looks very useful
---
RT @davidhughjones
A little #rstats package to add a magnified inset to a #ggplot2 graph https://github.com/hughjonesd/ggmagnify
https://twitter.com/davidhughjones/status/1651230244555161601
Christian Gebhard 📊
Fascinated by small scales 🧬, large scales 🪐 and all things #data in between.
I explore #opendata using #opensource tools, such as #Rstats and #python.
#datascience #datavis #dataviz #opensource #fedi22 #openscience #science #astronomy #sciencecommunication #scicomm
Christian Gebhard 📊 boosted:
Christian Gebhard 📊 boosted:
I told a joke on a Zoom Meeting and no-one laughed.
It turns out I'm not remotely funny.
Christian Gebhard 📊 boosted:
In der aktuellen Folge des #Denkangebot Podcasts spreche ich mit @juliaebner über ihre Undercover-Recherche in zahlreichen Gruppen der extremen Rechten, darunter auch die TradWifes und Incels. Sie erklärt, warum deren toxische Narrative es immer wieder in den Mainstream schaffen. Das Gespräch war wirklich extrem aufschlussreich. Freue mich, wenn ihr reinhört! 📻 https://www.denkangebot.org/allgemein/julia-ebner-ueber-undercover-recherchen-bei-incels-und-rechtsextremen/
Christian Gebhard 📊 boosted:
People choose to adopt or read a textbook because (a) it's on a topic of interest and (b) they trust the author(s) to have curated and synthesized info into a single representation (the textbook). Now, imagine this: subscribing to a curated, synthesized, online source where the author is actively, frequently updating their curation and synthesis based on new evidence. Would you pay for that? Would you adopt it (perhaps a cheaper, time-limited version) for a course?
Christian Gebhard 📊 boosted:
Working on updating my textbook (https://lakens.github.io/statistical_inferences/) to Quarto. In this process, incorporating webexercises (https://psyteachr.github.io/webexercises/) by @debruine and @dalejbarr
so that you will be able to answer the questions online, and receive feedback (a much requested feature).
Christian Gebhard 📊 boosted:
Shuts down laptop: I think that’s enough internet for today.
Picks up phone: Let’s see what the pocket-sized internet is doing.
Christian Gebhard 📊 boosted:
Hello Mastodon art people! I’m Julia, an illustrator and naturalist from Germany. I’ve quit all social media a few years ago because addictive algorithms, ads, infinite scrolling and tracking surveillance were killing my creativity.
Mastodon is likely the last social media experiment I’ll try. Here are some birds for you, because although I’ve left Twitter, I love drawing birds.
Edit: Since this post, I've made my home here. :-)




Christian Gebhard 📊 boosted:
dear #mastodon,
which timeline/feature do you tend to spend the most time on?
p.s. please consider boosting for a more meaningful sample size.
:hmmm:
Christian Gebhard 📊 boosted:
I came across a neat browser extension today. It looks for "rel=me" links pointing to mastodon profiles, and puts it in a little list for you to review.
In other words, you visit a website, and if tells you if there are any mastodon accounts associated to the website.
@eliocamp
Yes! And I like the formula interface `y ~ x + z` or similar. Not sure if this is something r-specific, but every r user would probably recognize it.
Christian Gebhard 📊 boosted:
Here’s my current work-in-progress: a liver with a lot of poetic text! #SciArt #embroidery
Christian Gebhard 📊 boosted:
@eliocamp
How about the %>% pipe?
Christian Gebhard 📊 boosted:
@nhan
I'll check it out, thanks for pointing it out!
@florianjehn
Thanks! I've seen his introductory videos via the logseq website. I'll check his channel for further tutorials then.
@Logseq
@post
...linking isn't as quick and easy as it seems to be in logseq and dynamic queries are not possible, apart from the agenda view, tags are clumsy/limited and there's other issues that I cannot implement/adjust to my liking, since I'm not a lisp programmer.
Logseq seems to have everything out of the box, that I'm using in my workflow of several combined tools.
@post
Hi, thanks for the pointer. Interesting to see the pro/con points you collected.
Reading the comments below your list, I'm wondering whether it's worth investing time into learning it right now before seeing the direction the core Devs are going regarding privacy.
Would you, personally, start using it again at this point or would you look into other tools?
I'm coming from Emacs/org-mode and it's very mighty and all, but...
Christian Gebhard 📊 boosted:
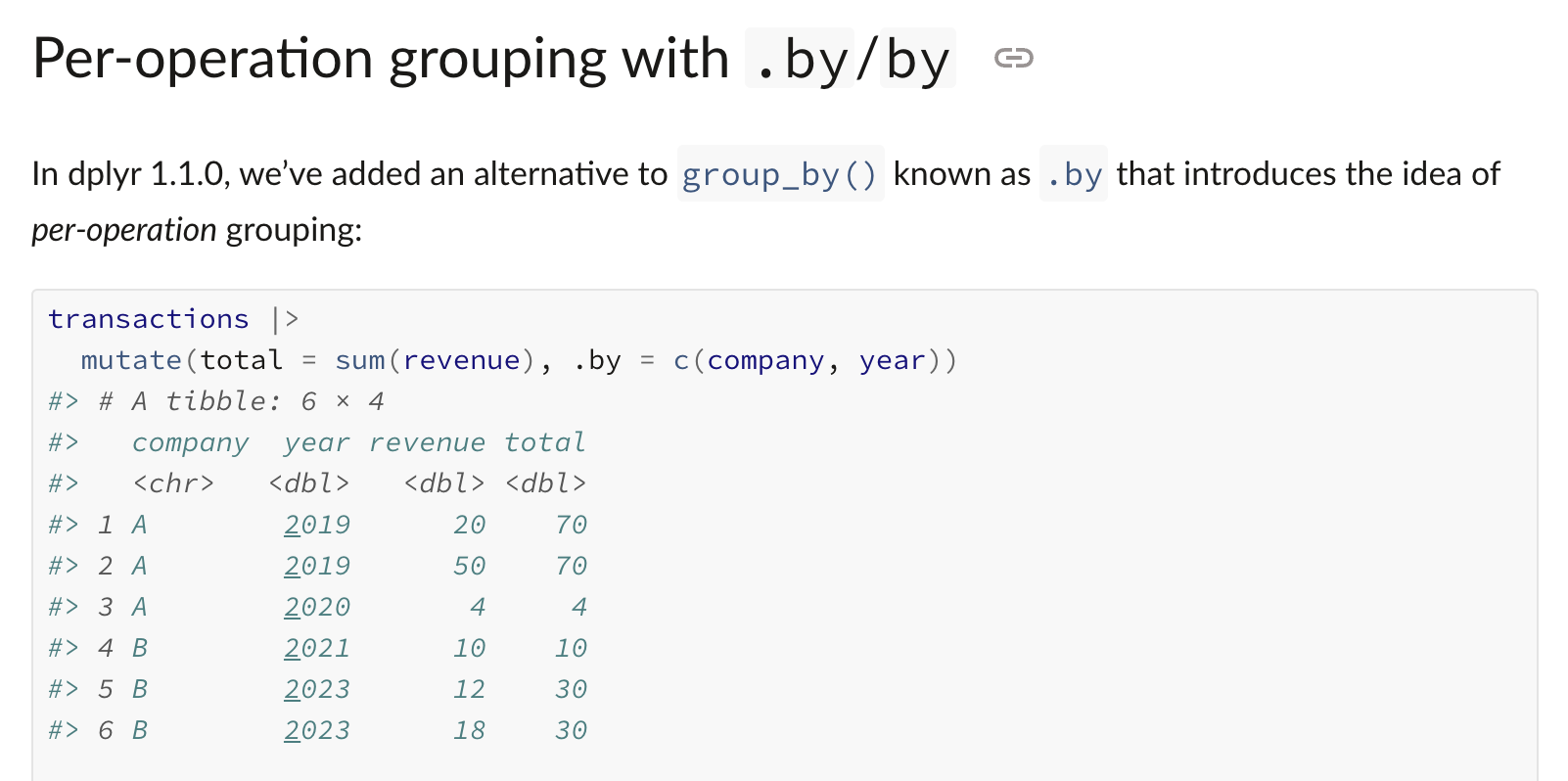
Updates in dplyr 1.1.0.
Bye bye `group_by()`, hello `.by`:
Hard decision choosing between @Logseq and obsidian... For now I'll go with #logseq. #opensource for the win!
This feels like a combination of all the best features from org-mode, TiddlyWiki, GTD & Anki with a clean interface. Mind == 🤯
Let's find out if this is too much for a single tool, but it looks thought through and well designed.
Anyone got tips or best practices I should follow from the start to not get lost in there? Thanks in advance 🙏
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst