UPDATE: A fluent Chinese speaker has informed me that this repo doesn’t have a link for the 200B anyways, making the question of its licensing a moot point.
Stella Biderman
Mathematician and AI researcher. Executive Director and Head of Research at EleutherAI She/her
The following models are *not* "open source" per @OpenSource's definition:
- MetaAI's OPT
- The BigScience Research Workshop's BLOOM
- Tsinghua University's GLM
- MetaAI's Galactica
They all have use-based restrictions that violate the definition of "open source." This doesn't mean they aren't open, as openness is a continuum and they’re certainly all much more open than is typical. However the bar that people typically reach for is “open source,” which they don’t meet.
There's a lot of misinfo about this out there, so here's the definitive list of the largest open source LLMs in the world:
1. Yandex's YaLM-100B
2. EleutherAI's GPT-NeoX-20B
= @GoogleOfficial's UL2-20B
= @nvidia's NeMo-Megatron-20B
All are licensed under Apache 2.0, except NeMo-Megatron which is licensed CC-BY.
I am not sure about Huawei's PanGu-α. The repo is in Chinese, but I think only the code is Apache 2.0. Here's the repo, if anyone speaks Chinese: https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/PanGu-%CE%B1
@tschfflr I just reply something like
“Hi [name]! Congrats on the company, it sounds interesting.
I’m not currently taking unpaid advisory roles. My rate is X USD/hour, with all meetings less than 30 minutes being charged as 30 minutes. If that’s amenable to you, I can find time to meet [date]. Let me know if you’d like to go forward with this.”
Where X is a random number between 0.001x and 0.005x my annual salary.
Stella Biderman boosted:
Google might have goofed up their unveil, but Bing isn’t really any better
Source: https://twitter.com/gaelbreton/status/1623280495894138882

Stella Biderman boosted:
ChatGPT gets treated like technological magic, but that ignores the humans behind the curtain that make it function.
OpenAI paid Sama to hire Kenyan workers at $1.32 to $2 an hour to review “child sexual abuse, bestiality, murder, suicide, torture, self harm, and incest” content. Their work made the tool less toxic, but left them mentally scarred. The company ended the contract when they found out TIME was digging into their practices.
@jazzbox35 @phoneme you’re missing the point… the “this is so dangerous we dare not release it” is a form of hype OAI actively engages in (and has done so for all their major models the past three or so years, see GPT-2, GPT-3, DALL-E, etc)
Replika is pretty explicitly marketed as a sexting AI on TikTok. I’ve been wondering how long it would take for this to happen.
https://www.vice.com/en/article/z34d43/my-ai-is-sexually-harassing-me-replika-chatbot-nudes
@TedUnderwood out of curiosity, did you not know the requirements for open source or did you not know the model licensing and requirements?
@TedUnderwood it’s not open source, as there are heavily use-cases restrictions in the model license
Stella Biderman boosted:
Oh yes. I've seen folks here hard at work for OpenAI trying prompt variations and dutifully hitting 👍 and 👎
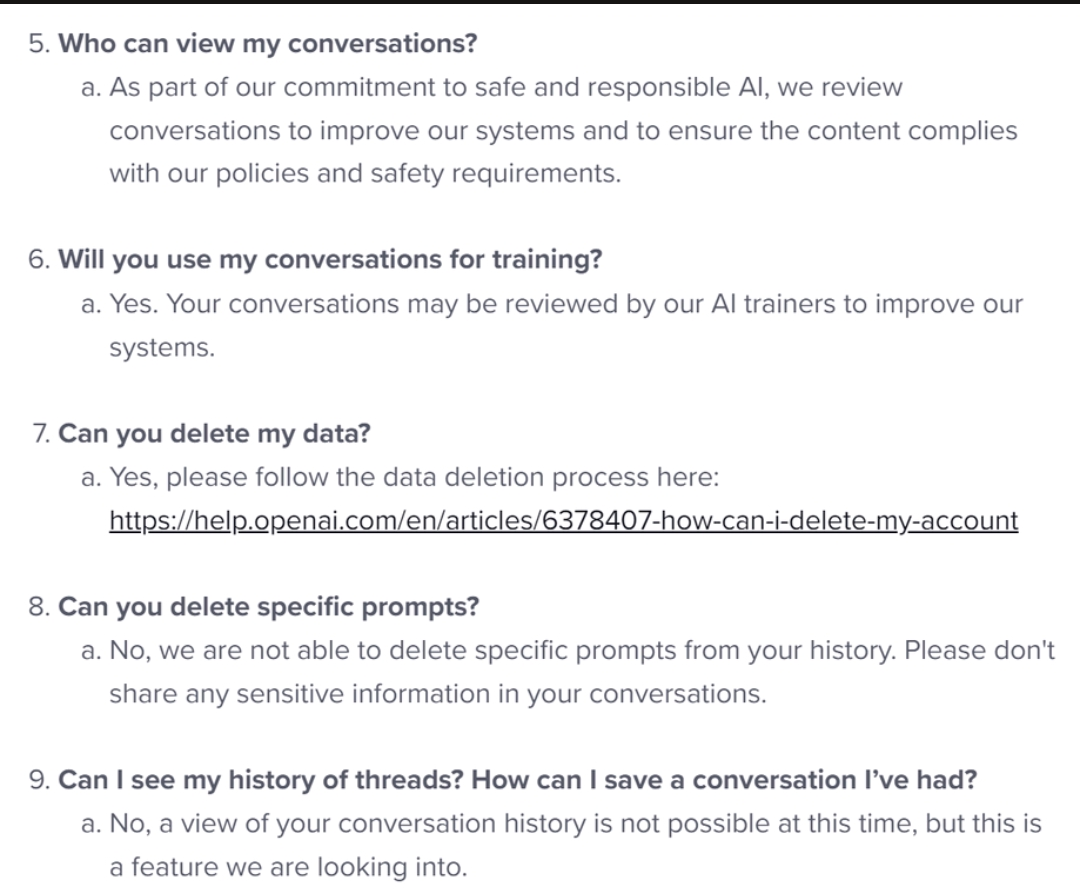
The #chatgpt FAQ couldn't be clearer: all prompts and 'conversations' are harvested for training, cannot be retrieved by you, and can only be deleted in bulk by relinquishing access (a dark pattern clearly designed to keep you on board)
PSA: "free research access" to ChatGPT by OpenAI means fuelling *their* research and giving *them* free access to distributed human cognition
Stella Biderman boosted:
New online portal streamlines requests for massive data sets at 16 federal agencies. https://www.science.org/content/article/accessing-u-s-data-research-just-got-easier
Phil Wang is a baller. Love this repsonse to some professional “influencers” promoting his https://github.com/lucidrains/PaLM-rlhf-pytorch repo
@matthewmaybe This is a work-in-progress. You’re welcome to invite these people to shoot me an email about their progress and we can discuss if it makes sense to join forces.
@matthewmaybe we have always paid attention to data licensing. The original Pile paper has a bunch of discussion of licensing and consent. For example, in the attached screenshot you can see a breakdown of types of consent in the original dataset. The real shift here is in the standards one holds oneself to. We didn’t expect the Pile to become so popular, and would have done things differently if we did.
@F_Vaggi thank you!
And finally, a look forward at the (tentative) titles of the papers I am most excited to write next year:
- Pythia: Interpreting Autoregressive Transformers Across Time and Scale
- Interpreting Transformers Across Depth with the Tuned Lens
- The Case for Evaluation as an Auditing Technique
- Causally Understanding the Importance of LLM Pretraining Data
- How to Make a LLM Forget How to Count
- The Pile V2: 1.5 TB of Fully Licensed English Language Data
- What does RLHF really do to a LLM?
The paper I am most embarrassed by is “Datasheet for the Pile.” I’m not embarrassed by it’s contents – quite the opposite – but rather by the fact that it was only released a year after the Pile was. This is 100% on me: doing dataset documentation work is unglamorous despite being essential, and I kept putting off finishing this. It was only when @alexhanna contacted me about whether it existed that I made the time to finish and release it.
Unfortunately it’s held back by a number of failures:
- the codebase is very difficult to use and does not support most HF models without custom hacking
- no publicly available LLMs were evaluated, putting the onus on people using it to run their own baselines
- evaluation of the benchmark tasks was limited
- discussion of these limitations were excluded from the paper
This paper will undoubtably be published in @jmlr or TACL and be cited a ton. But it could have been much better science.
The paper that was the biggest missed opportunity was “Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models.” This paper was a massive collaboration of hundreds of authors to collaboratively make a really hard LLM benchmark. I thought that this was a really excellent opportunity and hand wrote what is possibly the hardest multiple choice math LLM task in the world for it.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst