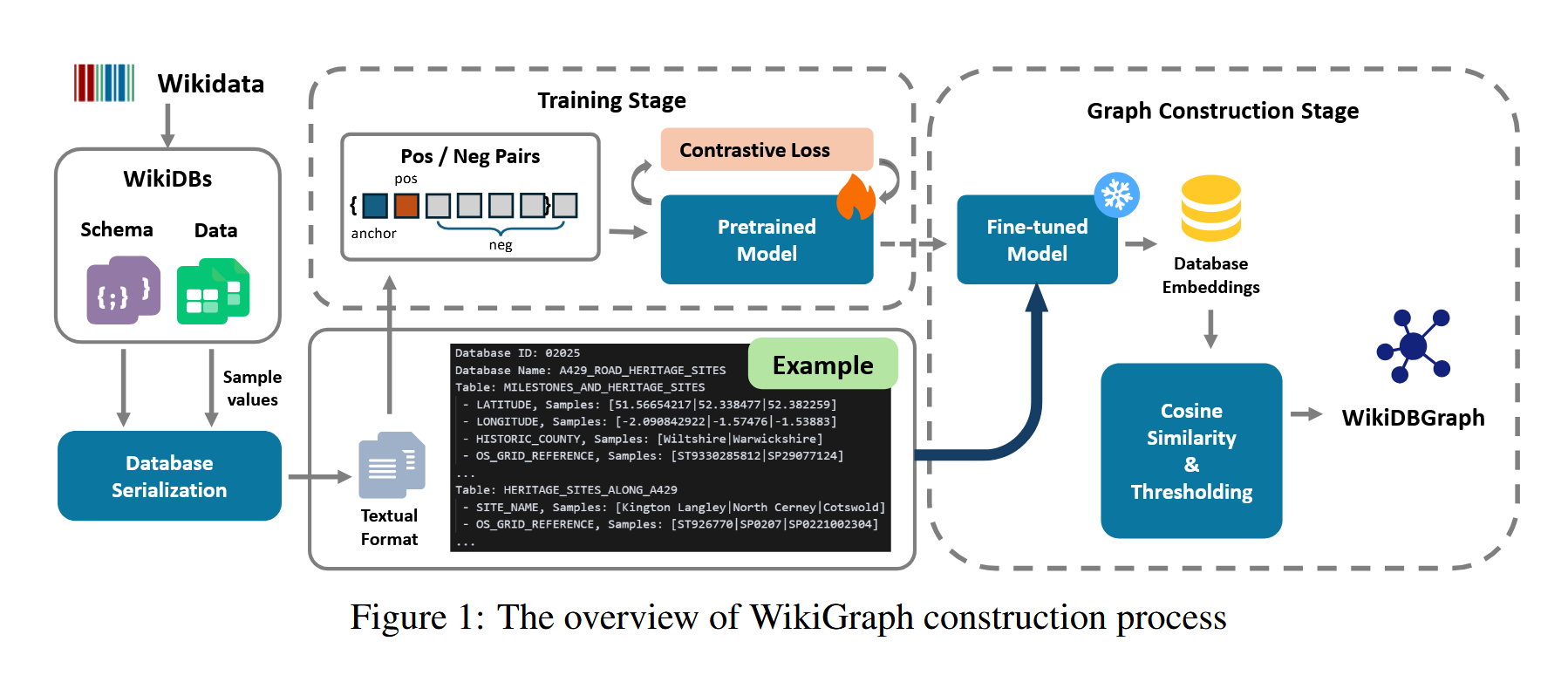
在目前深度學習領域中許多研究仍然侷限於單一表格或孤立的資料庫,使得模型的學習能力受到限制。目前的資料湖(Data Lake)與資料集(Dataset)雖然涵蓋大量資訊,但缺乏明確的跨資料庫關聯,導致協作學習的效果不如預期。
在【WikiDBGraph: Large-Scale Database Graph of Wikidata for Collaborative Learning】一文中,研究團隊推出了 WikiDBGraph,以 10 萬個維基數據表格資料庫組成的大規模圖結構。這個圖不僅連接了不同的資料庫,還透過 1700 萬條關聯建立數據間的關係,使得資料庫之間的互動更加緊密。
這項技術的核心特殊性在於它能夠識別資料庫間的關聯性,無論是實例重疊還是特徵重疊,都能透過 WikiDBGraph 進行分析與學習。這不僅提升了協作學習的效果,也為聯邦學習與遷移學習提供了新的可能性。更重要的是,這項技術為結構化基礎模型的訓練奠定了堅實的基礎,使得 AI 在處理表格數據時能夠更具智慧與適應性。
實驗結果顯示,透過 WikiDBGraph 進行協作學習,模型的效能得到了顯著提升。這項研究不僅為表格數據學習開闢了新方向,也為未來的人工智慧發展提供了更強大的工具。
完整原文:https://arxiv.org/pdf/2505.16635
#Wikidata #維基資料 #維基數據
#WikiDBGraph #資料庫 #Database #人工智慧 #協作學習 #AI