Hello, I am a statistician at Chalmers University of Technology and University of Gothenburg!
I work on scientific #machinelearning problems taking a Bayesian #statistics and causal inference perspective and contribute to #JuliaLang.
probabilistic programmer (#probprog), #FOSS contributor and advocate, #JuliaLang developer, bringing #MachineLearning to the sciences at the ML ⇌ Science Colab @unituebingen. he/him
Hello, I am a statistician at Chalmers University of Technology and University of Gothenburg!
I work on scientific #machinelearning problems taking a Bayesian #statistics and causal inference perspective and contribute to #JuliaLang.
@johnryan Yeah I do #probprog in #JuliaLang, and it's great that we can use arbitrary Julia code within our models. This is because most of the language is differentiable with #autodiff and code is composable, which is not the case for most PPLs.
For #deeplearning research, Julia could come in handy for writing and transforming custom kernels without fussing with CUDA, as some posts in that thread note, but I have no experience with this.
@johnryan This blog post reflects one (important) perspective. The community had a large discussion about this earlier this year: https://discourse.julialang.org/t/state-of-machine-learning-in-julia/74385
My take away is "it depends." If you're doing classical ML, Julia is usually fine. For cutting edge DL, it's generally not as mature as Python yet. For research/nonstandard ML, Julia shines.
In ArviZ.jl we store inference results (especially #MCMC draws) as InferenceData. It's built on DimensionalData, so we have multidimensional real arrays with named dimensions. Each array element is a marginal of a random draw, which is a useful format for plotting, #statistics, and diagnostics, but sometimes it's useful to get back to a structure more like what a PPL might emit.
Surprisingly, we can get pretty close with just 8 lines of code:
https://github.com/arviz-devs/InferenceObjects.jl/issues/27
@cameron_pfiffer Seriously, and it's about the only day where it's normal for random neighbors to visit each other. In my old neighborhood, band members all lived in the same house, and every Halloween hundreds of people would fill the streets to watch them perform a live show on their lawn. No other holiday comes close!
@PhilippHennig Ah, good to know for next year! We leave at the bottom of the hill and have seen almost no decorations and no trick-or-treaters. We'll have to explore the top of the hill next time!
@cameron_pfiffer and easy to support him via https://opencollective.com/mastodon or Patreon
Just so y'all know, the lead Mastodon guy does this for a hilariously small amount of money. OSS is something else
📢PARENTS📢
Make SURE you check your children's candy carefully this Halloween🍬
I just found HETEROSKEDASTICITY in this snickers bar😲😱

I don't find myself missing many aspects of US culture here in Germany, but, strangely enough, I do miss #Halloween.
The note is visible on the desktop site but not the official Android app. The Tusky app shows it though.
Hello everyone out there in the fediverse!
I'm currently a Academy of Finland postdoctoral fellow at Aalto University working on probabilistic #machinelearning. Most of my interests are related to probabilistic #machinelearning methods that are flexible (#nonparametric), efficient (#tractable), and exact or come with guarantees (or a subset of thereof).
In my research, I work a lot with #JuliaLang and I'm always eager to learn new things.
Curious to see where this all goes.
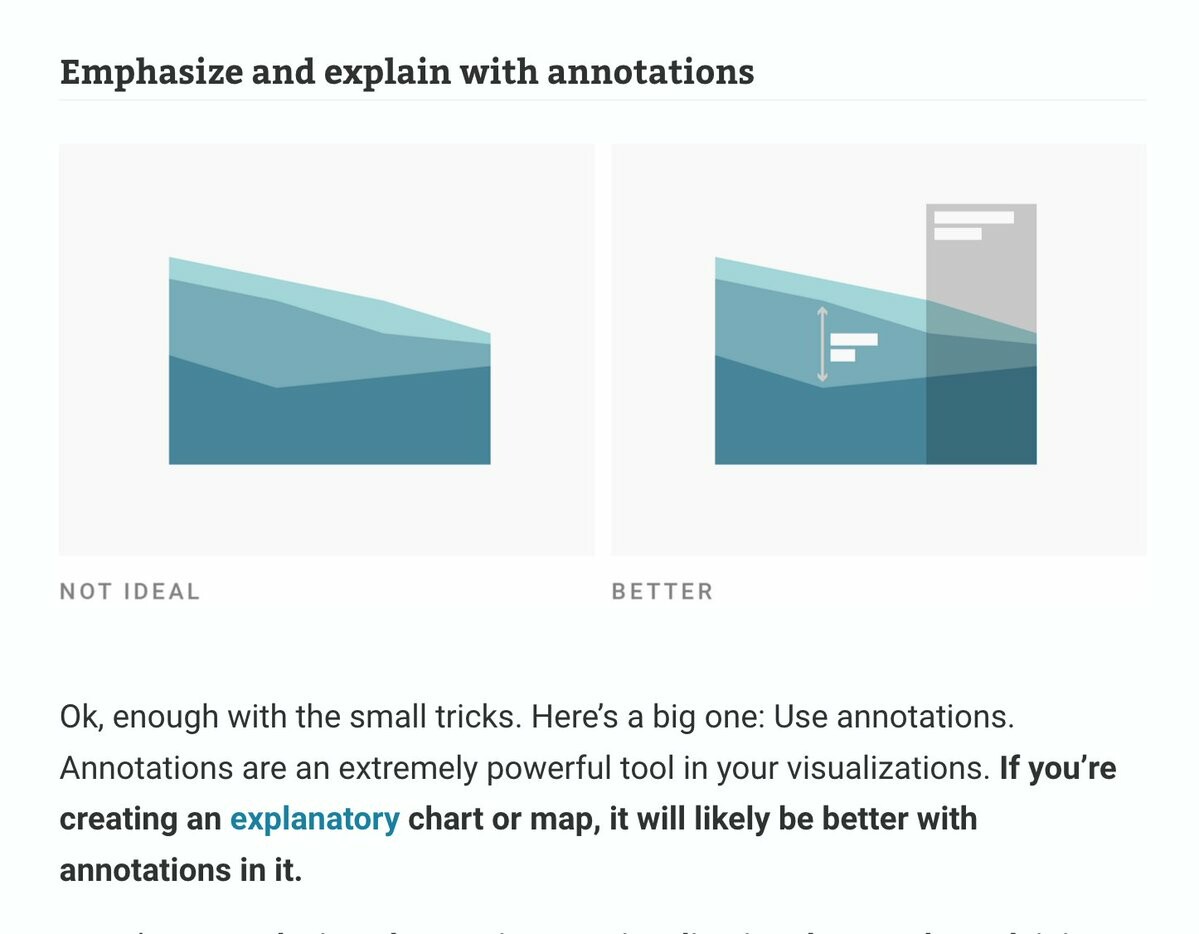
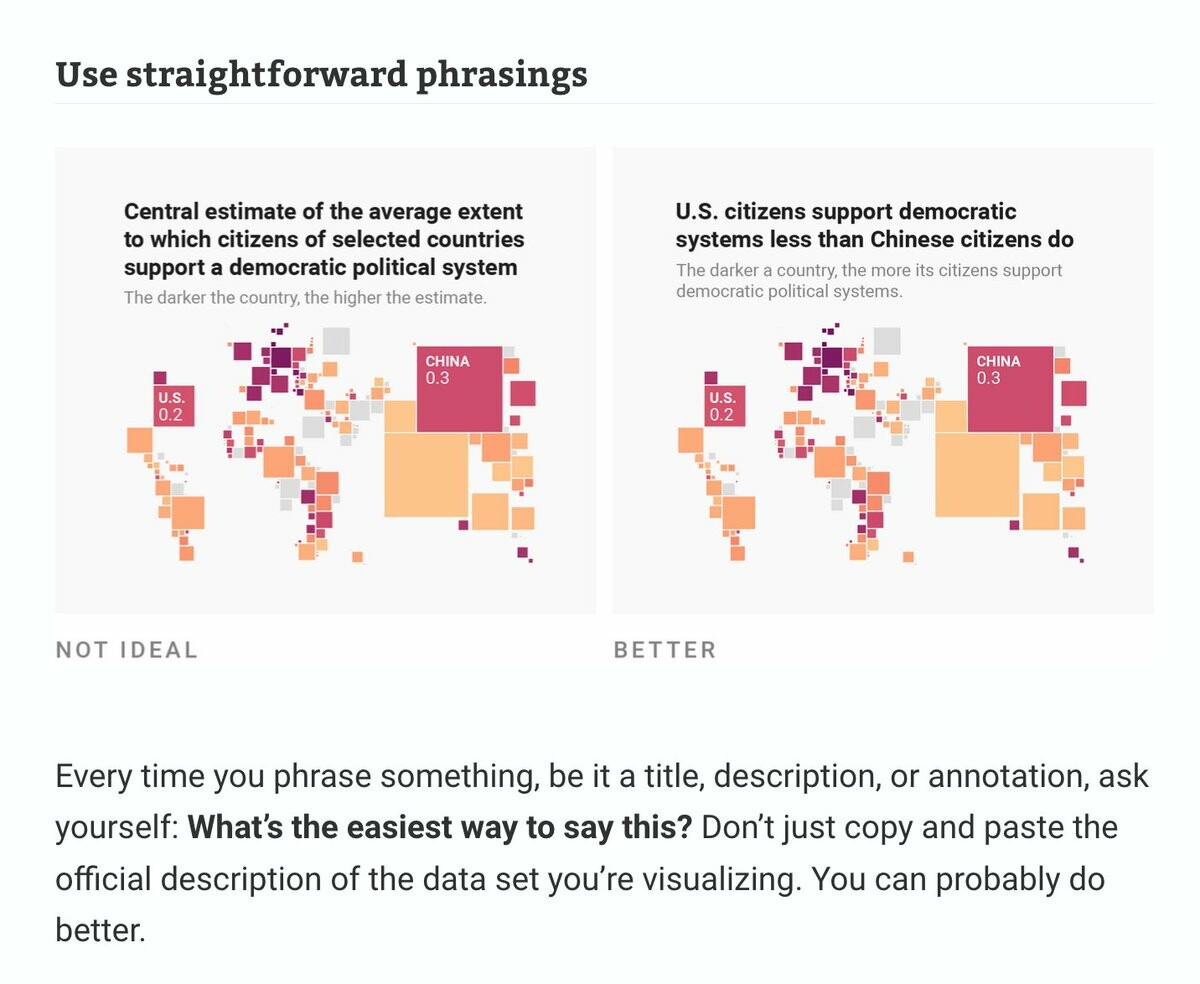
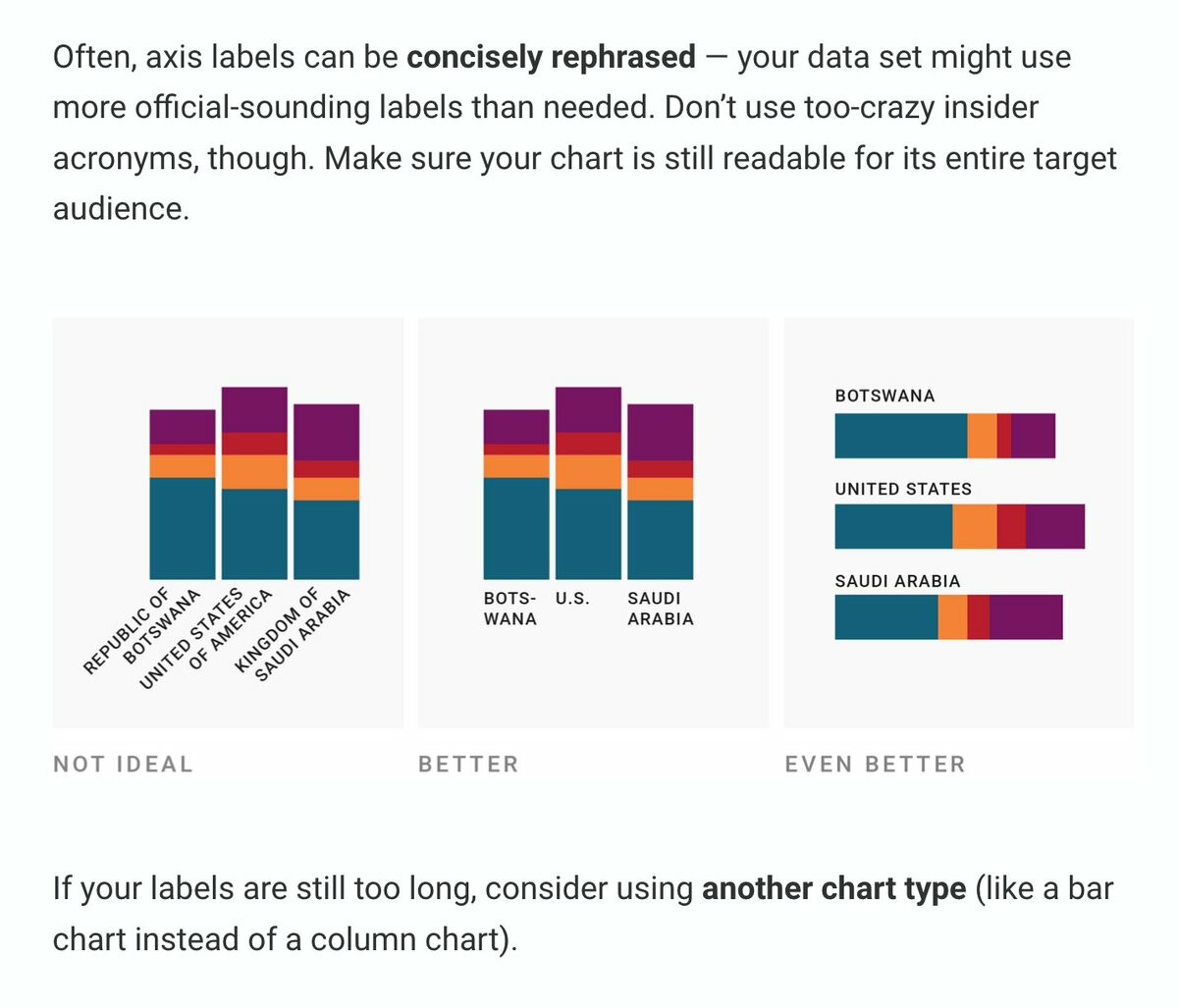
Text might be the most neglected part of #dataviz. We talk a lot about how the right chart type and colors can improve visualizations – but not enough about how to use words well.
So I wrote about that in my latest article: https://blog.datawrapper.de/text-in-data-visualizations/

@discretestates @mikarv I do really like the idea of multiple available user -designed recommender systems that could be installed as customizable plug-ins. I wonder how this would work with the design. Does Mastodon support plugins that add to the interface?
I just noticed everyone has a "NOTE" entry on their profile that presumably only I can edit and see. This is really nice! I've long wanted to attach to accounts I follow why I followed them so I can more easily re-evaluate that follow, so this is very helpful!
I suspect with the current sorting I'll either 1) decide that any given interaction is unimportant, so missing something is not a big deal (could be healthier) or 2) only follow people whose fraction of toots I find relevant are high.
While I like not being at the mercy of an algorithm that promotes addiction, showing all toots in chronological order feels like swinging the other way. If I don't want to miss an important interaction, I need to spend more time reading everything. Some recommender system would still be nice.
Working through Richard McElreath's video lecture on ordered logit (https://www.youtube.com/watch?v=-397DMPooR8) and just learned that I've been pronouncing "Dirichlet" wrong for *years*
It's "dir-ee-klay" not "dir-eesh-lay"!
Wikipedia's IPA confirms the "k" not "sh" too