Efficient E-Matching for Super Optimizers
https://blog.vortan.dev/ematching/
#HackerNews #Efficient #E-Matching #Super #Optimizers #E-Matching #Technology #Optimization
Efficient E-Matching for Super Optimizers
https://blog.vortan.dev/ematching/
#HackerNews #Efficient #E-Matching #Super #Optimizers #E-Matching #Technology #Optimization
The Optimizer Advantage?
This is not how I’d expect an optimizer system to work, at least based on how it’s advertised.
This MicroAdam paper from #NeurIPS2024 is nicely written! The algorithm is walked through in plain language first, and all the equations and proofs placed in the appendix. Super understandable, kudos to the authors.
https://arxiv.org/abs/2405.15593
#AI #MachineLearning #LLMs #optimizers
'PROMISE: Preconditioned Stochastic Optimization Methods by Incorporating Scalable Curvature Estimates', by Zachary Frangella, Pratik Rathore, Shipu Zhao, Madeleine Udell.
http://jmlr.org/papers/v25/23-1187.html
#optimizers #optimization #preconditioned
'PyPop7: A Pure-Python Library for Population-Based Black-Box Optimization', by Qiqi Duan et al.
http://jmlr.org/papers/v25/23-0386.html
#optimizers #optimization #pypop7
'Multi-Objective Neural Architecture Search by Learning Search Space Partitions', by Yiyang Zhao, Linnan Wang, Tian Guo.
http://jmlr.org/papers/v25/23-1013.html
#optimizers #optimizer #optimizations

'Robust Black-Box Optimization for Stochastic Search and Episodic Reinforcement Learning', by Maximilian Hüttenrauch, Gerhard Neumann.
http://jmlr.org/papers/v25/22-0564.html
#reinforcement #optimizers #optimizes
'Neural Feature Learning in Function Space', by Xiangxiang Xu, Lizhong Zheng.
http://jmlr.org/papers/v25/23-1202.html
#features #feature #optimizers
'Win: Weight-Decay-Integrated Nesterov Acceleration for Faster Network Training', by Pan Zhou, Xingyu Xie, Zhouchen Lin, Kim-Chuan Toh, Shuicheng Yan.
http://jmlr.org/papers/v25/23-1073.html
#accelerated #optimizers #adaptive

'Scaling the Convex Barrier with Sparse Dual Algorithms', by Alessandro De Palma, Harkirat Singh Behl, Rudy Bunel, Philip H.S. Torr, M. Pawan Kumar.
http://jmlr.org/papers/v25/21-0076.html
#optimizers #sparse #dual
'Polygonal Unadjusted Langevin Algorithms: Creating stable and efficient adaptive algorithms for neural networks', by Dong-Young Lim, Sotirios Sabanis.
http://jmlr.org/papers/v25/22-0796.html
#langevin #adaptive #optimizers

'Improving physics-informed neural networks with meta-learned optimization', by Alex Bihlo.
http://jmlr.org/papers/v25/23-0356.html
#optimizers #learnable #learned

A DNN Optimizer that Improves over AdaBelief by Suppression of the Adaptive Stepsize Range
Guoqiang Zhang, Kenta Niwa, W. Bastiaan Kleijn
Action editor: Rémi Flamary.
Auto-configuring Exploration-Exploitation Tradeoff in Population-Based Optimization: A Deep Reinforcement Learning Approach
Learning to Optimize Quasi-Newton Methods
The Slingshot Effect: A Late-Stage Optimization Anomaly in Adaptive Gradient Methods
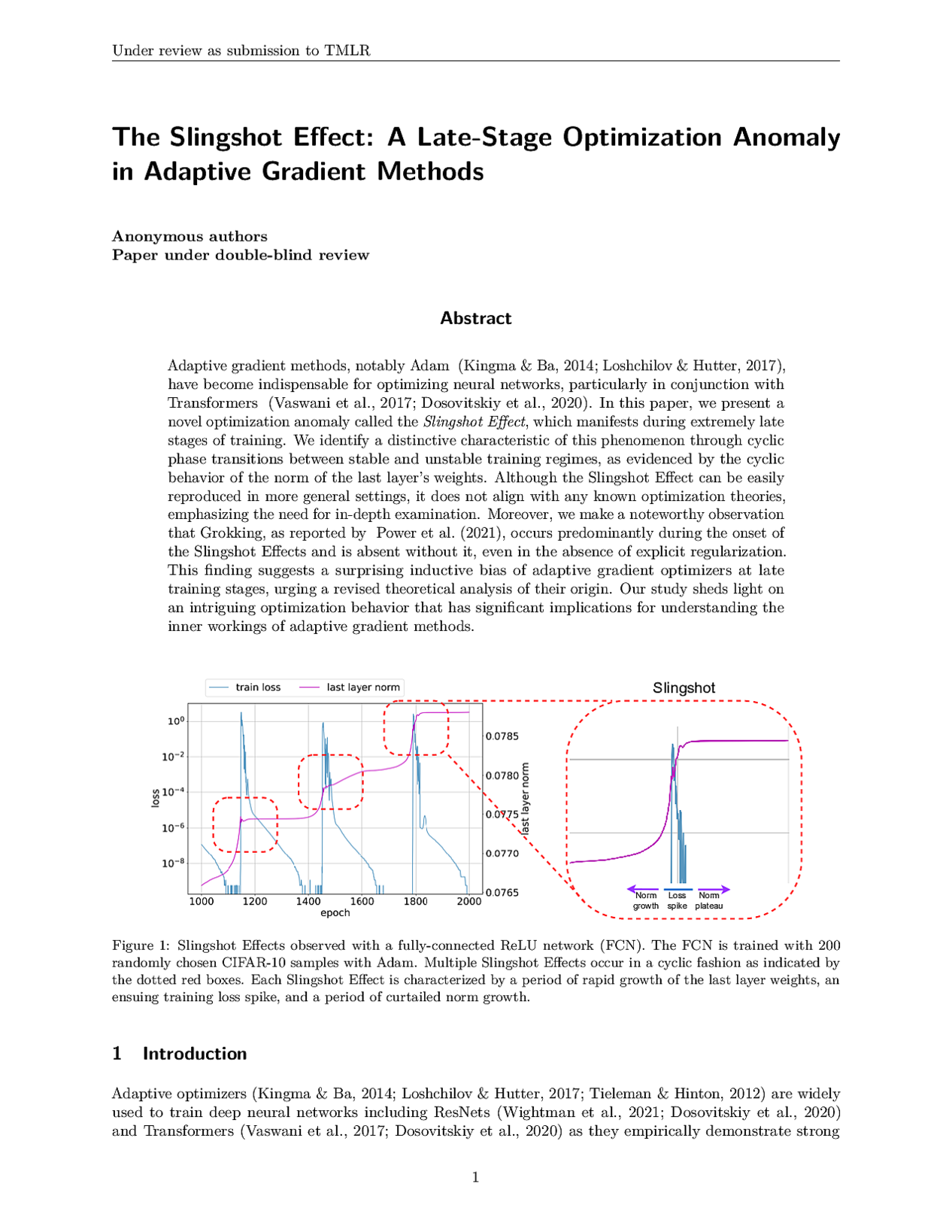
Personalized Federated Learning: A Unified Framework and Universal Optimization Techniques
Filip Hanzely, Boxin Zhao, mladen kolar
Action editor: Naman Agarwal.
A DNN Optimizer that Improves over AdaBelief by Suppression of the Adaptive Stepsize Range
Constrained Parameter Inference as a Principle for Learning
Nasir Ahmad, Ellen Schrader, Marcel van Gerven
Algorithms utilizing more than 4-qbits in #quantumcomputing ...here is a timely and informative manuscript on #benchmarking results #algorithm #optimizers #computing #data #MachineLeaning #QuantumML
https://arxiv.org/abs/2211.15631