Can You Start With a Loop Inside Your Schedule-Triggered Flow?
Salesforce automatically runs schedule-triggered flows at specific times and intervals without needing user interaction. These flows are ideal for tasks that need to occur on a recurring basis, such as daily data updates, batch record processing, or sending scheduled notifications. By configuring the start time, frequency (daily, weekly, etc.), and conditions for triggering, admins can efficiently manage routine operations, ensuring data consistency and reducing manual workload. Schedule-triggered flows help streamline business processes and maintain system accuracy by automating time-based actions.
There are three common misconceptions about schedule-triggered flows
- New schedule-triggered flow builders usually think they must get all the records their flow needs to process, loop, and process all records in a single flow interview. In other words they need to bulk-process their flow logic themselves at the time of build. I will show you below, that this assumption is incorrect.
- New flow learners have a hard time understanding how their start time is scheduled. When should they use a schedule-triggered flow versus a scheduled path in a record-triggered flow? I will explain how you can correctly decide in this article.
- Most flow builders assume that schedule-triggered flows require an object selection in the start element. Later in this article, I’ll demonstrate how schedule-triggered flows can be designed to run at a specific future time, automating processes that aren’t necessarily tied to records of a particular object defined in the start element.
Get and Loop Elements Right After the Start Element Anti-Pattern
When building a schedule-triggered flow, you select an object in the start element and optionally add conditions. Here’s a metaphor to explain: Imagine you want your flow to run next Saturday at midnight and update all cards with a face value of 3 to 13. In a deck, there are 4 such cards. Your logic only needs to handle one record (one card). The flow engine automatically creates separate interviews for each matching record (all 4 cards), processing them without manual loops or retrieval. This means all 4 cards are updated efficiently, with the flow engine handling bulk processing for you. No extra logic is needed—just define the criteria, and the engine does the rest.
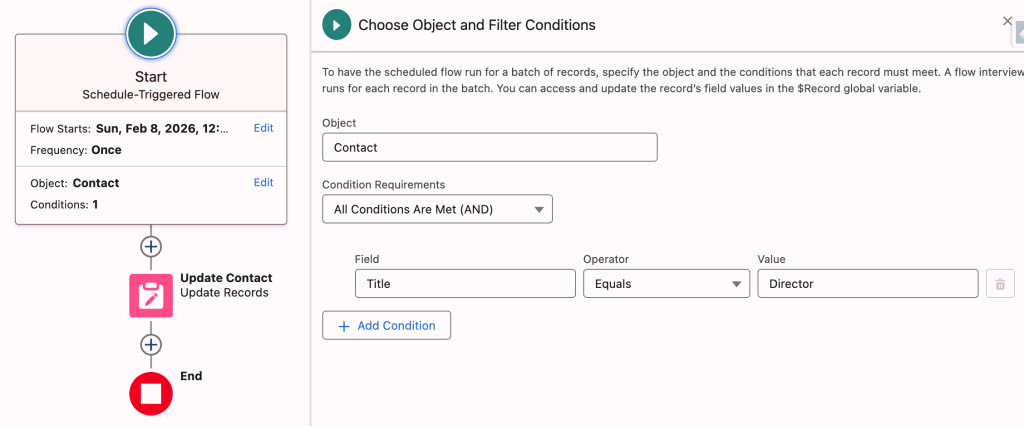
🚨 Use case 👇🏼Let’s return to Salesforce and discuss how schedule-triggered flows are executed. Suppose you want to process all Contact records in your org where the Title is ‘Director’ and update it to ‘Senior Director.’
Here’s how you’d set it up:
- Configure the start element to run on the Contact object.
2. Add a condition to the start element to filter records where the Title equals ‘Director.’
3. Add an update element to change the Title from ‘Director’ to ‘Senior Director.’
When the flow runs at the specified date and time, the flow engine processes each matching record individually. For example, if there are 4 matching records, the engine will execute 4 separate flow interviews, one for each record. These interviews are batched, with each batch containing up to 200 interviews (or records). So, for 4 records, the flow executes in a single transaction, while for 201 records, it would execute in 2 transactions.
Avoiding Common Pitfalls: Why You Shouldn’t Manually Loop Through Records in Schedule-Triggered Flows
What new learners tend to do is configure the start element, then proceed to get all contacts in the org where the title is Director, loop through them and process them. If there are 4 matches in the Org, this multiplies the update execution need and produces inaccurate results. Your single interview will run 4 loops, executing on 4 matching records and producing 4 interviews. That is actually 16 executed loops that are needed.
In summary, you build your flow to handle a single record, set up your start element to define which records the flow need to run on, and don’t worry about the rest, the flow engine will take care of it.
Schedule-Triggered vs. Scheduled Path in Record-Triggered Flow
Source: Trailhead by Salesforce https://trailhead.salesforce.com/content/learn/modules/autolaunched-scheduled-flows/schedule-a-flowWhile there are overlaps, the usage of schedule-triggered flows are different in nature than the scheduled path under record-triggered flow. Here are the parameters that need to be considered:
- When you have a specific date and time you need your flow to execute – e.g. next Thursday at 11:00 PM – then you must use a schedule-triggered flow.
- When you have a frequency requirement for recurring actions, then you must build a schedule-triggered flow.
- When you need to relate your execution time – 1 hour after or 1 day before – to a record being created or updated (DML), then you must use a scheduled path in a record-triggered flow. Remember though: you cannot determine the time of the action for offsets longer than a day. If you have an email action and a 1-day after offset, the system will send the email at the same time the create/update occurred one day later.
Certain situations can generate approximately the same outcome using either solution. This is generally a confusing topic when you first start diving into time delay operations using flow.
Object Selection
You may have noticed, the Object reference in the start element of the schedule-triggered flow is marked as optional. Most people never try this alternative. When you build a schedule-triggered flow without an object selection, you create a scheduled job to run in the future. This flow, as opposed to the other flows with object selection, will for sure run only one transaction containing one single flow interview. Therefore this is a flow that can include loops and collections. Having a loop at the start of this type of flow is not an anti-pattern. Remember that you can use the transform element, collection filter and sort to lighten the load when you deal with collections.
🚨 Use case 👉🏼 Streamlining Operational KPI and Trendlines for Optimization
Conclusion
The power of scheduled jobs in Salesforce lies in their ability to automate time-dependent tasks, ensuring consistency, efficiency, and reliability across business processes. By utilizing scheduled jobs—whether through schedule-triggered flows, Apex schedulers, or declarative tools—organizations can automate repetitive tasks like data cleanups, report generation, and batch processing without manual intervention. This not only saves time and reduces errors but also ensures that critical processes run during off-peak hours, optimizing system performance. Scheduled jobs also enhance scalability, allowing businesses to handle large data volumes and complex workflows with minimal oversight.
Using schedule-triggered flows make scheduled jobs more accessible to most profiles on the Salesforce platform. It is sometimes better to handle some actions after hours while the Org usage is down to avoid potential system performance issues. Flow builders should always consider this tool to produce the automations that will enhance the company KPIs and goal attainment performance.
Explore related content:
Salesforce Flow Best Practices
How To Use Custom Permissions In Salesforce Flow
One Big Record-Triggered Flow or Multiple?
Understand How Scheduled Flows Affect Governor Limits (External)
#Salesforce #SalesforceAdmin #SalesforceDeveloper #ScheduleTriggered