Pleased to share that our paper (https://sigmoid.social/@lampinen/112491958002918498) is now accepted at TMLR! The camera-ready version should be clearer and improved thanks to the helpful reviewer comments (and others). Thanks again to my co-authors @stephaniechan and @khermann
The TMLR version is here: https://openreview.net/forum?id=aY2nsgE97a
and the arXiv version (https://arxiv.org/abs/2405.05847) should be updated to match shortly. Check it out if you're interested in interpretability, and its challenges!
#interpretability
Andrew Lampinen
Interested in cognition and artificial intelligence. Research Scientist at DeepMind. Posts are mine.
Really excited to share that I'm hiring for a Research Scientist position in our team! If you're interested in the kind of cognitively-oriented work we've been doing on learning & generalization, data properties, representations, LMs, or agents, please check it out!
https://boards.greenhouse.io/deepmind/jobs/6182852
#research #jobs
Pleased to share my paper "Can language models handle recursively nested grammatical structures? A case study on comparing models and humans" was accepted to Computational Linguistics! Early journal version here: https://direct.mit.edu/coli/article/doi/10.1162/coli_a_00525/123789/Can-language-models-handle-recursively-nested
Check it out if you're generally interested in assessing LMs against human capabilities, or in LM capabilities for processing center embedding specifically.
For a summary thread, see here: https://sigmoid.social/@lampinen/111323229743634437
Pleased to share that our paper "Language models, like humans, show content effects on reasoning tasks" is now published in PNAS Nexus!
https://academic.oup.com/pnasnexus/article/3/7/pgae233/7712372
#LanguageModels #lms #AI #cogsci #machinelearning #nlp #nlproc #cognitivescience
Andrew Lampinen boosted:
@gmusser @thetransmitter @kristin_ozelli @KathaDobs @ev_fedorenko @lampinen @Neurograce @UlrikeHahn 👆I really recommend this. There is a fair bit of comment on this platform on how non-human-like artificial neural networks and #LLMs are, but most of it is not by cognitive scientists or neuroscientists. This article is an informative counterbalance.
Andrew Lampinen boosted:
At a detailed level, artificial neural networks look very different from natural brains. At a higher level, they are uncannily similar. My story for @thetransmitter, edited by @kristin_ozelli, features @KathaDobs @ev_fedorenko @lampinen @Neurograce and others. https://www.thetransmitter.org/neural-networks/can-an-emerging-field-called-neural-systems-understanding-explain-the- #neuroscience #AI #LLMs
@cigitalgem thanks! Curious to hear any reactions you have
This paper is really just us *finally* following up on a weird finding about RSA (figure on the here) from a paper Katherine Hermann & I had at NeurIPS back in the dark ages (2020): https://x.com/khermann_/status/1323353860283326464
Thanks to my coauthors @scychan_brains & Katherine! 9/9
We also just find these results inherently interesting for what they suggest about the inductive biases of deep learning models + gradient descent. See the paper for lots of discussion of related work on (behavioral) simplicity biases and much more!
We’ve also released a colab which provides a very minimal demo of the basic easy-hard representation bias effect if you want to explore it for yourself: https://gist.github.com/lampinen-dm/b6541019ef4cf2988669ab44aa82460b
8/9
Similarly, computational neuroscience compares models to brains using techniques like regression or RSA. But RSA between our models shows strong biases (the stripes); e.g. a model doing two complex tasks appears less similar to another model doing *exactly the same* tasks than it does to a model doing only simple tasks! 7/9
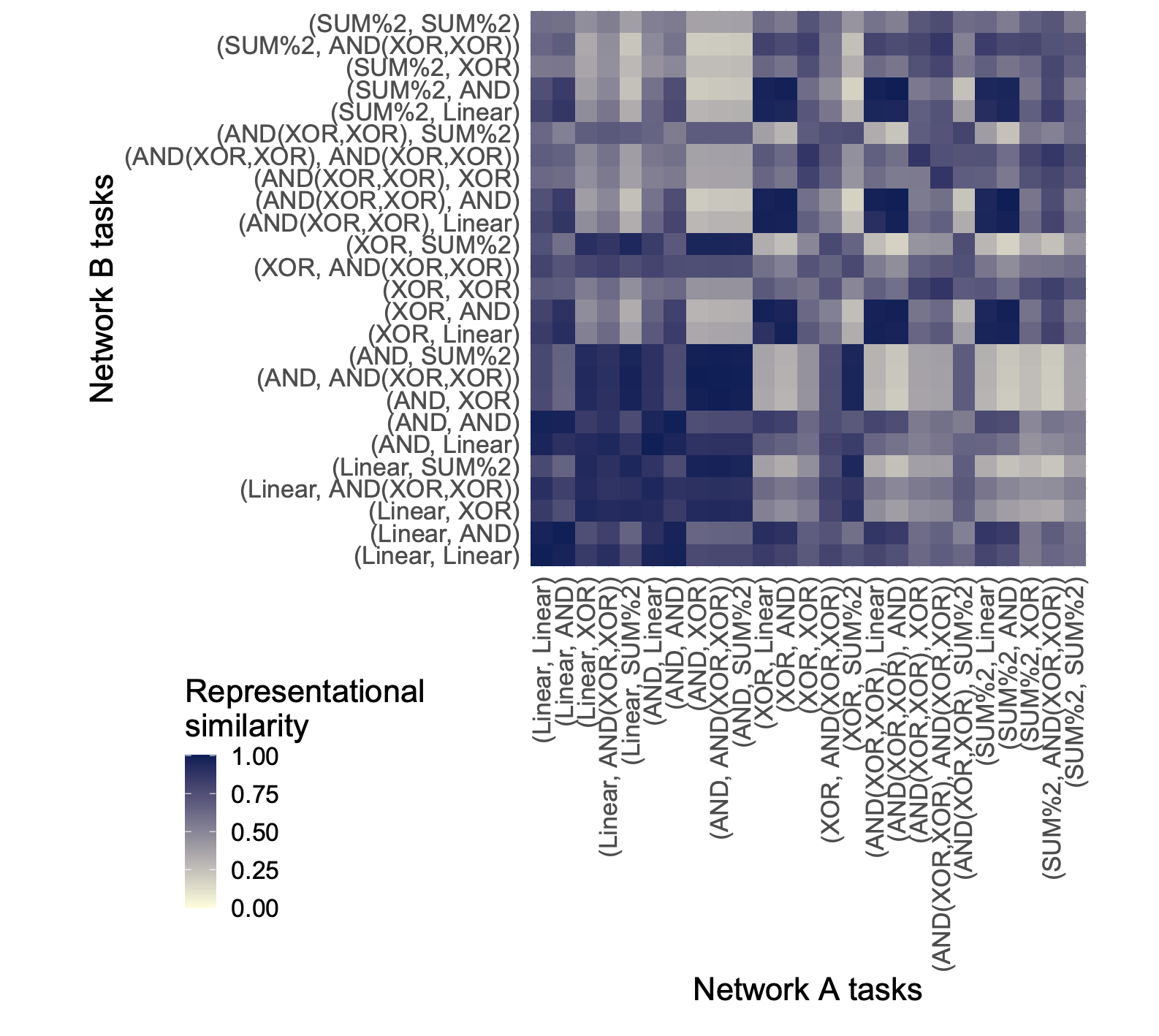
Why care about biases? They can hamper our ability to interpret what a system is “doing” from its representations; e.g. PCA, SAEs or other model simplifications will be biased towards particular aspects of the model’s computations. 6/9
We find similar biases in Transformers (on language tasks) and CNNs (on vision tasks), but also variability; e.g. biases can depend on architecture component (e.g. encoder vs. decoder) and many other properties. Feature prevalence and output position also bias representations! 5/9
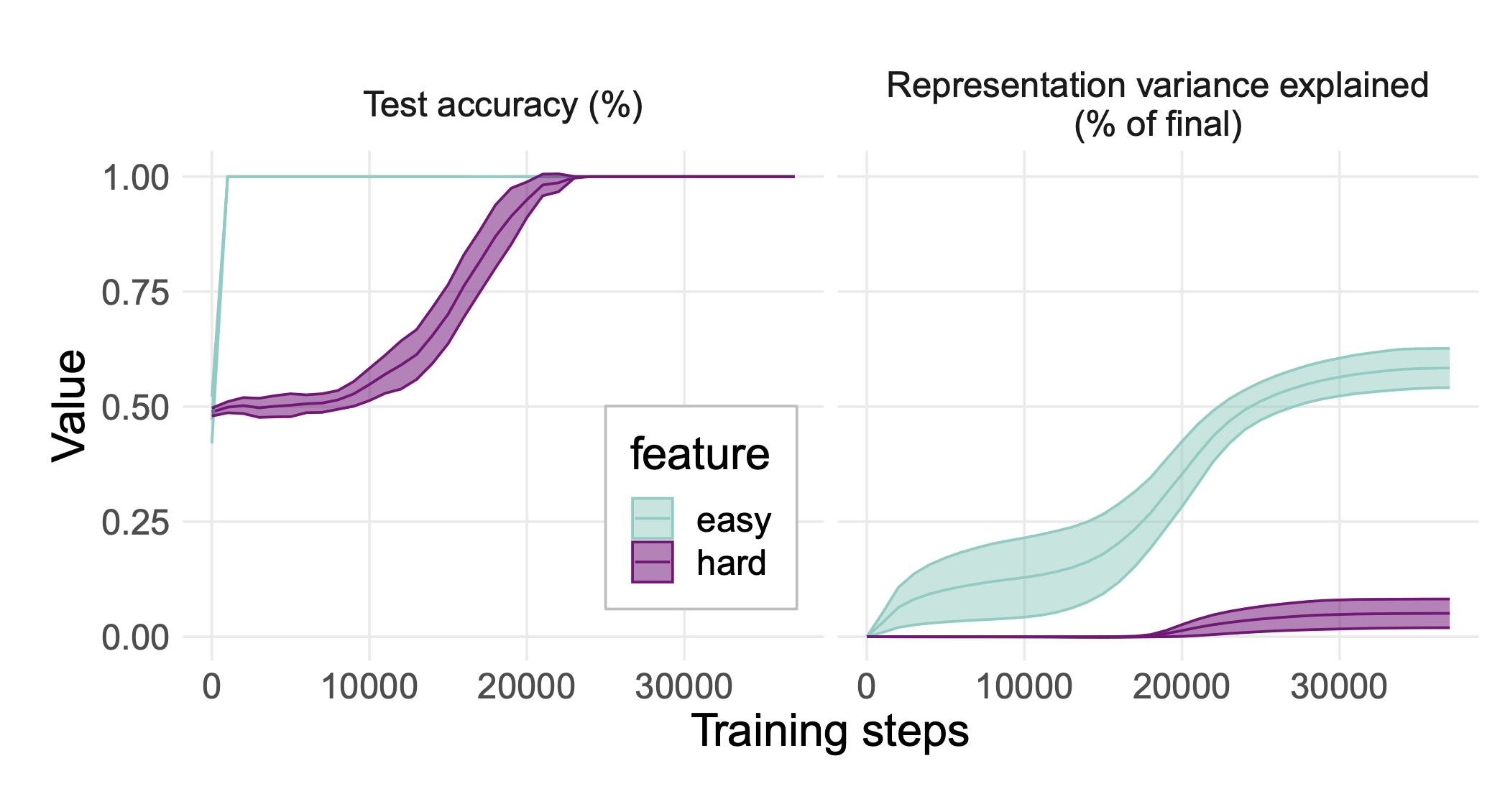
This effect seems to be driven by a combination of 1) the fact that the easy feature is learned first, and 2) the fact that there are more ways to represent a non-linear feature. The learning dynamics are quite interesting! 4/9
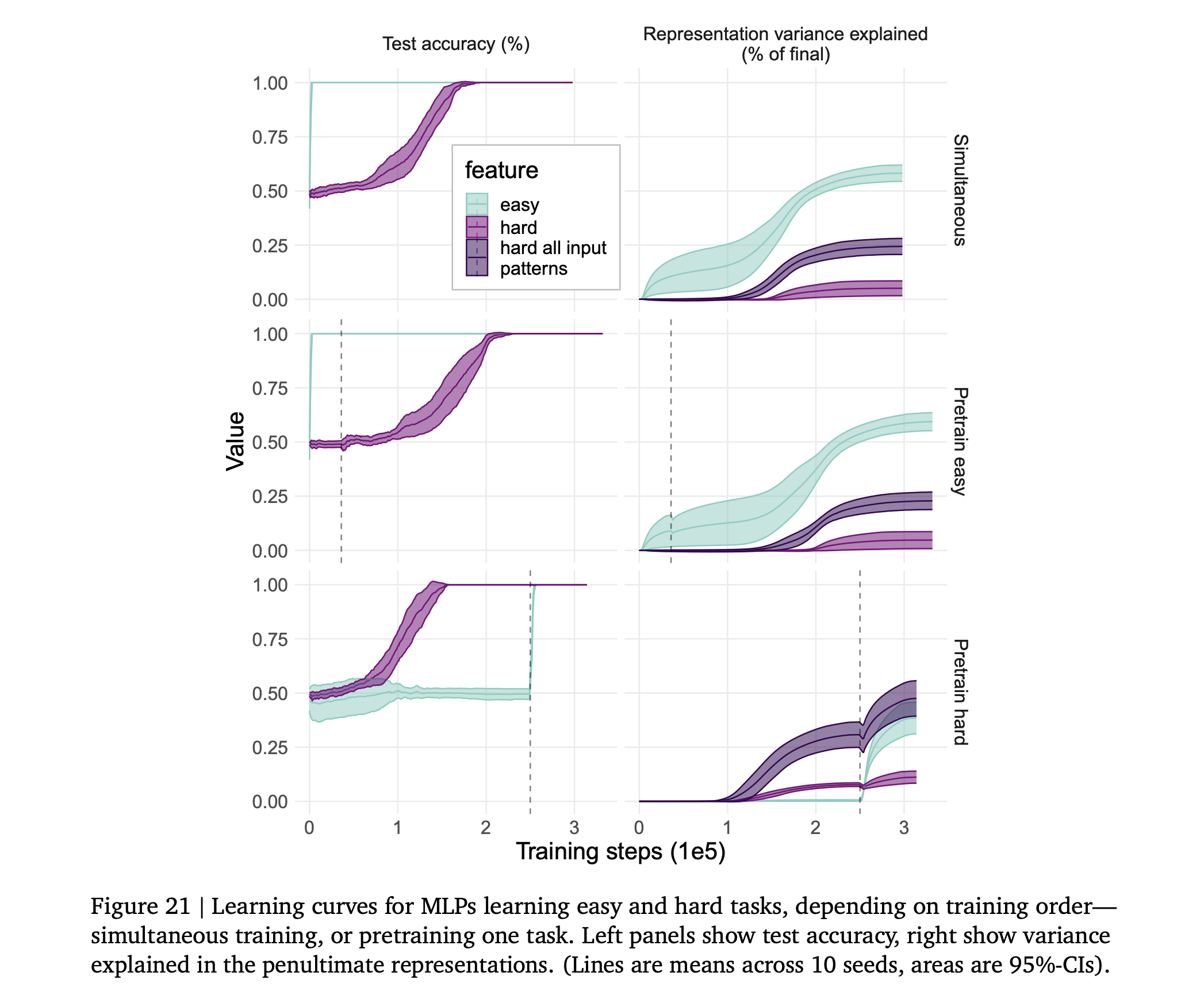
For example, if we train a model to compute a simple, linear feature and a hard, highly non-linear one, the easy feature is naturally learned first, but both are generalized perfectly by the end of training. However, the easy feature dominates the representations! 3/9
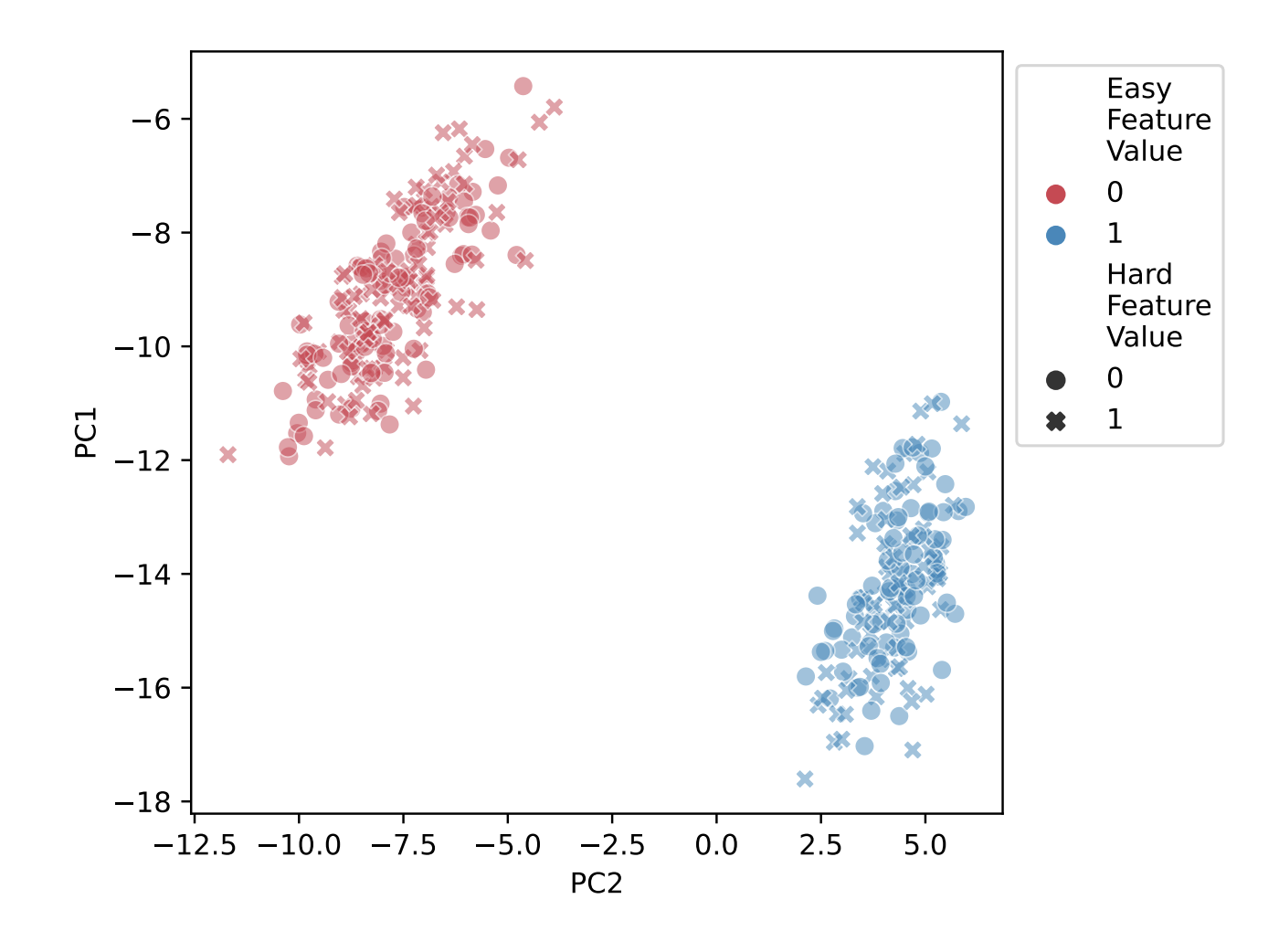
Our goal was to study the relationship between representation and computation in a setting where we know what a model is computing. To do so, we train MLPs, Transformers, and CNNs to compute multiple features from their inputs.
We manipulate data & feature properties, while preserving the features’ computational roles in the task. We then analyze the models’ internal representations, and find representations are strongly biased by these seemingly-irrelevant properties. 2/9
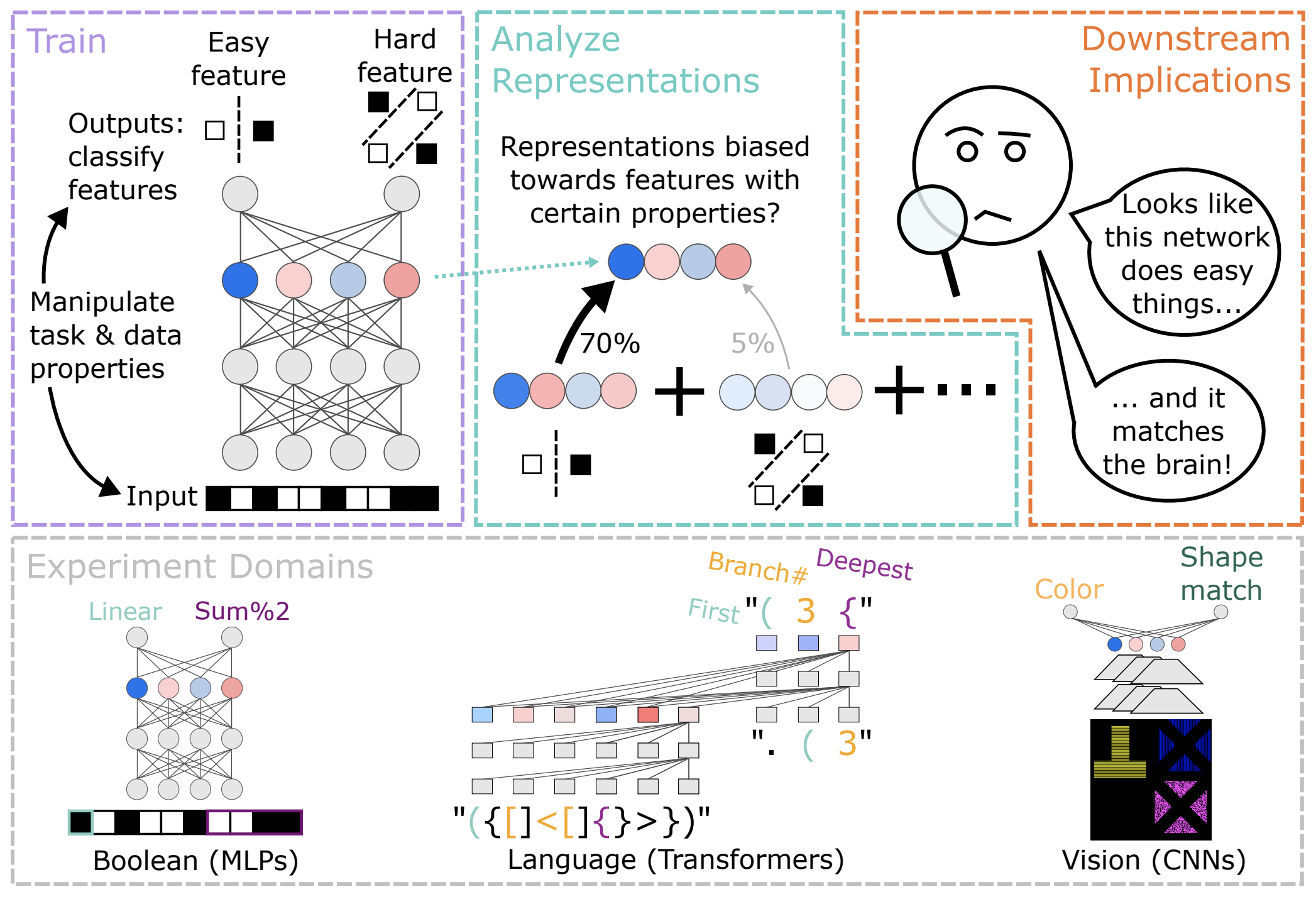
How well can we understand an LLM by interpreting its representations? What can we learn by comparing brain and model representations? Our new paper (https://arxiv.org/abs/2405.05847) highlights intriguing biases in learned feature representations that make interpreting them more challenging! 1/9
#intrepretability #deeplearning #representation #transformers
And thanks to all of the wonderful SIMA team who made this project take off! 5/5
However, our agent is still often unreliable, and doesn’t match human instruction-following performance yet (though some of our tasks are hard, and even human game players are far from perfect). SIMA is very much a work in progress; we’re looking forward to sharing more soon. But I’m excited about the progress we’ve already made towards scaling language grounding in video games (videos in this thread are from the agent). Check out our blog post and tech report for more! 4/5
We built our Scalable Instructable Multiworld Agent (SIMA) around the representations of internet-pretrained models, including a video model, and trained them primarily via instruction-conditioned BC, augmented with classifier-free guidance. We found that our agent learns many diverse skills, and shows positive transfer among environments (outperforming single-game-specialized agents), and even some zero-shot transfer of basic skills like navigation to held-out environments! 3/
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst