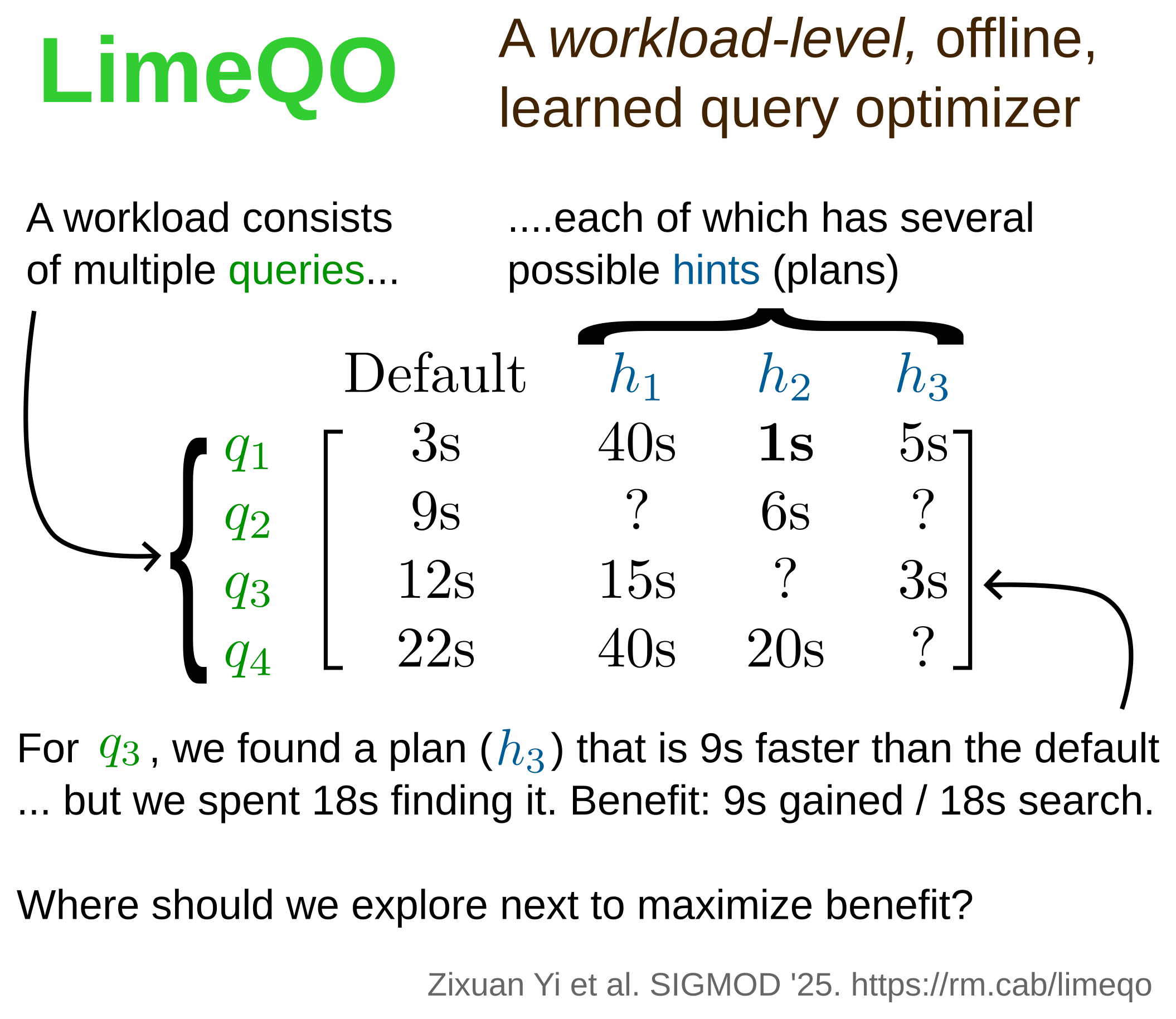
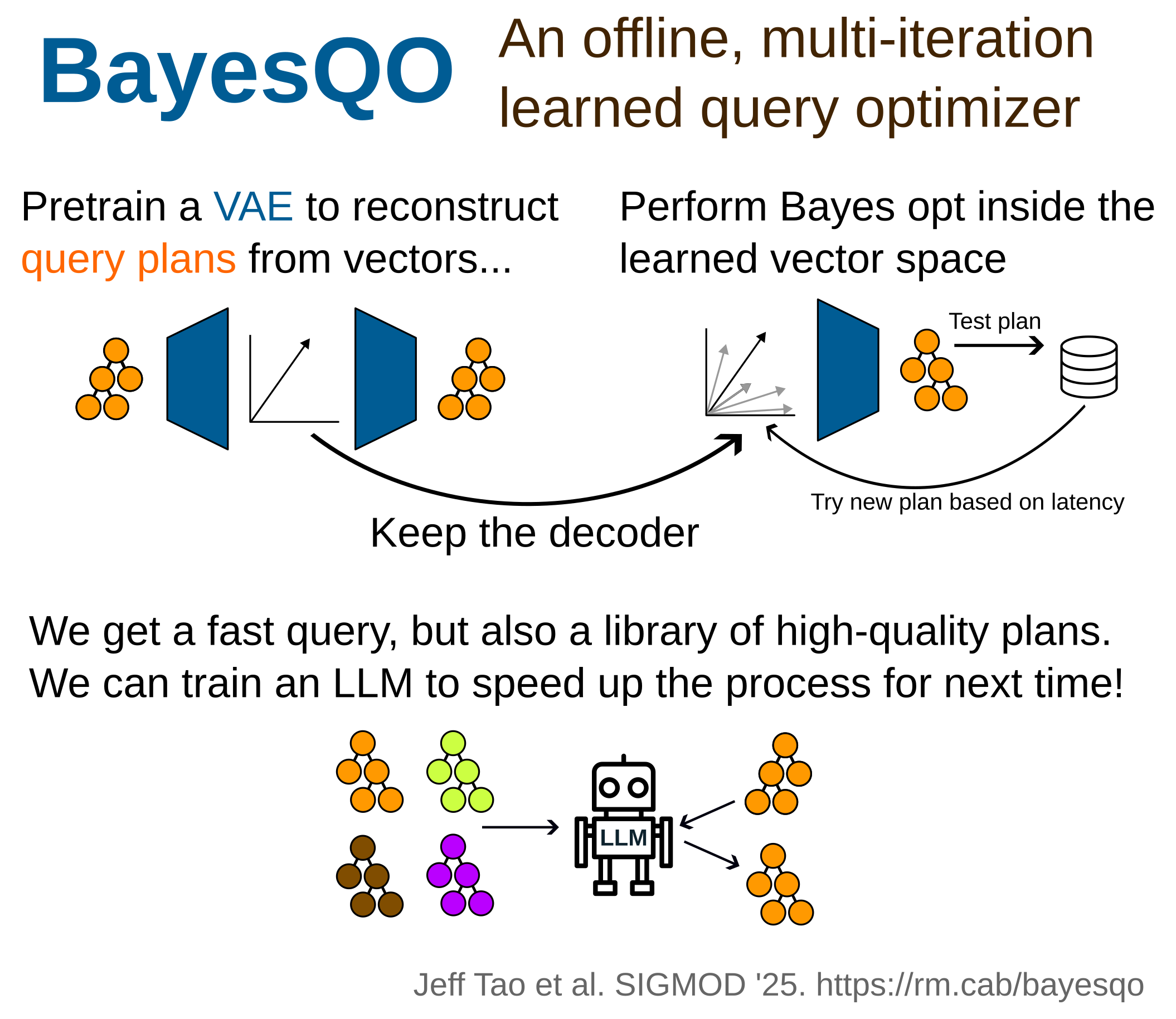
@nholzschuch Absolutely -- emails are tricky since many conferences require the email listed on a paper to match your institution. But some institutions don't give permanent email addresses, as you said.
A good workaround I've found is creating a mail alias at the institution that can point to your institutional address while you are there, and can be repointed to your personal email afterwards.
But really, academic institutions need to support lifelong email addresses, or at least forwarding, for scientists. A new subdomain could be used to avoid polluting the undergrad email namespace.