@zeux @pervognsen @joew @cks The challenge for most projects is how to deal with growing a trusted team - allows scaling, allows multiple different motivations and interests to align more, allows a future when dev[0] decides they've had enough. Corp projects naturally handle that, open source still relies on lone heroes by default.
Pete Harris
Arm CPU and GPU optimization, performance tools, and texture compressors
@zeux @pervognsen @joew @cks Funding allows aligned devs to work on their project more - job not spare time hobby. But it cannot help if the developer motivation misaligns with the emergent needs of the project. Money doesn't bring motivation or alignment if you're just not interested in productization or just not interested any more.
Similarly contributions can help, but reviewing and accepting non-trivial PRs is still hard work and needs motivation to do.
@zeux @pervognsen @joew @cks My take is that the challenge is really one of agency and motivation, and corp funding might help, but wont in many cases.
If you release something as open source you really lose control of its scope, both in terms of importance and in terms of time of service
It works as long as the needs of the project align with developer motivation. Not everyone enjoys long haul maintenance work, and eventually life moves on for many people.
@rygorous @pervognsen true, wiring tends to be a level above this (how to group units, move data between them, move data from registers to functional blocks, etc).
@rygorous @pervognsen I'd be very curious what efficiency of modern circuits looks like when built on 45nm vs the older designs used originally.
@rygorous @pervognsen one of the big shifts driving changes in the last 10 years or so is the relative cost of wires in the designs.
On old silicon process wires were "free", so circuits optimised for transistor count and were quite happy moving data around. Below 10nm wires are darned expensive, and we have room for gates as long as you can find space to actually wire them up. That reverse totally flips the table on what logic optimization looks like.
@avokado yeah, that would work, and also avoids the no-op verts.
More restrictive than full mesh shaders - meshlets are fixed sets of normal verts - but access to higher order culling strategies would be "nice".
Has anyone tried doing meshlet style culling with a classical vertex shader?
Something like compute shader does meshlet visibility check as a prepass, writes a bool to a storage buffer per meshlet. Vertex shader reads bool, and early-outs with a NaN position if not visible.
Allows vertex shading on a tile-based renderer to benefit from higher-order culling, without breaking the fixed-function geometry handling tilers use to optimize memory bandwidth.
@pervognsen I'd still assume something like a cache model ends up being expensive compared to just DBT and running it. Say 25% of program instructions touch memory and the model cost is 20 instructions, then you're at a 5x slowdown.
@pervognsen Yeah, thats fair. We've done some tooling with DynamoRIO, it's definitely viable as an approach.
@pervognsen suspect its just too slow - even callgrind to just count instructions with no cache or branch modelling is two orders of magnitude slower than running native. Our main problem in CI benchmarking is shared tenancy hardware, but for the cost of 100x slower its cheaper just add a single tenant metal instance and run a few times.
Arm Performance Studio 2025.3 is now out! Minor release, so no huge new features, but more usability polish and bug fixes.
Free Android profiling tools for Arm CPUs and Mali GPUs. Give it a try.
https://developer.arm.com/Tools%20and%20Software/Arm%20Performance%20Studio#Downloads
@Biovf Me too! I've been trying to get this into release OEM drivers since Mali-400 =)
P.P.S. An integration of this data visualization will be added to our Streamline profiler in the next major release later this year, but there is a fully functional Python viewer for it in the GitHub project.
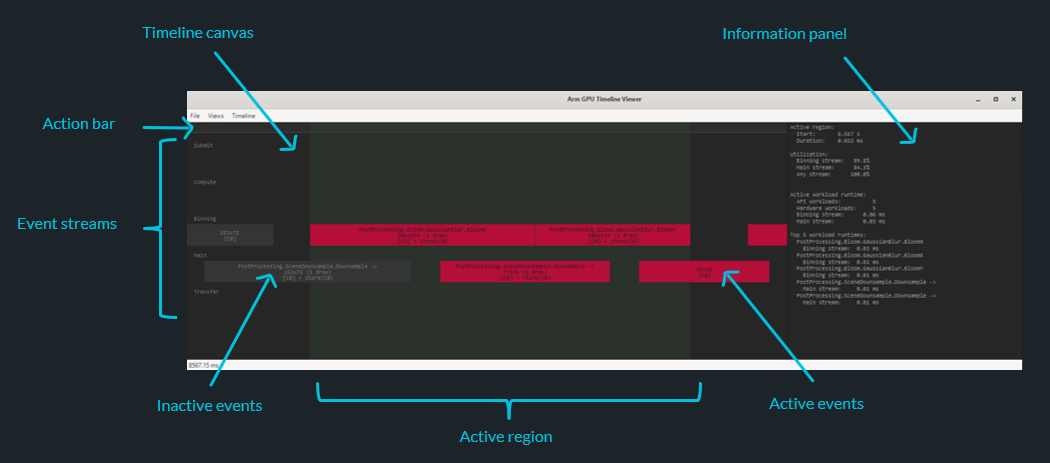
P.S. Please can engines try to use slightly more compact debug label stacks - we have finite screen space!
Back at Vulkanised I presented a new Arm Mali GPU scheduler profiler which could hook your API debug labels to tag the boxes in the GPU queue visualization, with a promise of available "soon".
It's taken a while, but "soon" is finally here. Android 16 update for Pixel 7/8/9 includes the driver update to our r53p0 driver which adds the data tracking we needed. If you like making Arm GPUs go fast, give it a go and let me know what you think.
https://github.com/ARM-software/libGPULayers/blob/main/layer_gpu_timeline/README_LAYER.md
Pete Harris boosted:
If you are interested in low-level development, our rendering lead @clayjohn wrote a post sharing some insights into the optimization process for mobile devices using Arm Performance Studio 👇
Pete Harris boosted:
An analysis of HDR on Mario Cart World on Switch 2.
https://www.alexandermejia.com/from-sdr-to-fake-hdr-mario-kart-world-on-switch-2-undermines-modern-display-potential/

Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst