I needed an excuse to make a word cloud shaped like a brain and I finally found one. Who said dreams don’t come true?
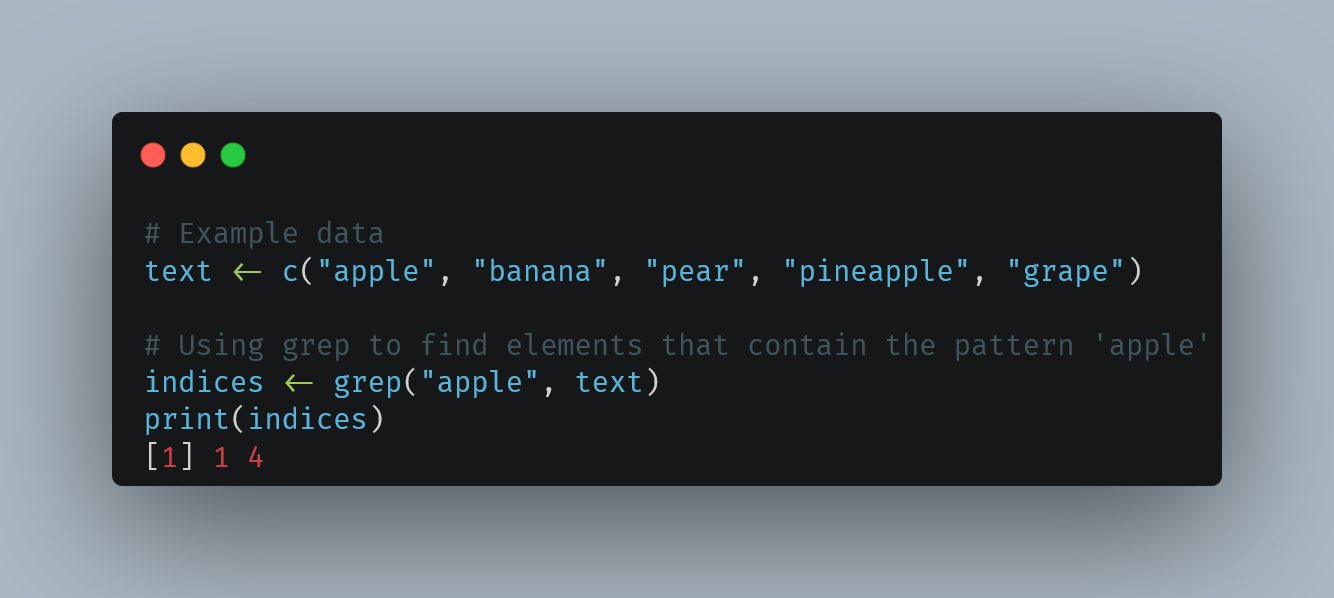
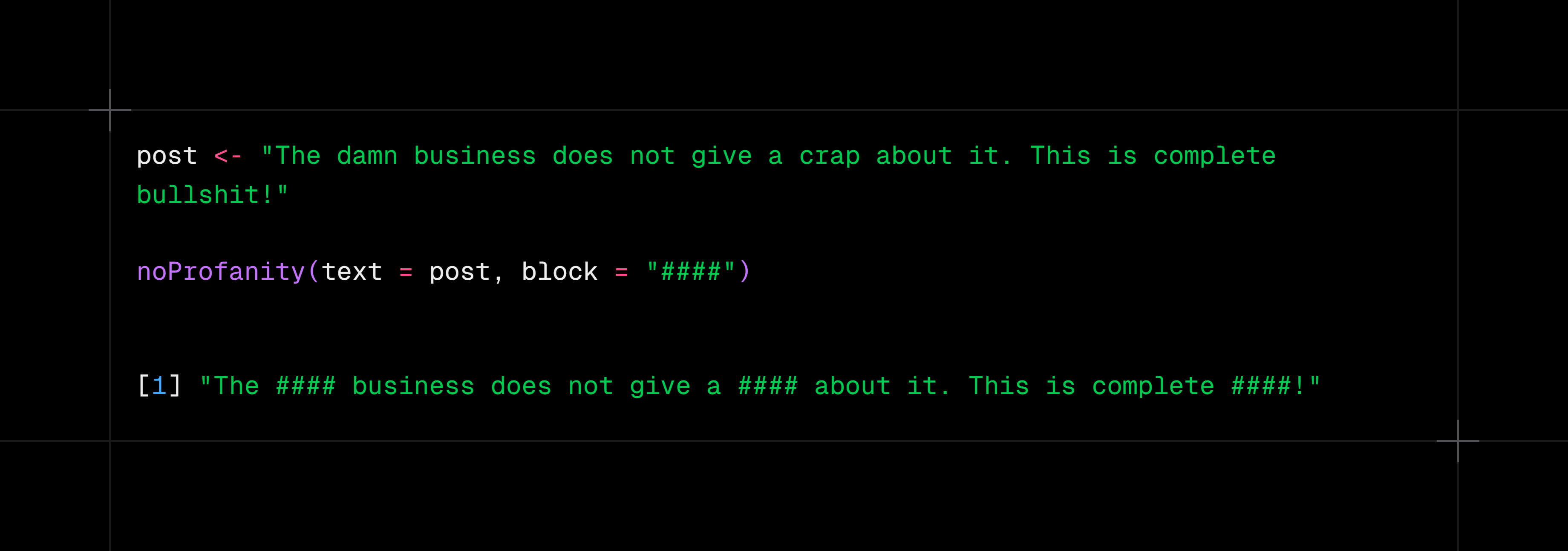
But in all seriousness, I learned a couple of things about how to work with text data, especially short text across multiple languages and I’ve shared that here:
https://neurofrontiers.blog/how-people-find-us/
#WordCloud #TextData #DataAnalysis #DataIsBeautiful #multilingual
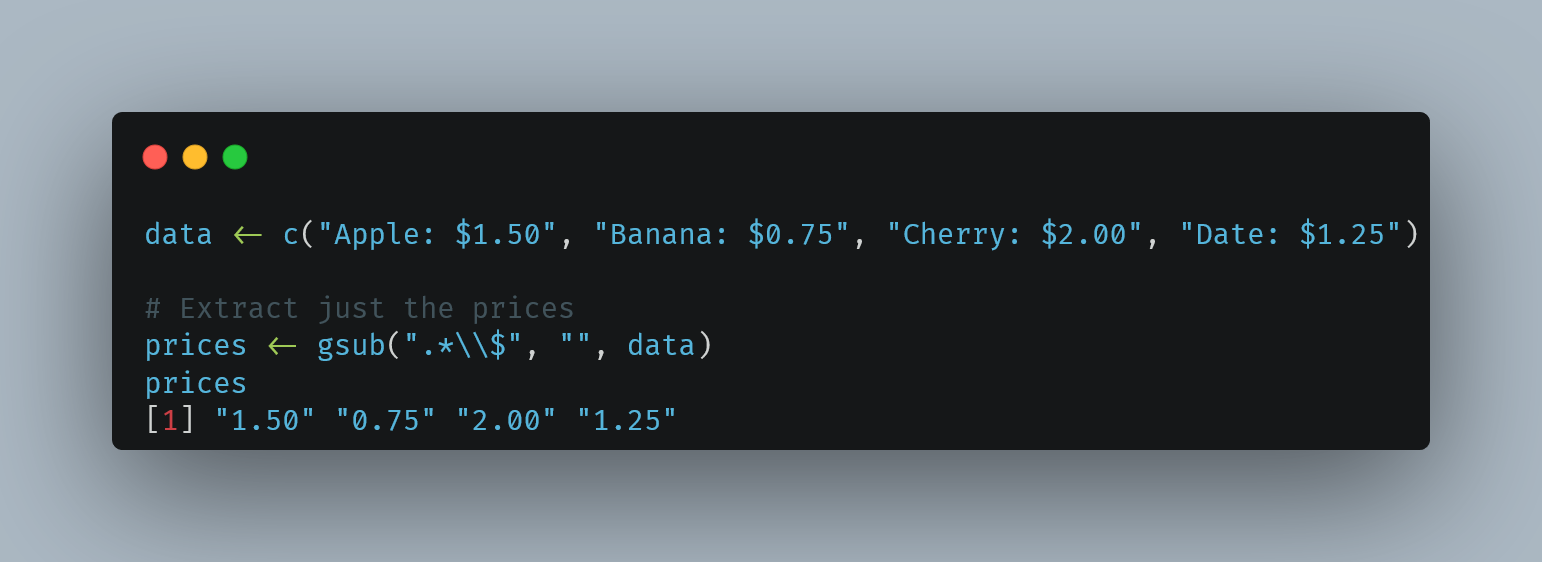
![wdir <- "W:/path/to/files"
fl <- list.files(wdir, pattern = "\\.txt$", full.names = TRUE)
fl <- purrr::discard(fl, stringr::str_detect(fl, "updated"))
fl <- fl[!fl %in% c("W:path/to/files/bad_file.txt")]
fl <- setNames(fl, basename(fl))
txt_to_df <- function(txt_file) {
txt_lines <- readLines(txt_file)
x <- data.frame(txt_lines)
writeLines(txt_lines, "test.csv")
data <- read.csv("test.csv", header = TRUE, sep = "|")
data <- dplyr::as_tibble(data) |>
dplyr::mutate(dplyr::across(.cols = dplyr::everything(), .fns = as.character))
return(data)
}
add_missing_cols <- function(df) {
if (ncol(df) != 102) {
missing_cols <- c("MissingColumns1","MissingColumn2","MissingColumn3")
df[missing_cols] <- NA
}
return(df)
}
ret <- purrr::map(fl, txt_to_df)
ret <- purrr::map(ret, add_missing_cols)
ret <- purrr::map(ret, janitor::clean_names)
bad_cols_txt <- purrr::keep(ret, \(x) ncol(x) != 102)
good_files_txt <- purrr::keep(ret, \(x) ncol(x) == 102)
good_files_tbl <- good_files_txt |>
purrr::map(\(x) x |>
dplyr::mutate(dplyr::across(.cols = dplyr::everything(), .fns = as.character))) |>
purrr::list_rbind(names_to = "id")
if (length(bad_cols_txt) > 0) {
bad_files_tbl <- bad_cols_txt |>
purrr::map(\(x) x |>
dplyr::mutate(dplyr::across(.cols = dplyr::everything(), .fns = as.character))) |>
purrr::list_rbind(names_to = "id")
}](https://files.mastodon.social/cache/media_attachments/files/113/164/654/504/360/522/original/d17213bd34489b8e.png)
![wdir <- "W:/path/to/files"
fl <- list.files(wdir, pattern = "\\.txt$", full.names = TRUE)
fl <- purrr::discard(fl, stringr::str_detect(fl, "updated"))
fl <- fl[!fl %in% c("W:path/to/files/bad_file.txt")]
fl <- setNames(fl, basename(fl))
txt_to_df <- function(txt_file) {
txt_lines <- readLines(txt_file)
x <- data.frame(txt_lines)
writeLines(txt_lines, "test.csv")
data <- read.csv("test.csv", header = TRUE, sep = "|")
data <- dplyr::as_tibble(data) |>
dplyr::mutate(dplyr::across(.cols = dplyr::everything(), .fns = as.character))
return(data)
}
add_missing_cols <- function(df) {
if (ncol(df) != 102) {
missing_cols <- c("MissingColumns1","MissingColumn2","MissingColumn3")
df[missing_cols] <- NA
}
return(df)
}
ret <- purrr::map(fl, txt_to_df)
ret <- purrr::map(ret, add_missing_cols)
ret <- purrr::map(ret, janitor::clean_names)
bad_cols_txt <- purrr::keep(ret, \(x) ncol(x) != 102)
good_files_txt <- purrr::keep(ret, \(x) ncol(x) == 102)
good_files_tbl <- good_files_txt |>
purrr::map(\(x) x |>
dplyr::mutate(dplyr::across(.cols = dplyr::everything(), .fns = as.character))) |>
purrr::list_rbind(names_to = "id")
if (length(bad_cols_txt) > 0) {
bad_files_tbl <- bad_cols_txt |>
purrr::map(\(x) x |>
dplyr::mutate(dplyr::across(.cols = dplyr::everything(), .fns = as.character))) |>
purrr::list_rbind(names_to = "id")
}](https://files.mastodon.social/cache/media_attachments/files/113/164/653/837/908/849/original/32328265a7137084.png)