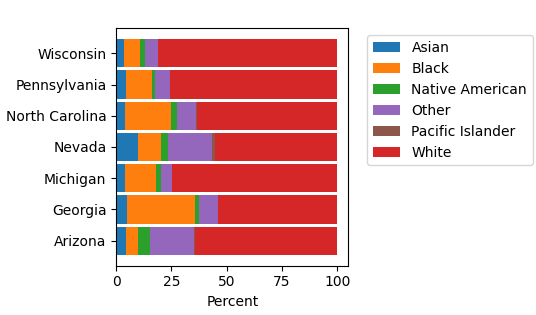
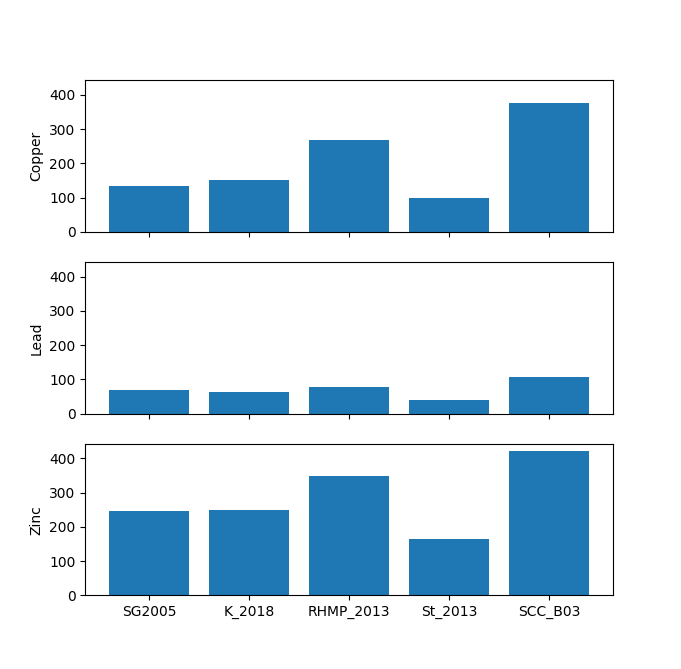
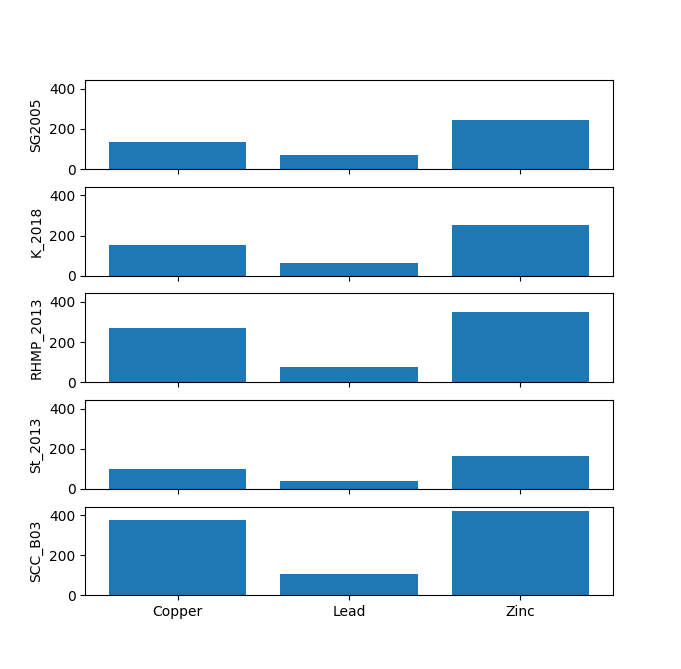
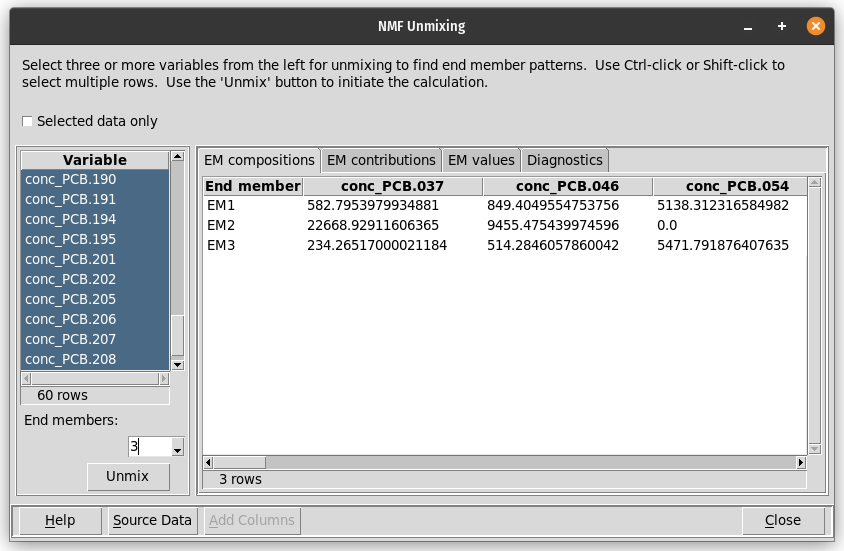
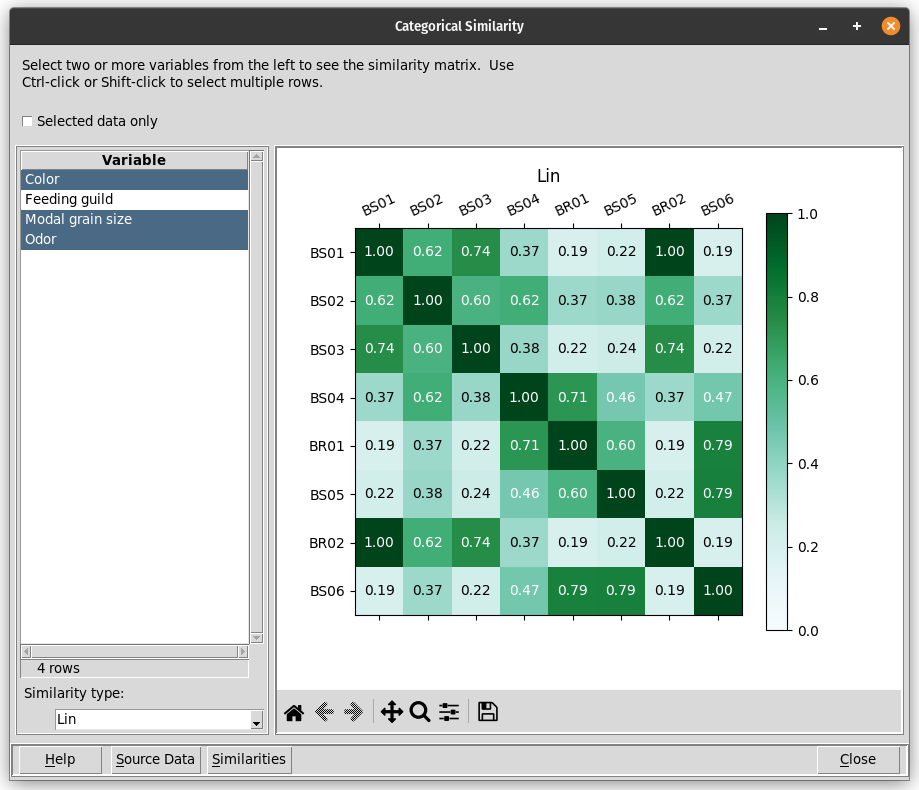
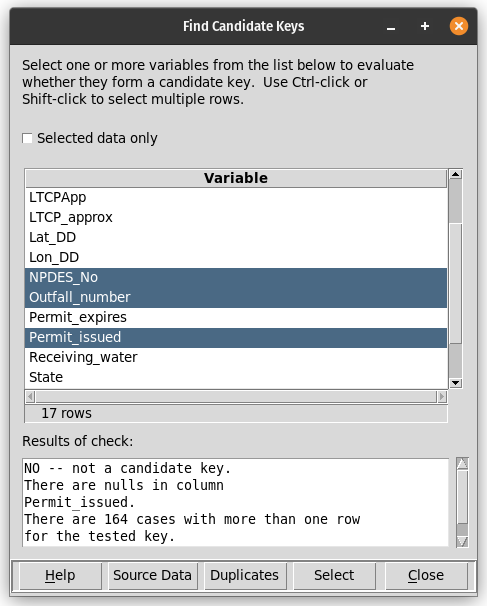
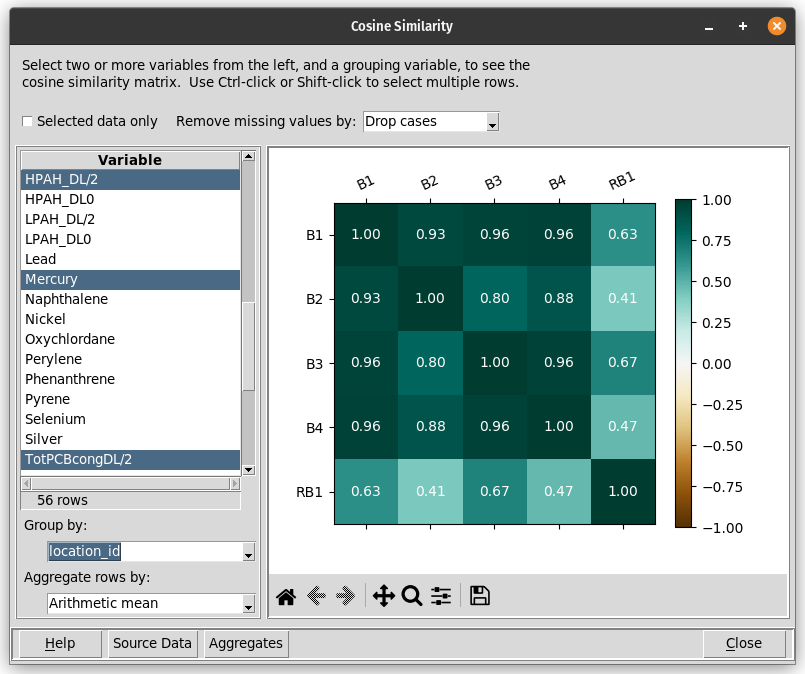
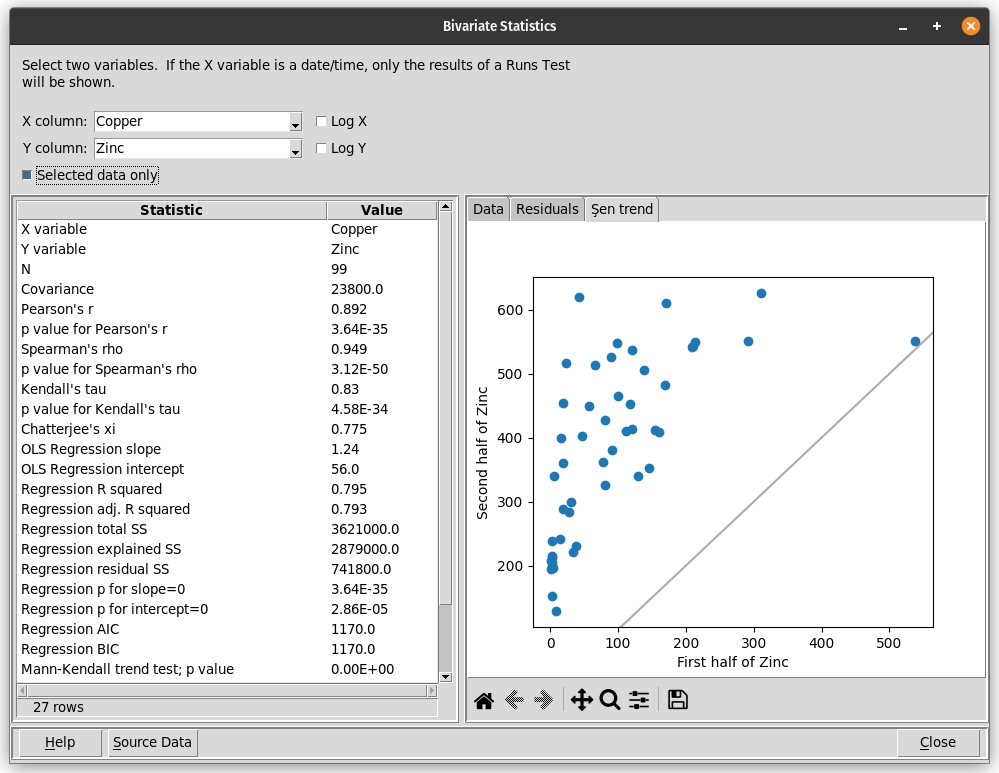
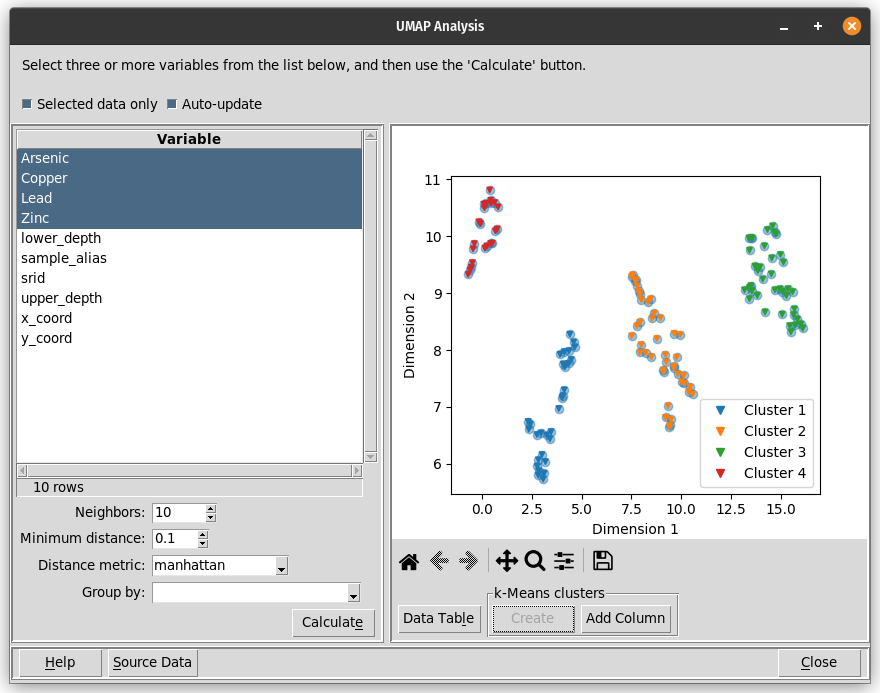
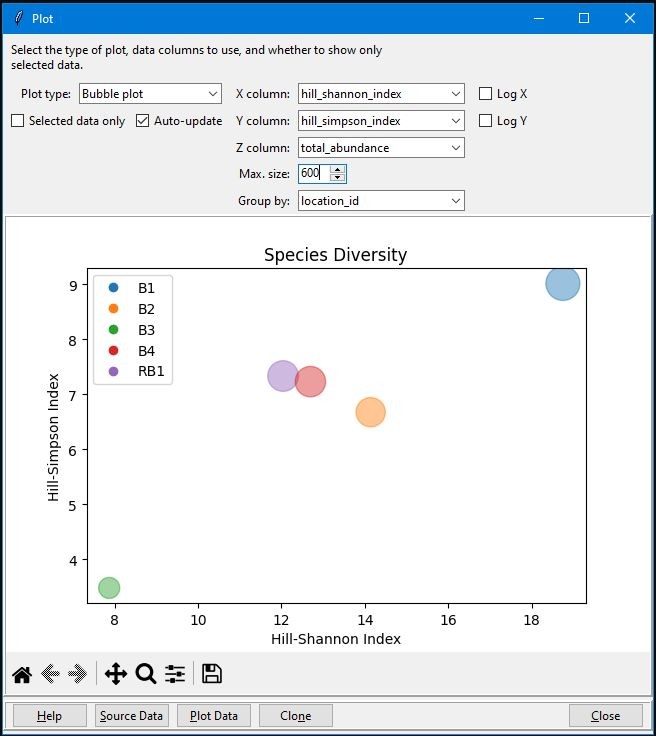
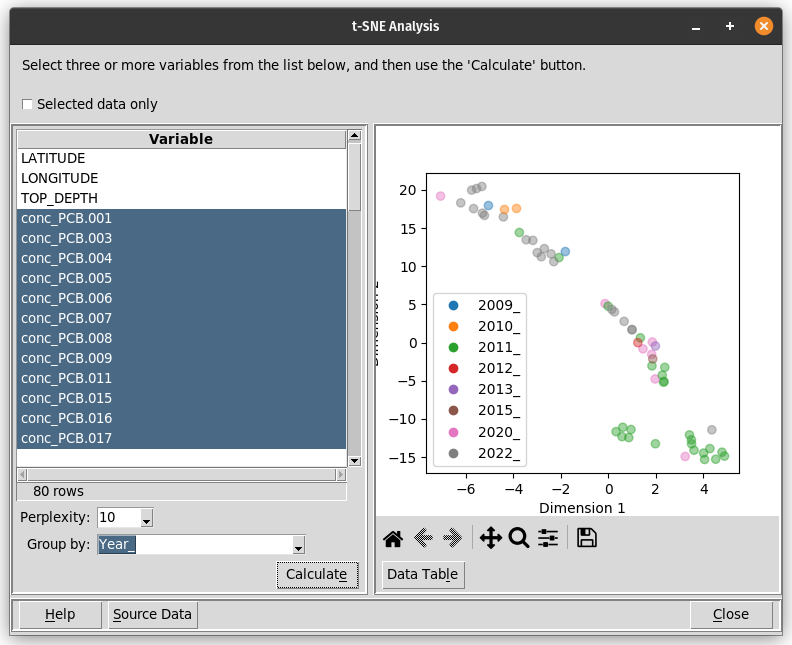
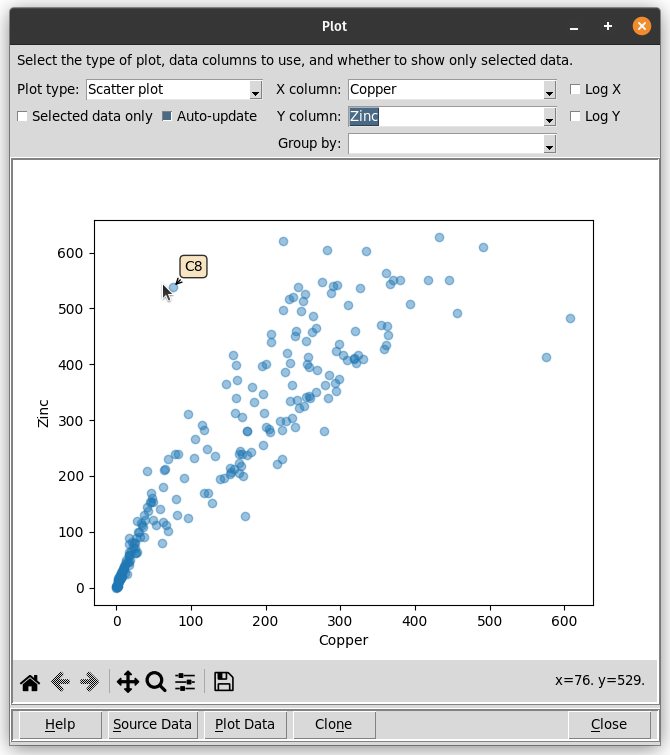
The data explorer mapdata.py (https://pypi.org/project/mapdata/) has a new plotting tool that displays percentages for a set of numerical variables and a single categorical variable. Percentages can be calculated either by variable or by category. Data can be aggregated by min, max, mean, median, sum, or count prior to calculation of percentages.
#MapData #DataExploration #DataAnalysis #DataViz #DataVisualization #Plotting #Python #FOSS #FLOSS