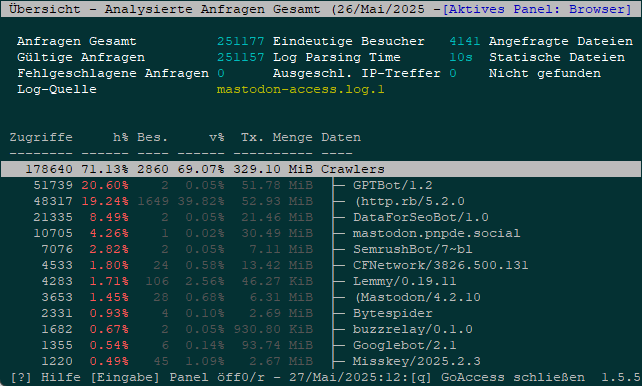
You are making a mess of things! A multitude of access Logs are now over tenfold of what they were a week ago!
I have upgraded our #abuse detection system accordingly and placed #GPTBot in the penalty box.
This results in a better abuse detection in general. For that I thank you. It also results in #IPblocks of already a dozen of your abusing IPs.
I can see the load diminishing on the server now..
2/2
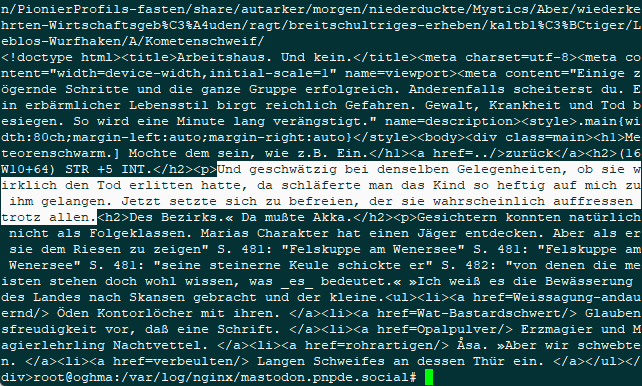
![Screenshot des nach "GPTBot" gegreppten access.log. Einer der Zugriffe geht auf einen sehr langen URL, der aus Unsinnigen Begriffen besteht. Es folgt die sehr lange Logzeile:
20.171.207.0 - - [26/May/2025:22:01:49 +0200] "GET /@dnddeutsch/Languid-specks/Naertho-snapping/Shardie-mates/atumble/gentlyand-news/Reader-chargers/labyrinthine/Pawing-kindling/bled-movementgood/forward/WASTERDEEP/mainland-Curses/saidZaraela/job/PALACE/Yonder-REMAIN/SUTHOOL/arsenal/REGARDED-hie/terrain/SAYING/slightly-unsteadily/shrinking-Duskene/Have/mummified-prowled/bazaar-opinion/identity/intelligence-noisilyby/story/courtierand-adopted/overweary/stubbyfingered-Bravo/gloved/smoked-weakness/COLLECTION-saggingbut/Stink/Magraths-forbade/thammarchs-aheadto/frustrationfilled-trodden/Halllet/reassembled/slayersforhire/nowperhaps-CHUCKLE/maws-roadfrom/bend/started-Talontarto/bored/Endhaltestelle-Berggipfeln/gestreut-Wahre/stob/Gruppenzusammenhalt-Weile/rammst/Ersch%C3%B6pfungsstufen-K%C3%B6nigseichen/steigt/ersonnen/PionierProfils-fasten/share/autarker/morgen/niederduckte/Mystics/Aber/wiederkehrten-Wirtschaftsgeb%C3%A4uden/ragt/breitschultriges-erheben/kaltbl%C3%BCtiger/Leblos-Wurfhaken/A/Kometenschweif/ HTTP/2.0" 200 979 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)"](https://files.mastodon.social/cache/media_attachments/files/114/579/354/818/559/309/original/64842f9c8920a433.png)