It did not come from nowhere. @xiyang set the tone, passing the torch to the current students. He epitomised technical excellence + intellectual generosity. Thank you, Xi 🙏
Steve Blackburn
Computer scientist, researcher, dad, husband, runner, hiker, collector of garbage.
@wingo Thanks Andy.
What’s in the water? Just a wonderfully talented and intellectually generous bunch of students. In particular there’s a great culture of generosity in the lab that @caizixian and other students have built. That culture encourages talented undergrads like Claire to join and flourish. I’m very grateful.
Steve Blackburn boosted:
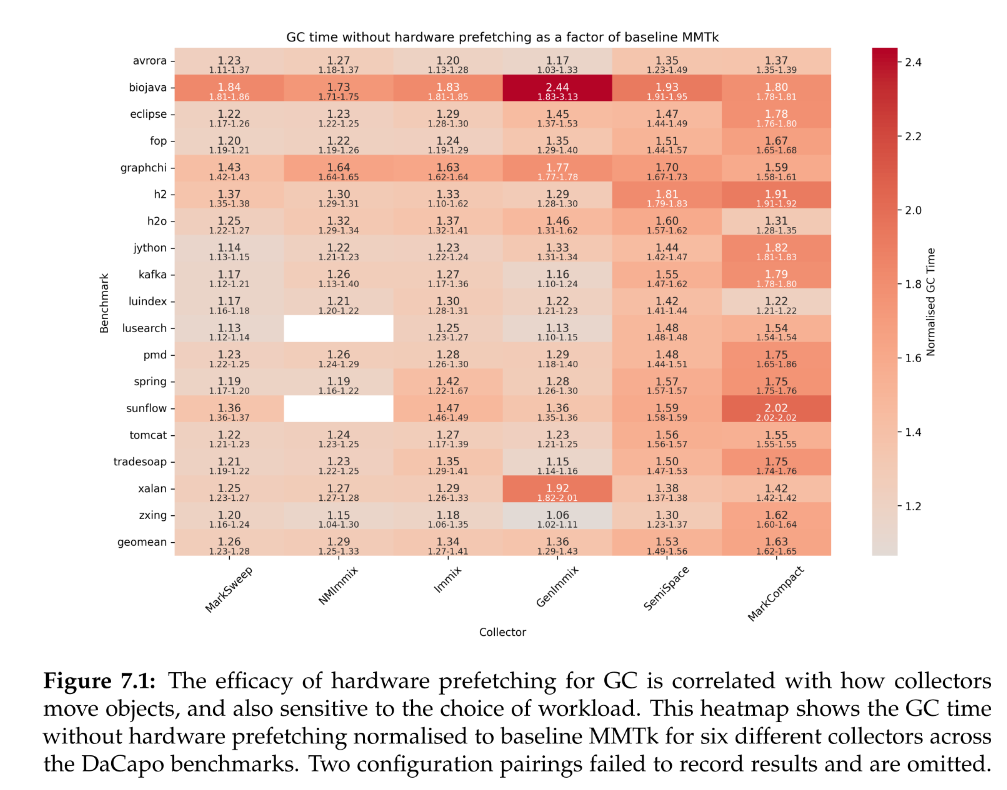
Lots of fun details in Huang's thesis: static vs dynamic prefetching (static is fine), computation of how much one could gain if cache-miss latency were eliminated, what the GC time would be if hardware prefetchers were disabled (20-80% slower; see attached figure); mutator time without prefetchers (sometimes it's better??!?); how to use "perf mem"; all good stuff!
I don't know what's in the water at ANU but they have been doing lots of great work at all levels recently
Steve Blackburn boosted:
Claire Huang wrote an undergraduate honor's thesis, supervised by @steveblackburn and @caizixian https://www.steveblackburn.org/pubs/theses/huang-2025.pdf
She uses sampling PEBS counters and data linear addressing (DLA) on Intel chips to attempt to understand the structure and attribution of load latencies in MMTk.
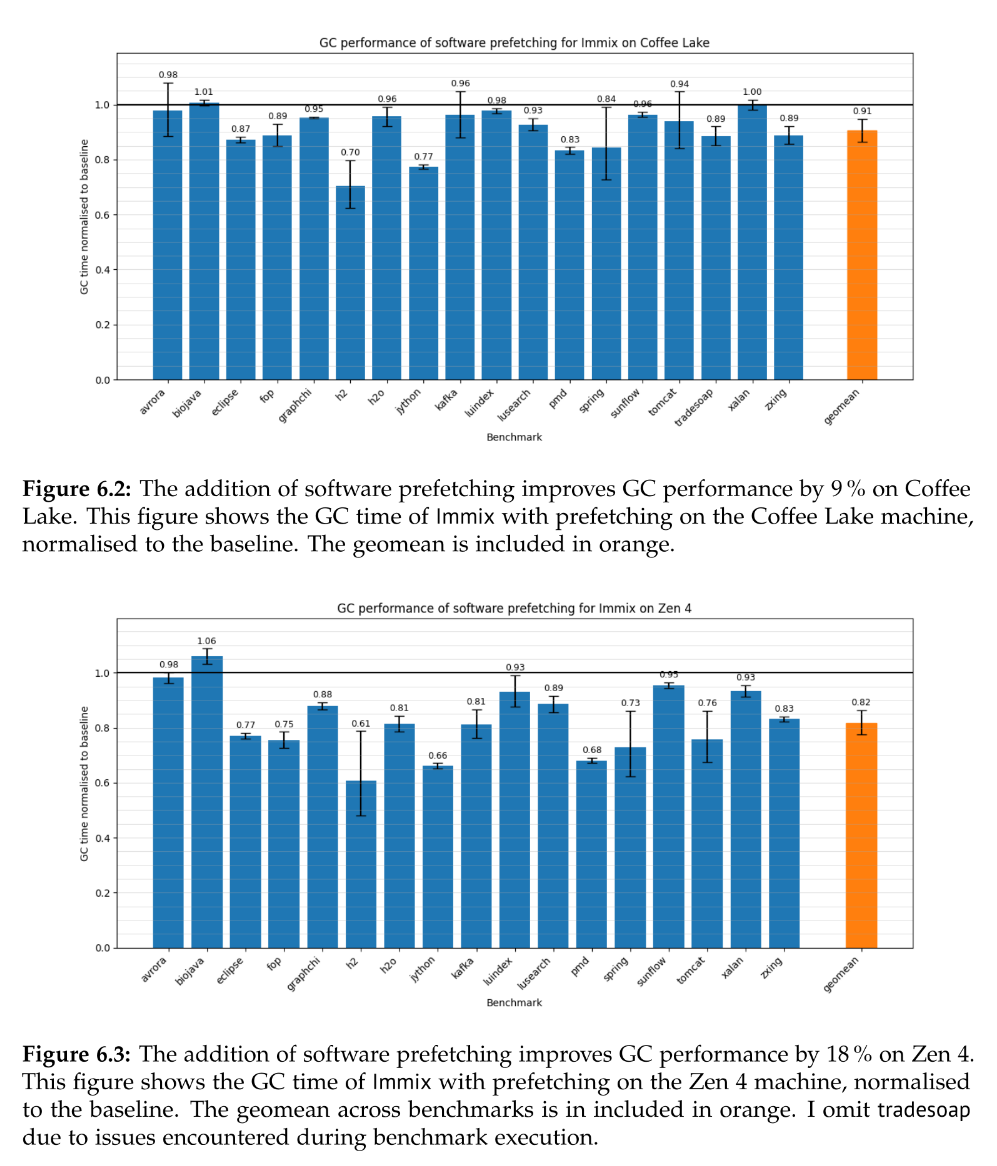
After identifying L1 misses in the trace loop as a significant overhead, she adds prefetching and reduces GC time by 10% or so across a range of benchmarks, and more on Zen4.
We did a deep dive on this ten years ago….
https://www.steveblackburn.org/pubs/papers/yieldpoint-ismm-2015.pdf
Steve Blackburn boosted:
@mgaudet I'm glad I could help.
Following up on the start of this thread on microarchitectural performance debugging, you might find Claire Huang's undergraduate thesis interesting (co-supervised by @steveblackburn). She took a very detailed look at GC in terms of cache behaviors, and measured optimization headroom. https://www.steveblackburn.org/pubs/theses/huang-2025.pdf
She also previously led the eBPF tracing in GC work (MPLR'23).
@samth @wingo @sayrer
I think you made that very same confusion in your response: “heaps from 100g up”.
What do you mean?
If you mean to say that these algorithms are designed only for environments where there’s 64X memory *headroom* (as in the example you gave), then fine, but we need to be call that out explicitly.
If you mean to say that these algorithms are designed for *live heaps* of 100G, then fine but you need to be clear about that, and point out what these applications are. For example, are they pointer rich? Or are they fillies with vast arrays of non pointer data? Who uses these workloads?
My take is that it is absolutely not okay to hide behind this ambiguous language.
If your algorithm needs 64X headroom, say that clearly.
If you’ve built for apps with 100GB of live data, tell us what they are and, getting back to the paper, contribute benchmarks.
Steve Blackburn boosted:
@steveblackburn @wingo @sayrer Right. In the case of the presentation linked above by @samth , the minimum heap size required to run SPECjbb is less than 2GB (https://www.spec.org/jbb2015/docs/userguide.pdf), so when benchmarking on 128GB of heap size, it's at least **64x** the minimum, which is extremely generous.
Wait up. Let’s not confuse “large heaps” with “generous heaps”. This is the number one fallacy I hear in these discussions.
When someone says they ran “in a 100GB heap”, they’re not saying anything about how generous that heap is, how much DRAM they’re burning to get that number. Perhaps G1 could have run in 5GB with similar performance. Unless the min heap is stated, such comments are meaningless or downright misleading.
Collectors trade time for space, and this family of collectors generally needs massive headroom to get okay performance. You can see that plain as day in our paper.
What people sometimes allude to is that because it does not copy concurrently and is strictly copying, G1 will have very costly pauses when the live heap is very large. This is where C4 et al are better. Though LXR also addresses this, without the massive space overhead required.
I think you’re asking why did the industry make such inefficient collectors, given they’re not fools.
In short, there was little incentive to do better. There are two high level issues:1. Methodology. 2. Lack of innovation.
The costs we expose simply were not being measured. Two broad failings: not understanding overhead (addressed by LBO). Not measuring user-experienced latency.
You can “solve”the first one by discounting resources (making out that they’re free). Gil Tene has often pointed out that most cloud VMs are priced so that they come vastly over-provisioned with memory—so use it!! The falicy here is that ultimately someone is paying for that memory and the power used to keep it on. This is why those collectors are not used by data center scale applications, where the cost of those overheads is measured in $10M’s. Second, most GC vendors focus on “GC pause time,” which is a proxy metric that doesn’t translate to user-experienced pauses, which is where the rubber hits the road.
With that backdrop, and those incentives, the lack of innovation is unsurprising. G1, C4, Shen. and ZGC all share the same basic design, which is fundamentally limited by its complete dependence on tracing (slow reclamation, high drag), and strictly copying, which is brutally expensive when made concurrent. (See our LXR paper for a completely different approach.)
So it should be no surprise that companies like Google are so dependent on C++ — those collector costs are untenable for many / most data center scale applications.
@wingo @pervognsen You called? :-)
Always happy to engage with GC discussion
@shriramk Nice. I don’t know of any, but we use this for the dozen or so PLDI organising committee roles, and it is gold. Highly recommend the pattern. Not sure why we don’t do it with PCC.
@wingo we mirror the multithreaded allocator used by the mutator. So each thread has its own thread-local allocator. This is true for both bump allocators and freelist allocators.
@wingo yep, all the generational collectors I’ve built have done parallel nursery collection. The principal overhead is the atomic operation on the mark/forward to avoid the race among collector threads.
@wingo Parallel copying GC is pretty standard. One of the first GCs i wrote was parallel semi space for Jalapeño (JikesRVM), as a postdoc. That was > 20 years ago 🙄All of the GCs I’ve written since are parallel. 😊
Steve Blackburn boosted:
PLDI SRC submission deadline is in 2 days! https://pldi23.sigplan.org/track/pldi-2023-src
PLDI SRC has a two-track model that supports both in-person and remote presentations.
This year's PLDI is also part of FCRC (https://fcrc.acm.org/) which contains many different and interesting CS conferences.
@adrian @ZeusHammer likewise. I’m afraid I have nothing to offer on that. It’s a great question.


@ZeusHammer @csgordon Industry.
The SPEC benchmarks existed because industry agreed they needed a “level playing field” for comparing their products. The fee is presumably covering some of the development costs.
TBH it all seems very 1990s to me :-)
Also, developing good benchmarks is incredibly expensive. :-/
@csgordon @ZeusHammer I don’t know, Emma, it’s been a long time since I’ve used SPEC CPU. But I’m not aware of it setting anything, just recording the details of your hardware as part of the reporting process.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst