Reranking text documents with Ollama and Qwen3 Reranker model - in Go:
https://www.glukhov.org/post/2025/06/reranking-with-ollama-qwen3-reranker-golang/
#go #ollama #rag #reranking #qwen3 #llm #ai
#RA%C4%9E
https://www.galiciaconfidencial.com/noticia/297614-rag-mesa-exploran-politica-activa-recuperar-galego
#RAG / Algo é algo!

Boost your enterprise #GenAI with better #RAG pipelines!
Learn how to combine semantic, relational & vector search for more accurate #LLM results — all on scalable #opensource infra. Watch Thorsten Neumann show how it’s done.
Click here: https://youtu.be/_dDKhKgLDBI
Spring AI: retrieval augmented generation
Spring AI , который только недавно получил первую стабильную версию, уже предоставляет довольно много возможностей для работы с RAG ( retrieval augmented generation ). Благодаря этому подходу нейросеть перед тем, как дать ответ на запрос пользователя, выполнит поиск подходящей информации в векторном хранилище. Причём каждый документ хранится не в виде текста, а в виде массива чисел (т.н. «векторов»). Процесс преобразования различных документов в такой векторный формат выполняется опять же с помощью LLM и называется embedding («встраивание»). Хорошая новость заключается в том, что всё это можно легко сделать с помощью Spring AI.
https://habr.com/ru/articles/920992/
#spring_ai #rag #kotlin #java #openai #pgvector #postgres #spring
Jay Knowledge Hub: от прототипа до промышленного PaaS создания баз знаний полного цикла
Привет, Хабр! Меня зовут Никита, я руководитель команды разработки умного поиска на основе генеративного AI в Just AI. В этой статье я расскажу о нашем опыте в умный поиск — как от mvp RAG-сервиса для Q&A бота нашей службы поддержки мы пришли к облачной платформе Jay Knowledge Hub (сокращенно KHUB), которая помогает нашим клиентам автоматизировать поиск по различным источникам знаний.
https://habr.com/ru/companies/just_ai/articles/920966/
#rag #база_знаний #llm #искусственный_интеллект #работа_с_данными #работа_с_документацией #paas
"#RAG – Mach die #KI schlauer mit deinem Wissen": Bericht von einem Workshop vom @scdh Münster: https://www.dh.uni-muenster.blog/rag-mach-die-ki-schlauer-mit-deinem-wissen/ #LLM #Tools #Arbeitsalltag
NEW Journal Article: "Retrieval-Augmented Generation of Event Collections from Web Archives and the Live Web" #AI #RAG #webarchives @internetarchive https://link.springer.com/article/10.1007/s00799-025-00419-7
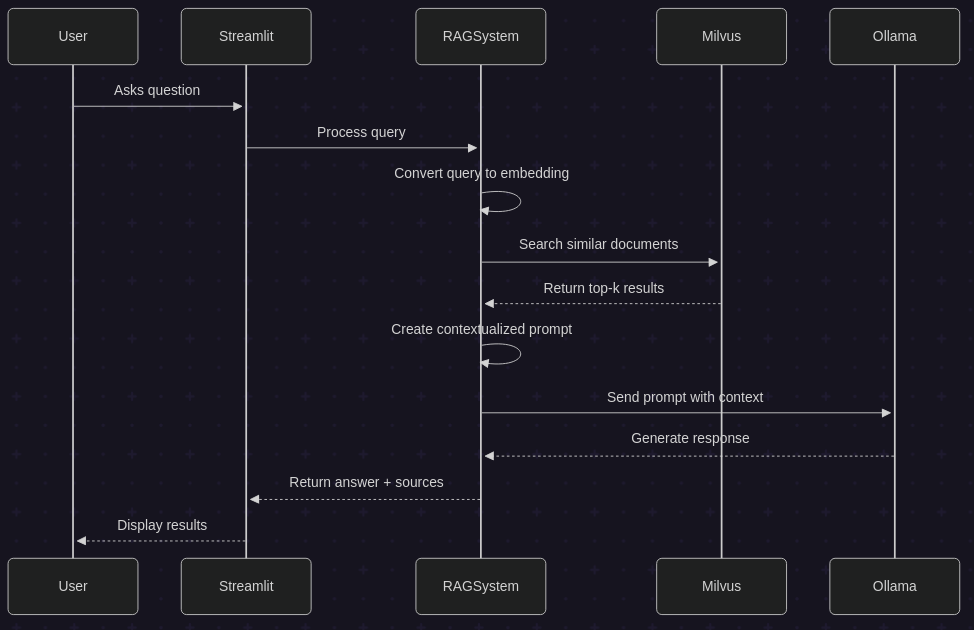
I decided to give it a try and write a simple RAG-based documentation-to-chatbot procedure as an example for reviewing the procedure and hopefully providing a quick and interesting way of learning RAG.
This post walks you through the development of a RAG system from developing a vector database to creating a simple application built on Ollama, Milvus, and Streamlit.
See the post here: https://masoudmim.github.io/blog/2025/rag-system/
#RAG #LLM #MachineLearning
#VectorDatabase #Milvus #Ollama #Streamlit
Telegram-бот с интеграцией AnythingLLM + LM Studio
В этом проекте создаем Telegram-бота, который взаимодействует с AnythingLLM — инструментом для работы с языковыми моделями (LLM) и LM Studio (используется как инструмент для загрузки документов и создания RAG архива). Покажу как использовать API AnythingLLM для бота и настроим взаимодействие с LM Studio, через которую предоставляется доступ к общению с ИИ-моделью. Самое главное в этой связке, что все отрабатывается локально без передачи файлов сторонним сервисам, что делает решение удобным для команд, которые хотят использовать ИИ в своих рабочих процессах, но не отправлять файлы во вне. Полистать...
Разработка LLM моделей для обновления кода приложений на более высокие версии фреймворков или языков программирования
В этой статье я планирую исследовать, как можно использовать большие языковые модели (LLM) для миграции проектов между различными фреймворками. Применение LLM в задачах на уровне репозитория — это развивающаяся и всё более популярная область. Миграция кода со старых, устаревших фреймворков на новые является одной из ключевых задач в крупных корпоративных проектах.
https://habr.com/ru/articles/920424/
#llm #rl #expressjs #nestjs #python #gpt #rag #llama #finetuning
💻 Das bringt euch unser kostenloses Online-#Lernangebot „Fit4KI“!
In kurzen Einheiten präsentieren wir euch Erfahrungen aus der #CivicCoding-Projektberatung, zum Beispiel:
✅ Wie ihr ethische KI-Assistenten mit #RAG entwickelt
✅ Wie sich die #Fördermittelsuche mit #KI automatisieren lässt
✅ Welche #Tools helfen, KI #ressourcenschonend einzusetzen
Wir greifen Herausforderungen gemeinwohlorientierter Projekte auf und geben euch praxisnahe Impulse an die Hand.
🎯 Neugierig? https://www.civic-coding.de/angebote/online-lernangebot-fit4ki
Introducing haiku.rag - A SQLite-based RAG client & server that keeps your data local!
- Pure SQLite - no servers needed
- Hybrid search
- Multiple embedding providers (Ollama, OpenAI, VoyageAI)
- Auto file monitoring
- MCP server
Retrieval Augmented Generation (RAG) wird in Unternehmen und Forschung immer relevanter. Was sich hinter dem Konzept verbirgt, erläutert der aktuelle Beitrag im DH-Blog an der Universität Münster:
https://www.dh.uni-muenster.blog/rag-mach-die-ki-schlauer-mit-deinem-wissen/
Останется ли это правдой завтра? Как проверка устойчивости фактов помогает LLM стать честнее и умнее
Привет, Хабр! Мы в команде «Вычислительная семантика» в AIRI сфокусированы на исследовании галлюцинаций и решении проблем доверительной генерации. Мы учимся находить галлюцинации и бороться с ними. Большие языковые модели (LLM) вроде GPT-4 стали незаменимыми помощниками в повседневной жизни — от генерации текстов до поддержки в кодинге и ответов на вопросы. Однако у них есть ахиллесова пята: они часто галлюцинируют. В этом посте мы разберем нашу последнюю работу Will It Still Be True Tomorrow? , посвященную тому, как на надёжность моделей влияет феномен неизменного вопроса (evergreen question) — то есть вопроса, ответ на который не зависит ни от времени, когда вы его задаёте, ни от места, вопроса про факт, который зафиксирован в истории и не меняется от обстоятельств. В рамках этой работы мы совместно с MWS AI собрали датасет изменяемых и неизменных вопросов EverGreenQA ( открытый доступ ) , обучили классификатор на базе многоязычного энкодера E5, и применили его для оценки собственных знаний модели. Наши результаты показывают, что большие языковые модели чаще всего правильно отвечают на неизменные вопросы, не прибегая к помощи RAG пайплайна. Теперь обо всем по порядку.
非構造データを価値化する!DNPの構造化AI × RAG 体験デモアプリを作ってみた
https://qiita.com/dnp-nishikawa/items/3a9723a4666342cc4015?utm_campaign=popular_items&utm_medium=feed&utm_source=popular_items
RAG uses vector search to ground LLMs in real data, reducing hallucinations. #AI #RAG https://zilliz.com/blog/top-5-open-source-vector-search-engines
🌕 為AI撰寫文件:最佳實踐
➤ 如何優化您的文件,讓AI更有效地為您服務
✤ https://docs.kapa.ai/improving/writing-best-practices
這篇文章探討瞭如何撰寫適合AI系統(特別是像Kapa這樣的RAG系統)使用的文件。重點在於文件品質對AI回應準確性的影響,以及如何透過優化文件結構和內容,使其更易於AI理解和處理。文章強調了清晰、自足、語義明確的內容對於提升AI效能的重要性,並提供了具體建議,例如使用標準的HTML標籤、避免PDF格式、簡化頁面結構等。
+ 這篇文章對技術文件撰寫提供了很有價值的見解,特別是在AI時代,如何讓機器也能理解我們的內容至關重要。
+ 我一直覺得文件撰寫很麻煩,但這篇文章讓我意識到優質的文件不僅對使用者重要,對AI系統也至關重要,值得花時間優化。
#人工智慧 #文件 #內容優化 #RAG (Retrieval-Augmented Generation)
RAG на практике: чат-бот для корпоративной вики
Привет! Меня зовут Алиса, я руковожу командой машинного обучения в Банки.ру и занимаюсь проектами, связанными с внедрением ИИ. В этой статье расскажу, как мы создавали чат-бота для работы с внутренней документацией: какие задачи решали, с какими сложностями столкнулись, что сработало, а что — нет. Надеюсь, наш опыт окажется полезным тем, кто только начинает путь или уже в процессе — возможно, это поможет сэкономить время и нервы.
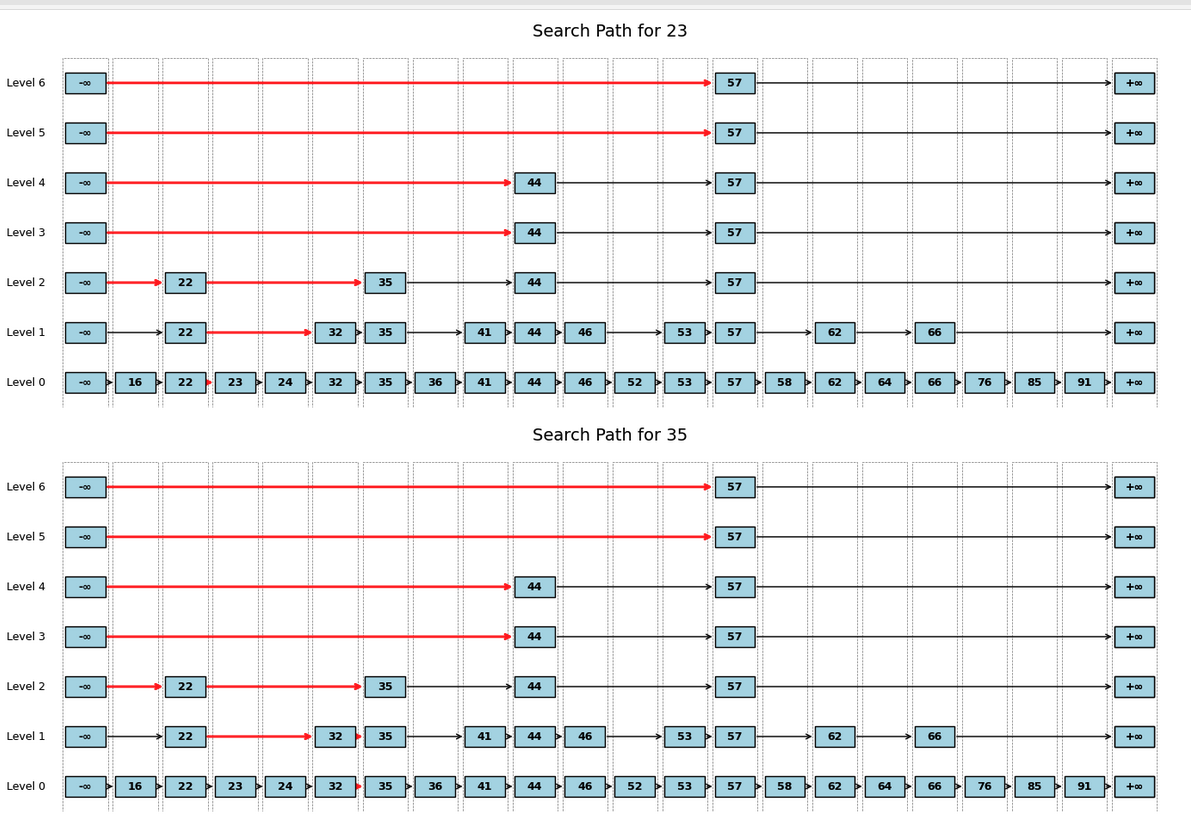
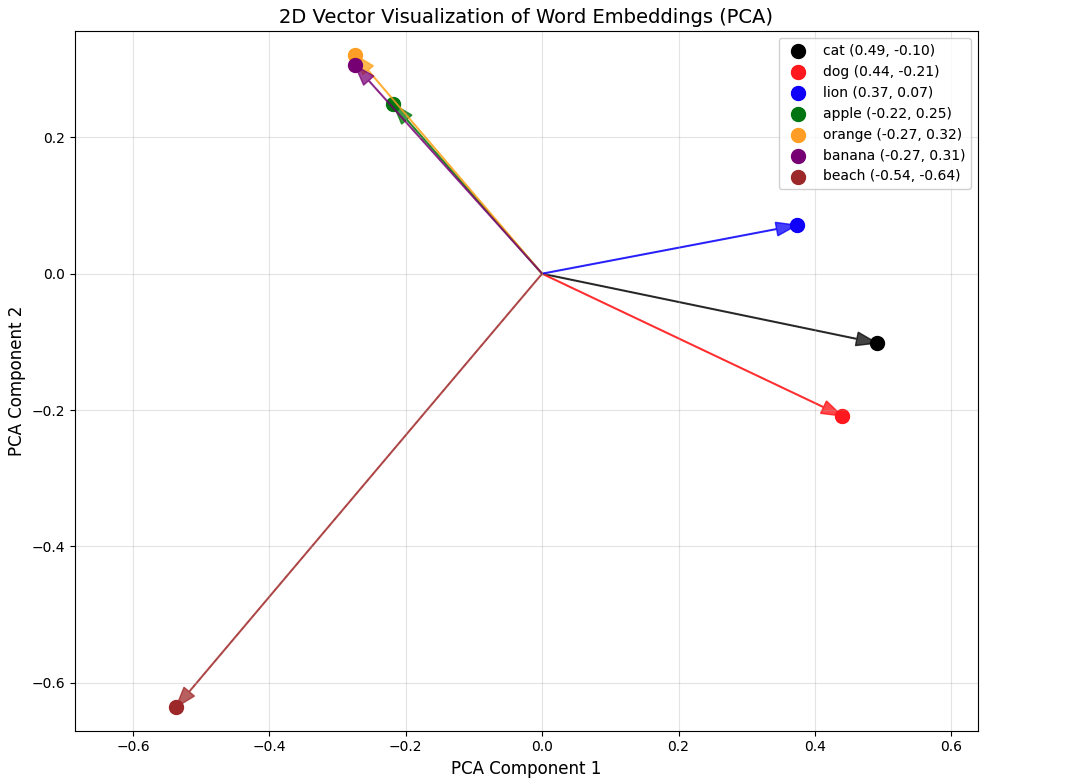
Playing with @duckdb, #embeddings and #skiplists. Got exercise to understand how #RAG works under the hood.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst