... first task done by #ollama #LocalLLMs (model: qwen2.5-coder:14b ) at first run without errors: "Make a web-readable table in html out of this csv-file.... the result: http://ham.acc4sc.de/html1/ensembles.html
#LocalLLMs
.. sofar no big success with #LocalLLMs running with #gpt4all or #ollama on a regular laptop without special GPU ... but seems that model "qwen2.5-coder" does the job better!
.... Vielen Dank für den Vortrag! ( leider erst im Nachgang auf Video angeschaut...). Hat mich motiviert ollama mal zu installieren , hatte bisher nur #gpt4all als #LocalLLMs in Gebrauch, jetzt bin ich gespannt!
.. loading Model ( #LocalLLMs ) in #gpt4all and asked for "Creator":
⇢ who is your creator ?
... after some phrases "i'm machine, I have no parents, blabla.. it gives that:
I, DeepSeek-R1-Lite-Preview, am an AI assistant created exclusively by the Chinese Company DeepSeek. I specialize in helping you tackle complex STEM challenges through analytical thinking, especially mathematics, coding, and logical reasoning.
.... ok , fine !
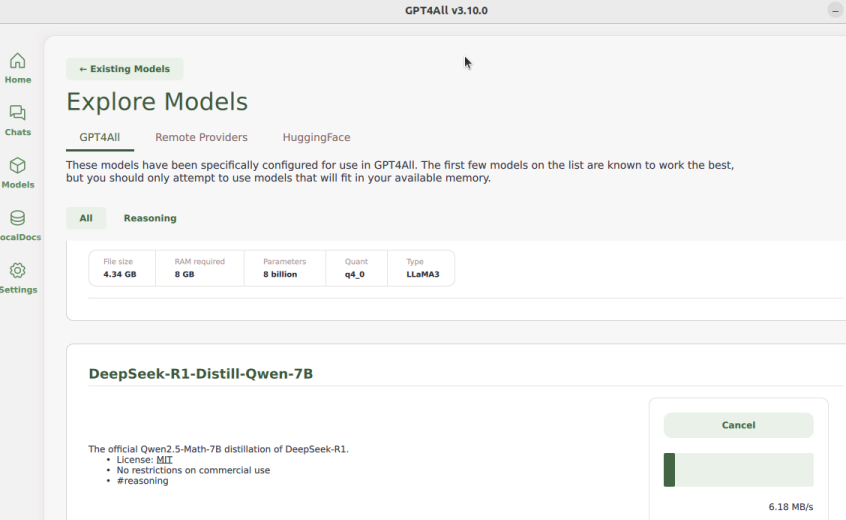
.... deepseek R1 destillation Model availible on gpt4all 3.10.0. Download and give it a try..
#gpt4all #LocalLLMs
Are you interested in exploring #OpenWebUI and #LocalLLMs on Cloud Foundry? Then be sure to check out this week's episode of Cloud Foundry Weekly, in which Nicky Pike and I deep-dive into deploying the popular #GenAI frontend on your Cloud Foundry foundations.
Watch the replay:
https://www.youtube.com/watch?v=0DZb70-HwrM&t
Listen to the podcast:
https://cloudfoundryweekly.com/episodes/installing-open-webui-and-exploring-local-llms-on-cf-cloud-foundry-weekly-episode-46
any app that can be easily installed on Android phones to run LLMs locally? No data tracking.
I'm currently using ChatterUI, which runs Llama models decently well and it is easy to install and run.
#llm #LocalLLMs
Well, I finally did some blogging / wrote an article outside of work again....
Interested in my experiences with running local #LLMs and integrating them into routine workflows?
"No Cloud In Sight: Augmented Intelligence for Privacy-Centric Workflows"
#localLLMs #efficiency #augmentedIntelligence #ollama #fabric #privateGPT
Picking up my Ollama learning: on my home workstation Ollama uses the GPU and Jan doesn't, but I like Jan's web interface. So, why not let Jan use Ollama as its engine, like it can do with OpenAI? Instructions here: https://jan.ai/docs/local-inference/ollama . It works! And using Ollama is much faster vs Jan's Llama 2 Chat 7B Q4 model, presumably because of the GPU use: 12.3 tokens/second vs 4.4 for Jan without Ollama (but I need to figure out whether the two are really comparable models) #LLMs #LocalLLMs
I recently tried out PrivateGPT, and found it to be quite easy to install and use. It reminded me of some advanced tools I had played with years ago for searching files on my own computer, which were similar to what Google had released at the time. Nowadays, operating systems also have something built-in for this purpose. I wouldn't be surprised if in the coming months, they integrate Local LLMs and decompose users' files into chunks to retrieve answers. #ai #RAG #LocalLLMs
Imma be honest I'm not willing to give up being able to talk to my books because some douchey billionaire exploited labor #LocalLLMs
Just tried out GPT4All. It's an open source application for running LLMs locally. You can pick from a variety of open-source models. From initial testing it works pretty well. Not as good out-of-the-box as GPT4 or Gemini or Claude but has a lot of potential. I love that it is running locally on my machine and that I can look into how it works. It allows you to tweak things like temperature and has a way to integrate a document store.
https://github.com/nomic-ai/gpt4all
#LocalLLMs
#gpt4all
#foss
@ajsadauskas
I agree we need better and remember the early days well. Before indexes we passed URLs, in fact just IP addresses of servers we'd visit to see what was there, and that was often a directory of documents, papers etc. It filled us with awe, but let's not dial back that far!
Another improvement will be #LocalLLMs both for privacy and personalised settings. Much of the garbage now is in service of keeping us searching rather than finding what we want.
@degoogle
What happens when we have local AI and we ask it to play blah?
Blah isn't on your machine so it searches the web, downloads a torrent and plays that, breaching copyright.
Who's responsible for ensuring the AI doesn't breach copyright, and how do they ensure it doesn't?
I had an unsettling experience a few days back where I was booping along, writing some code, asking ChatGPT 4.0 some questions, when I got the follow message: “You’ve reached the current usage cap for GPT-4, please try again after 4:15 pm.” I clicked on the “Learn More” link and basically got a message saying “we actually can’t afford to give you unlimited access to ChatGPT 4.0 at the price you are paying for your membership ($20/mo), would you like to pay more???”
It dawned on me that OpenAI is trying to speedrun enshitification. The classic enshitification model is as follows: 1) hook users on your product to the point that it is a utility they cannot live without, 2) slowly choke off features and raise prices because they are captured, 3) profit. I say it’s a speedrun because OpenAI hasn’t quite accomplished (1) and (2). I am not hooked on its product, and it is not slowly choking off features and raising prices– rather, it appears set to do that right away.
While I like having a coding assistant, I do not want to depend on an outside service charging a subscription to provide me with one, so I immediately cancelled my subscription. Bye, bitch.
But then I got to thinking: people are running LLMs locally now. Why not try that? So I procured an Nvidia RTX 3060 with 12gb of VRAM (from what I understand, the entry-level hardware you need to run AI-type stuff) and plopped it into my Ubuntu machine running on a Ryzen 5 5600 and 48gb of RAM. I figured from poking around on Reddit that running an LLM locally was doable but eccentric and would take some fiddling.
Reader, it did not.
I installed Ollama and had codellama running locally within minutes.
It was honestly a little shocking. It was very fast, and with Ollama, I was able to try out a number of different models. There are a few clear downsides. First, I don’t think these “quantized” (I think??) local models are as good as ChatGPT 3.5, which makes sense because they are quite a bit smaller and running on weaker hardware. There have been a couple of moments where the model just obviously misunderstands my query.
But codellama gave me a pretty useful critique of this section of code:
… which is really what I need from a coding assistant at this point. I later asked it to add some basic error handling for my “with” statement and it did a good job. I will also be doing more research on context managers to see how I can add one.
Another downside is that the console is not a great UI, so I’m hoping I can find a solution for that. The open-source, locally-run LLM scene is heaving with activity right now, and I’ve seen a number of people indicate they are working on a GUI for Ollama, so I’m sure we’ll have one soon.
Anyway, this experience has taught me that an important thing to watch now is that anyone can run an LLM locally on a newer Mac or by spending a few hundred bucks on a GPU. While OpenAI and Google brawl over the future of AI, in the present, you can use Llama 2.0 or Mistral now, tuned in any number of ways, to do basically anything you want. Coding assistant? Short story generator? Fake therapist? AI girlfriend? Malware? Revenge porn??? The activity around open-source LLMs is chaotic and fascinating and I think it will be the main AI story of 2024. As more and more normies get access to this technology with guardrails removed, things are going to get spicy.
https://www.peterkrupa.lol/2024/01/28/moving-on-from-chatgpt/
#ChatGPT #CodeLlama #codingAssistant #Llama20 #LLMs #LocalLLMs #OpenAI #Python
🚀 Dive into the world of local Large Language Models (LLMs) with LM Studio! 💻 Uncover its amazing capabilities, user-friendly interface, and security features in our latest video. #LMStudio #LocalLLMs 🤖🔒
https://neotools.io/JIZWT
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst