@EzellaGarnie @cneud @titusz @awinkler @hartmut_beyer @Lambo Die OCR ist das Pre-Processing zur Erzeugung der Basis, die als Input zur Generierung des ISCC dient. Der Input kann ja unterschiedlich sein. Man müsste Mal testen, was dann am Ende herauskommt.
Posth
Building Liccium, sign-up via liccium.com; ISO 24138 ISCC
@EzellaGarnie @titusz @awinkler @hartmut_beyer @Lambo
Es wäre sehr interessant, das Pre-Processing der Scans via OCR zu testen, u.a. mal unterschiedliche Software zu vergleichen.
@osma @titusz @awinkler @Lambo @EzellaGarnie
A nice bird :) Well, these codes are deterministic, right? -->
- ISCC v0 64bit code X
- ISCC v0 32bit code Y
- ISCC v1 64bit code Z (in the future)
Since ISCC is self-describing, you know which version is used to generate the code.
But I see what you mean. For transparency reasons you could extract and list the version number, which is embedded in the ISCC. But I guess this may be redundant information.
@osma @titusz @awinkler @Lambo @EzellaGarnie
If the version is defined within the ISCC, what do you exactly mean by "there's no 1:1 mapping between content items and ISCCs"?
@EzellaGarnie @awinkler @osma @Lambo
@titusz May want to weight in with regards to some points.
@EzellaGarnie @awinkler @osma @Lambo
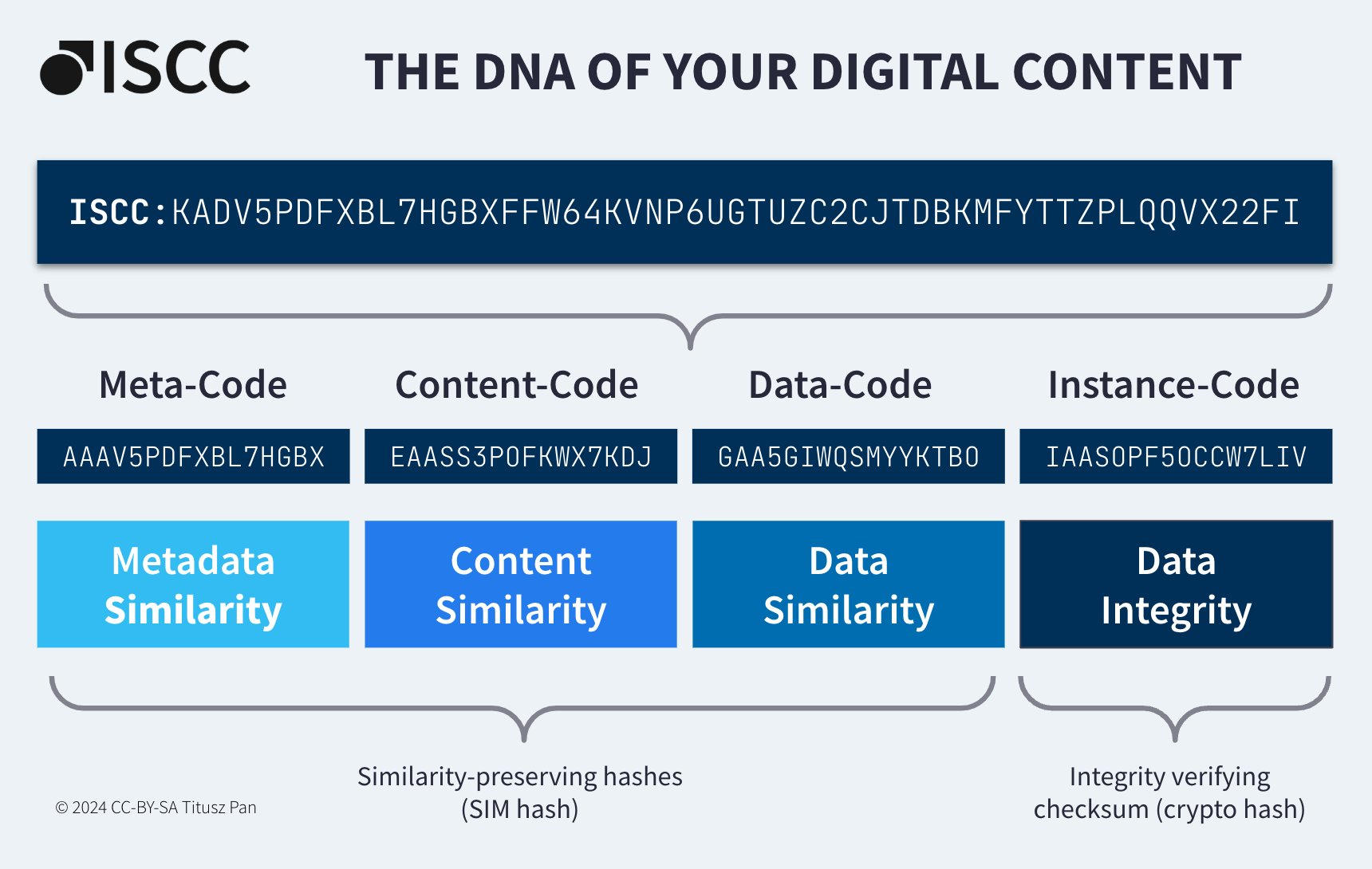
This document describes the general structure of the ISCC:
ISCC Structure and Format:
https://ieps.iscc.codes/iep-0001/
I don't think that you need to store the version number "next to the code".
@EzellaGarnie @awinkler @hartmut_beyer @Lambo
ISCC generiert auch Fingerprints / Chunks für Text. Schau mal hier.
https://huggingface.co/spaces/iscc/iscc-playground --> Chunker
Diese Codes erlauben den Vergleich auf der Detailebene. Viele Chunks deiner Scans sind identisch. Das wäre der Ansatz, den ich wählen würde. Nicht nur die ISCC Codes für den gesamten Text oder die Seite generieren, sondern auch für die Chunks. Diese kann man dann vergleichen und die Inhalte viel besser matchen.
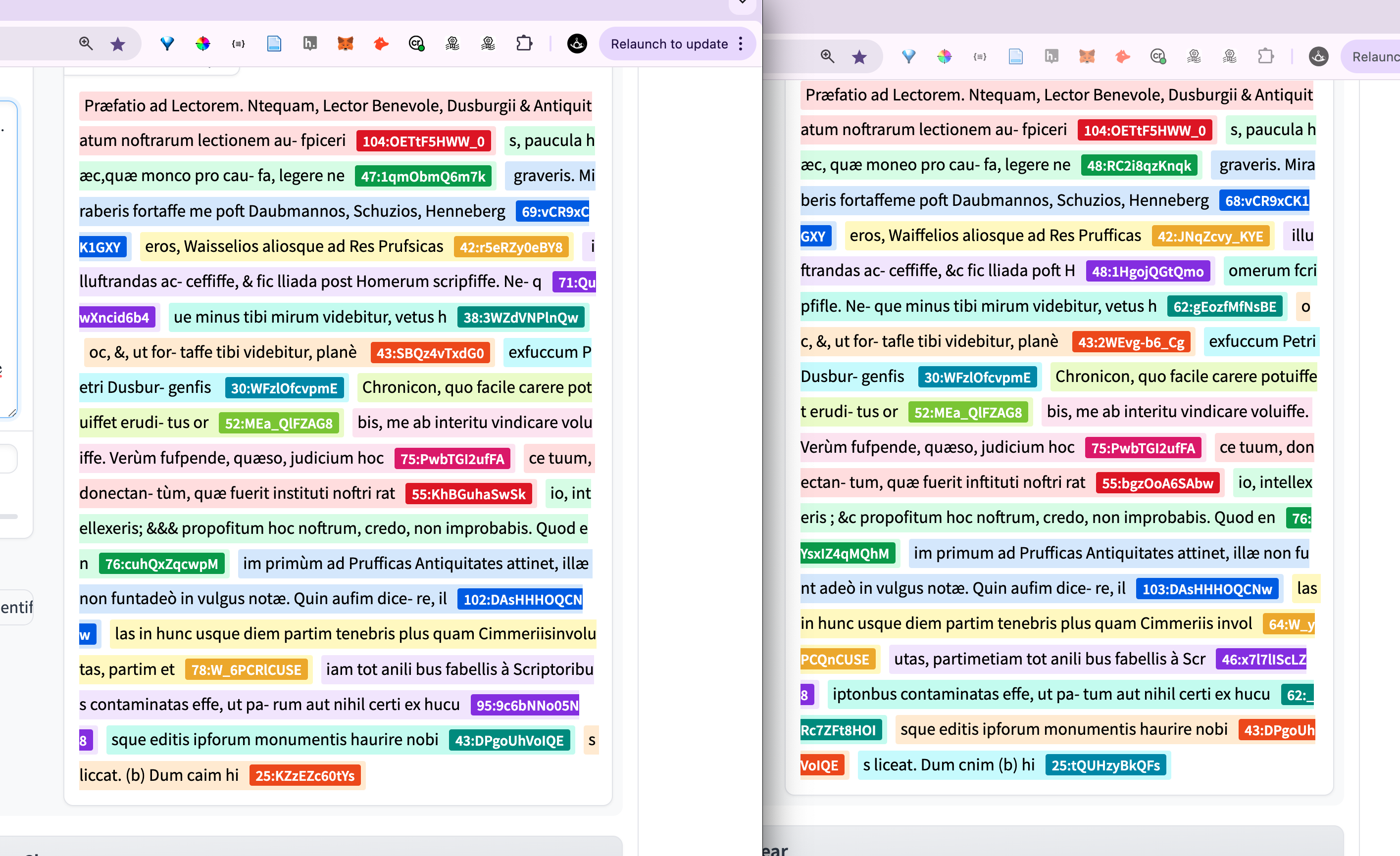
@EzellaGarnie @awinkler @hartmut_beyer @Lambo Das war jetzt eine einfache Google Lens OCR. Aber es gibt da sicherlich viel spezifischere Tools, auch für etwas ältere Drucke. Vielleicht kann man KI auch für Handschriften_Erkennung trainieren und dann verschiedene Seiten (Scans) zusammenfügen und analysieren. Ich sehe da viel Potenzial, aber es bedarf einiger Vorarbeit, wenn man nur die Scans vorliegen hat.
@EzellaGarnie @Lambo Wir können uns gern mal besprechen. Es ist im Prinzip eine Frage des Pre-Processing der Bilddateien (Scans) von Texten. ISCC für Bilder analysiert Pixel, ISCC für Text Character-Informationen.
@EzellaGarnie @awinkler @hartmut_beyer @Lambo
Bei diesen Scans könnte/muss man eine OCR vorschalten und einen ISCC Text (statt Bild) erstellen. Dann gibt es einen sinnvollen Match (9 bits Unterschied). Die Bilder selbst sind glaube ich nicht aussagekräftig.

@EzellaGarnie @awinkler @hartmut_beyer @Lambo Ein Student des if(is) macht gerade einen sehr ausführlichen Test des ISCC mit hunderten, unterschiedlichen Use Cases, der zeigt, wieweit das Matching reicht – jeweils per Medienart. Ich hoffe, dass diese Analyse vielleicht bis Ende des Jahres von ihm publiziert werden kann. – Das kann helfen, die Erwartungen zu "managen".
@EzellaGarnie @awinkler @hartmut_beyer @Lambo
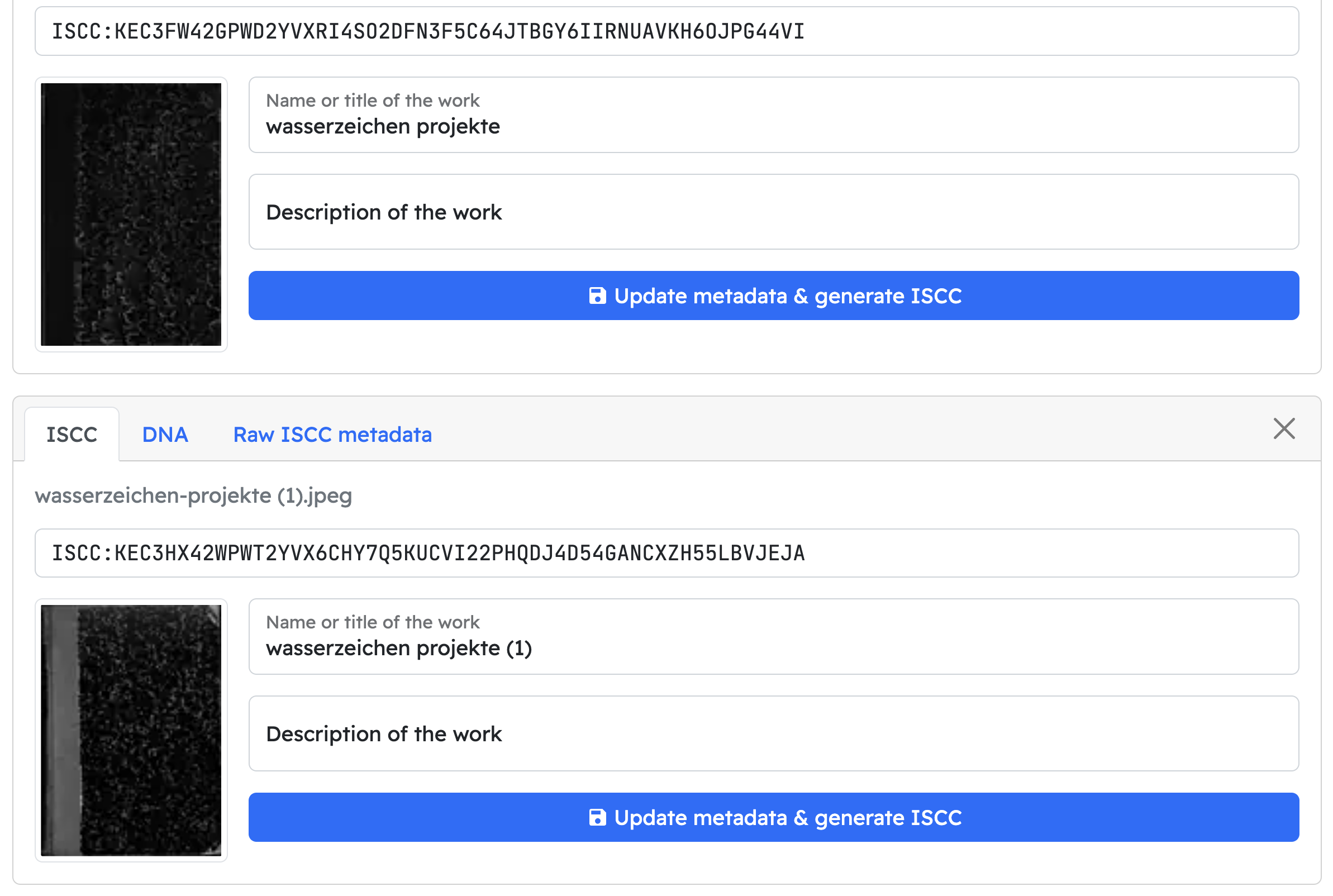
Auf https://demo.iscc.io/ kann man auf dem "DNA"-Tab (Reihen 5-8) zählen, wie viele Bits unterschiedlich sind. Alle 3 Beispiele wären total unterschiedlich und würden auf Basis des ISCC kein Matching zulassen.
Die zur Zeit noch experimentelle Semantic-Code Unit würde eine geringe inhaltliche Ähnlichkeit feststellen: https://huggingface.co/spaces/iscc/iscc-playground

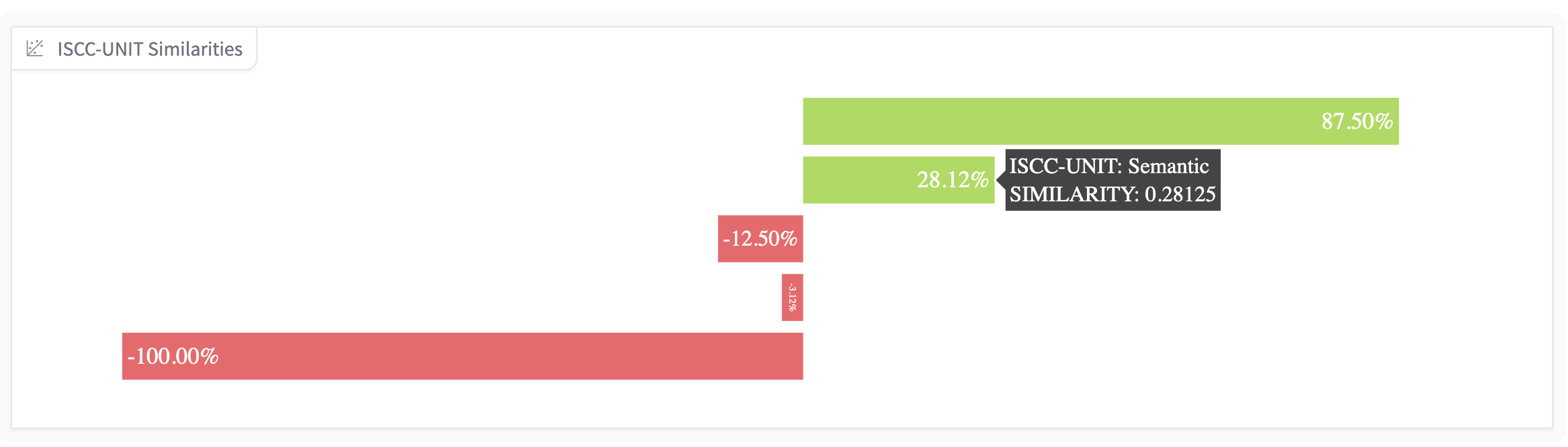
@EzellaGarnie @awinkler @hartmut_beyer Digitalisate sind Bild-Dateien, bei denen das 'near-duplicate matching' gewisse Grenzen hat. Im Bereich zwischen 10-16 unterschiedlichen Bits (basierend auf den 64 Bits der Unit) trudeln die falsch-positiven Treffer ein.
Posth boosted:
@EzellaGarnie @Lambo ich habe hier auch gleich ein Property Proposal für den ISCC auf #Wikidata eingereicht (https://www.wikidata.org/wiki/Wikidata:Property_proposal/ISCC). Könnte ja durchaus nützlich sein z.B. bei den strukturierten Daten auf WikiCommons.
@Life_is @Raymond @wikimediaDE
Bei Liccium haben wir ein sogenanntes "Soft-Binding" implementiert, dass es ermöglicht, Rechte und Metadaten (Exif, IPTC, und andere Industriestandards) in einer externen Datei zu bündeln und mit den ISCC zu verknüpfen. Jede/r User mit Zugriff auf die Mediendatei kann nun den ISCC aus der Datei erzeugen und die externe Datei auslesen.
https://liccium.com/solution/
@Life_is @Raymond @wikimediaDE
Was das Thema der KI Trainingsdaten betrifft geht es ja im Wesentlichen um die Frage, wie Rechte und Metadaten unlösbar mit dem Inhalt verknüpft werden können. Das Einbetten von Metadaten ist eine wenig zuverlässige Methode, da die Metadaten beim social sharing ja in der Regel entfernt werden.
@Life_is @Raymond @wikimediaDE
Wo finde ich denn den Post zu ISCC? Verweist Du auf diese Proposal: https://commons.wikimedia.org/wiki/Commons:Village_pump/Proposals#Proposal_to_add_perceptual_hashes_to_SDC?
ISCC ist ein ISO Standard Identifier, der "Perceptual hashes" verwendet: "checksums which can be used to identify visually identical images even if they have been scaled, re-compressed, or subjected to minor alterations."
Thanks for your excellent post! Very much appreciated. @EzellaGarnie @Lambo
Posth boosted:
Posth boosted:
"Recently, the #C2PA adopted the #ISCC as one identifier that is among its list of authoritative soft binding algorithms in the C2PA model."
Todd goes on describing very well the strength of #PID|s, and how PIDs and ISCC will complement each other.
Introducing the Newest ISO Identifier Standard: @tac_NISO (Todd Carpenter, NISO Executive Director) on ISCC, DOI and DIDs.
via @Posth
cc @EzellaGarnie
Try out the ISCC yourself: https://huggingface.co/spaces/iscc/iscc-playground
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst