@grvsmth @TedUnderwood @dh curious how you see this playing out. Doing analytical things using natural language? Curious how you would flesh out LLMs for analytical purposes.
Andrew Piper
another #chatGPT phenomenon. It can't quite bring itself to speak 100% nonsense. I could get it to make up words, but it will always fall back on real connective words. Like it longs for grammar anchors.

#chatgpt question: I thought it was a stochastic parrot. I got the exact same response to the same prompt. How is that possible?
@TedUnderwood @sinykin @dbamman
also curious which would be more efficient for the full stack of info bookNLP gives you. i.e. having POS, deprel, ner, coref, etc all in one place. would this be easily replicable with GPT?
@TedUnderwood @sinykin @dbamman yeah we're building out some ground truth annotated data on the bookNLP "super-sense" tags. Then should be pretty straightforward to triangulate different approaches and relative accuracy.
@humanitiesData thanks for these suggestions!
So @dbamman do you think we are soon going to be post bookNLP? See attached. Experiment from this new paper: https://ceur-ws.org/Vol-3290/long_paper1576.pdf

Andrew Piper boosted:
As a reminder, attack on speech in higher Ed goes on. New bill will make it illegal to have a DEI office or even host an event about diversity, equity and inclusion in Texas universities
https://capitol.texas.gov/tlodocs/88R/billtext/pdf/HB01006I.pdf#navpanes=0
@mldh @alizhorvathaliz @quinnanya will have a new multilingual dataset from HathiTrust appearing next month to start facilitating research.
Andrew Piper boosted:
The establishing of a #MultilingualDH working group at #DARIAH is great news! Thanks to @alizhorvathaliz and Maroussia Bednarkiewicz, we will have the opportunity to strengthen the presence of #MultilingualDH in Europe and thus improve the awareness for issues with multilinguality and multiscriptuality in #DigitalHumanities. But this should be only a beginning, as @quinnanya sais: Next stop ADHO.
Andrew Piper boosted:
What will happen is that we will be increasingly focused on application and domain-specific resources and tools to evaluate, control, specialize, and manage these tools. The era of "general" tasks is probably over in #nlp. LREC-type stuff is where it's at (been that way for a long time, it just wasn't cool with a field that is IMO too rooted in computer science education) #emnlp2022
Andrew Piper boosted:
Opportunities in our "Gender & Tech" Group:
1️⃣ Research Fellow in #TechAbuse via #UKRIFLF
2️⃣ Research Fellow in #NLP via @VISION_UKPRP
3️⃣ PhD in a range of topics via CDT in #Cybersecurity
4️⃣ PhD on #IoT-Abuse via #QUB
👉Info: https://linkmix.co/13163250

Andrew Piper boosted:
#ChatGpt shows promise in distinguishing statements of #fact from statements of #speculation -- a key "skill" when trying to understand what lengthly #provenance texts and notes for #artworks are really saying.
#Question for #histodons and #NLP #Textanalysis #AI people : Who is working in the area of distinguishing "fact" from "speculation" by elements in the language?
What papers should I read?
Thank you!
Andrew Piper boosted:
Me and my team are hiring Research Scientist Interns to work with us at #MetaAI (FAIR), on compositional #generalization, long-form #reasoning, #interpretability in #NLP. Consider applying here: https://metacareers.com/jobs/687658102745368/ and DM me if interested! cc @Adinawilliams
Andrew Piper boosted:
Another new article in JCLS: "#Evaluation of Measures of Distinctiveness. #Classification of Literary Texts on the Basis of Distinctive Words" by @cnDuKeli, Julia Dudar and @christof #keyness #CLS https://doi.org/10.48694/jcls.102
Great thread on #AI and student assignments. https://twitter.com/Afinetheorem/status/1598081835736891393
Andrew Piper boosted:
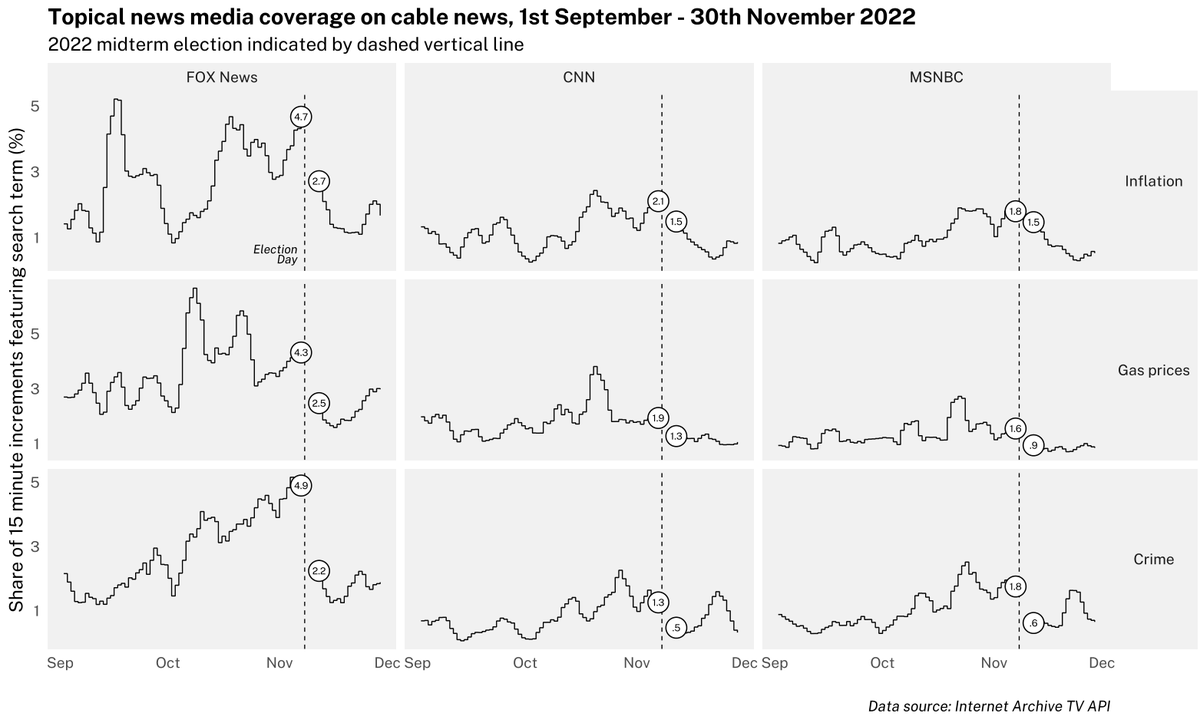
The real caravan was the crime and inflation we heard about along the way
RT @thomasjwood@twitter.com
Topical interest on cable news around the midterm election.
Data from @hrbrmstr@twitter.com's fantastic newsflash package.
🐦🔗: https://twitter.com/thomasjwood/status/1598325244875665408
Andrew Piper boosted:
New paper shows (as many papers before) that code that is shared will often not run. This is to be expected - few of us had training in this. But if you share code, go through checklists to prevent the most common mistakes. From the paper: https://www.nature.com/articles/s41597-022-01143-6 For some extra suggestions, see my textbook chapter on computational reproducibility: https://lakens.github.io/statistical_inferences/computationalreproducibility.html#some-points-for-improvement-in-computational-reproducibility

@NancyWilliamsPainter yes I think more work could go into these taxonomies (like all categories). This is what we have to work with for now. We tried to flesh out using the hypernym trees. Hoping folks innovate on that.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst