
Google updates its Googlebot/crawlers file size limit help document again for clarification https://www.seroundtable.com/google-crawler-file-size-limits-doc-clarified-40915.html
#googlebot


#Development #Reports
Google lists Googlebot file limits · Do Google’s crawling limits affect your website? https://ilo.im/16adna
_____
#Business #Google #SearchEngine #Crawlers #Googlebot #Files #HTML #PDF #WebDev #Frontend

Testing tool simulates Google's 2MB HTML limit as SEO professionals assess crawling impact: Dave Smart added 2MB truncation feature to Tame the Bots fetch tool on February 6, enabling technical SEO professionals to simulate Googlebot's reduced file size limits. https://ppc.land/testing-tool-simulates-googles-2mb-html-limit-as-seo-professionals-assess-crawling-impact/ #SEO #GoogleBot #HTML #Crawling #DigitalMarketing
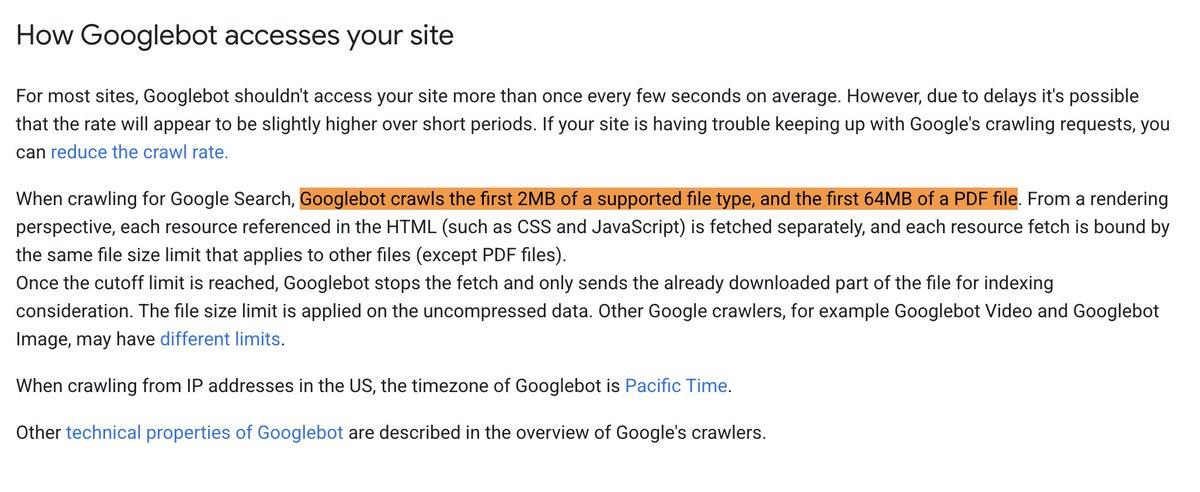
Google clarifies Googlebots crawling limit of 15MB (old) but what is new is 2MB for other file types and 64MB for PDF documents https://www.seroundtable.com/googlebot-file-limits-40876.html
Google's @methode and @geekonaut discuss the biggest crawling challenges for Googlebot in 2025 https://www.seroundtable.com/googles-top-crawling-challenges-for-2025-40865.html

A new Googlebot named "Google Messages" was added to Google's documentation https://www.seroundtable.com/new-googlebot-google-messages-40798.html


Vers un #web toujours plus fragile https://siecledigital.fr/2025/12/31/etude-cloudflare-2025-un-web-plus-vaste-plus-automatise-et-plus-fragile
À eux seuls, les #bots représenteraient près de 30% du trafic web mondial, avec des pics capables de générer des volumes comparables à des attaques DDoS
#Googlebot est le #crawler dominant avec 4,5% des requêtes HTML
En 2025, le #smartphone s’impose avec environ 43% des utilisateurs mondiaux, contre 57% pour les ordinateurs. #Android domine largement le trafic mobile à l’échelle mondiale, tandis qu’#iOS conserve une position forte


Google internally proposed 6 options for (or not for) controlling how AI can use your content and blocking controls https://www.seroundtable.com/google-options-publishers-ai-controls-40462.html via @natejhake
New Google user agent: Google-Pinpoint https://www.seroundtable.com/google-pinpoint-user-agent-40426.html

New Google user agent, Google-CWS Chrome Web Store, added to the user-triggered fetchers list https://www.seroundtable.com/google-chrome-web-store-cws-40368.html


So, someone in the issue made me realize that some bots impersonate the user agents of big actors, such as Googlebot. I checked my webserver logs and found a lot of them actually!
I liked the challenge, so I just wrote an article about how to do this in less than 40 SLOC 🏆
https://reaction.ppom.me/filters/useragent-impersonators.html
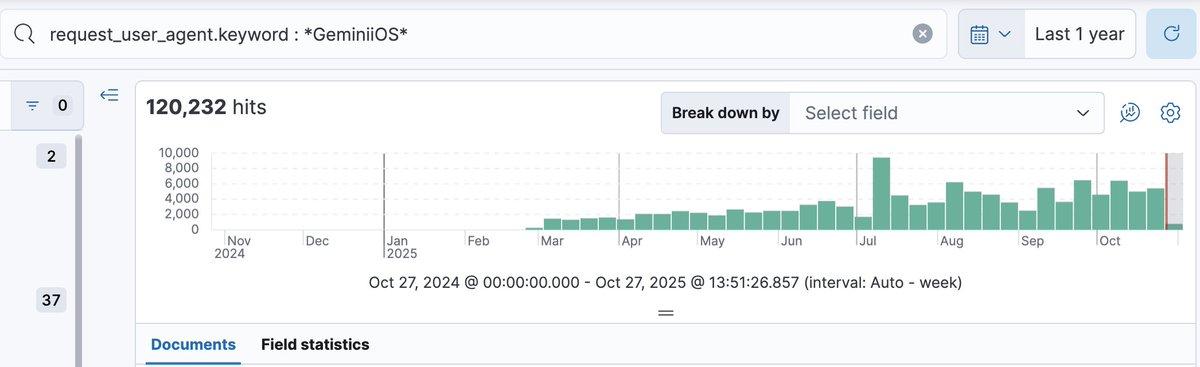
An undocumented Google user agent named geminiios was discovered https://www.seroundtable.com/geminiios-google-user-agent-40333.html


@jackyan I suspect they created #GoogleOther to break the crawling / robots.txt / nettiquette rules without getting too many repurcusions on #GoogleBot.
Google Read Aloud user agent service updates to list Google services that use it plus how AI is used and not used https://www.seroundtable.com/google-read-aloud-user-agent-products-40269.html

Google added Google NotebookLM to the list of Google crawlers, under the list of user-triggered fetchers https://www.seroundtable.com/google-notebooklm-user-triggered-fetchers-40236.html



Không phải nội dung nào cũng nên xuất hiện trên Google! Noindex giúp bạn kiểm soát điều đó.
Tìm hiểu chi tiết tại: https://autoranker.net/noindex-la-gi/


Early results are not promising. I've had a handful of HEAD requests in the past day. Only 2 appear legitimate, in that they hit genuine page URLs. The others were attempts to exploit WordPress vulnerabilities.
It makes me think that there's one well-behaved 'bot drowned in a sea of ill-behaved ones.
I'm just instrumenting #djbwares httpd to log GET and HEAD differently. I wonder what I'll see.
Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst