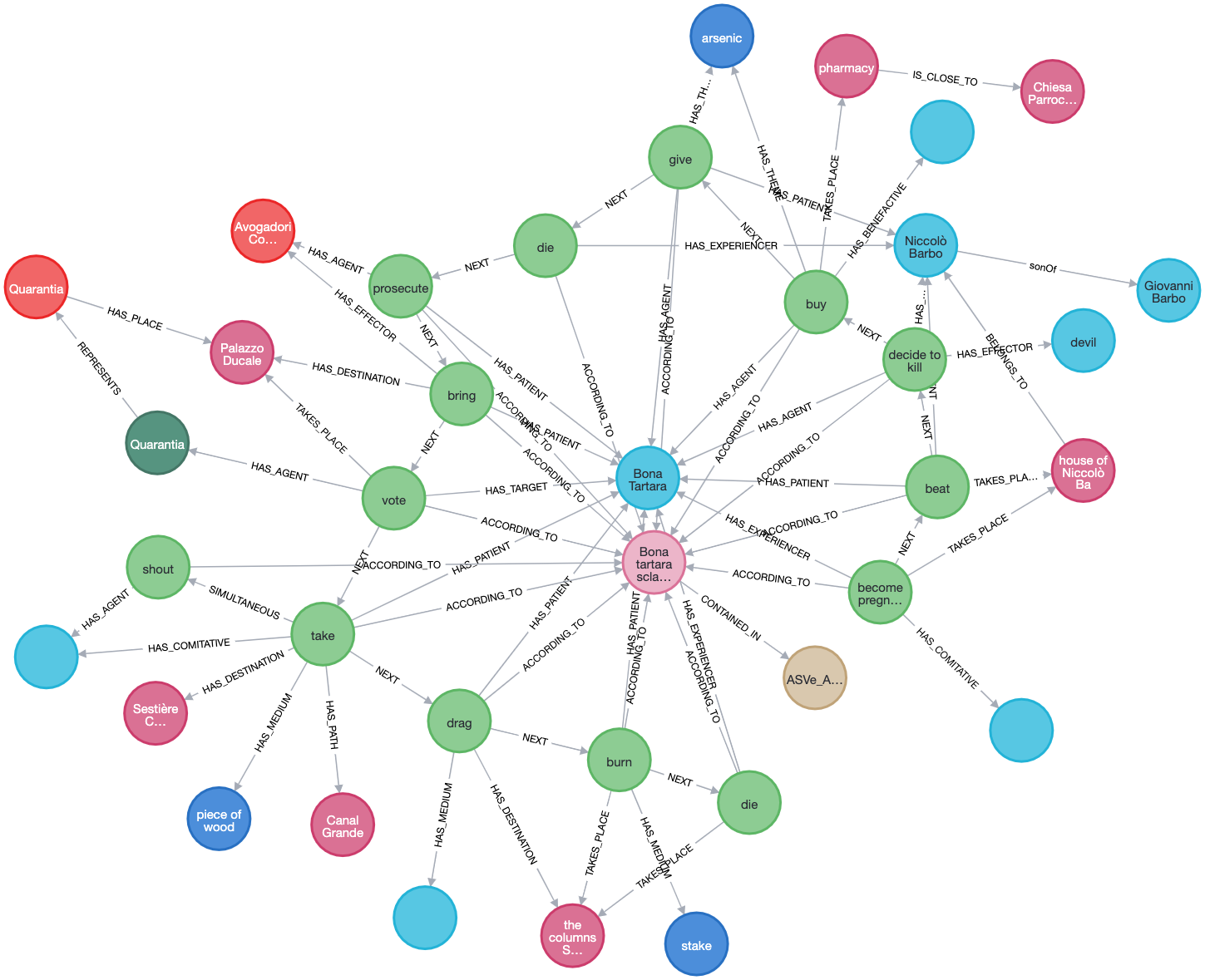
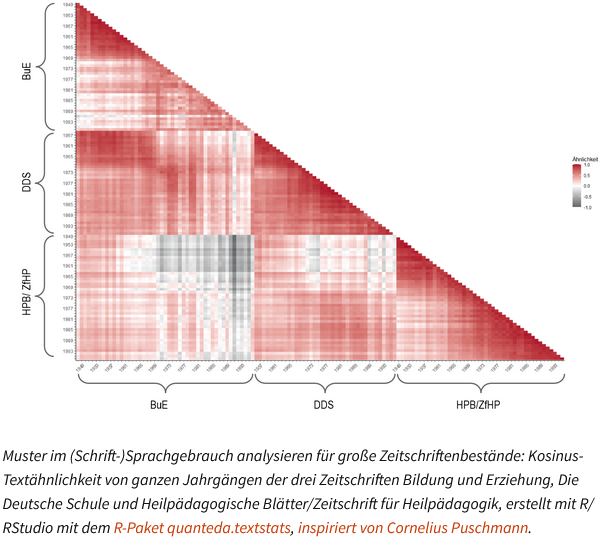
#Hinweis auf #Nutzbarkeit von #Data #Analytics / #Data #Science #Methoden #Scraping, #Pattern #Recognition, #Machine #Learning oder #Text #Mining für #soziologische #Forschung.
#Sutter / #Maasen - #Neuerfindung #Soziologie S.76 f. 2020 DOI: 10.5771/9783845295008-73
#MachineLearning #ML #TextMining #Soziologie #BigData #Methodologie #Methodik #Sozialforschung #Sozialwissenschaft