
I have almost fully puppetized #ceph in $dayjob. Sadly cannot open source it, but after seeing the sad state of the open source status of somewhat-working 2 ceph puppet modules, I might reserve some time later.
#Ceph

New blog post: https://blog.mei-home.net/posts/ceph-rgw-s3-metrics/
I describe how I set up Prometheus metrics gathering for Ceph's S3 RadosGW.
And I finally realise that "chart" is the right for a...well...chart.



Need some #Ceph advisory for my private cluster on #proxmox:
3 nodes with 2x 18 TB HDD each.
According to some docs I found, WAL/DB size should be 1-4% of the disk size, so a SSD should be between 180 to 720 GB for each disk or 360 to 1.44 TB for the two disks in each node.
Is this still be true or is it nowadays more relaxed and - let's say - 200 GB for each HDD will be sufficient?
Man sieht an den Latenzen uebrigens schon sehr schoen, welche OSDs ich schon von WAL/DB auf SSD umgestellt habe auch interne WAL/DB...

So langsam kommt der #Ceph Cluster nach dem Aussetzer dieser Tage ja wieder zur Ruhe... bzw. hat das Backfilling abgeschlossen.
Backfilling, weil ich 2 OSDs von ihrem WAL/DB auf SSD befreit habe, nachdem das immer langsamer geworden war.
Nun ist das Mail-Storage wieder schnell, obwohl es ja ohne SSD eigentlich langsamer sein sollte.
Wenn das Backfilling beendet ist, kommen die naechsten OSDs dran.
Und wenn alle durch sind, ueberlege, ob ich z.B. 3x Micro 5400 Max mit 480 GB fuer den Zweck kaufen soll? Die haben immerhin ein DWPD von >1. Bei den WD Red SA500 habe ich so eine Angabe nicht finden koennen und nach ca. 2-3 Jahren kann ich nicht behaupten, dass ich die fuer so einen Zweck nochmal kaufen wuerde...
Main project for the long weekend: Finally gathering some metrics on the S3 buckets in my Ceph cluster. Up to now, I've only got the total size of the pool holding all of the buckets, but no metrics on how big the individual buckets are.
I will try to use this Prometheus data exporter: https://github.com/blemmenes/radosgw_usage_exporter

I have a #ceph induced headache.

Today I had a really pleasant experience of upgrading #Ceph clustered storage from version reef to squid on our 3-node Proxmox Cluster.
At this point I almost dare to say it's basically zfs for networked, but I haven't configured it by hand from scratch yet.
New blog post: https://blog.mei-home.net/posts/broken-hdd/
This time I'm talking about how I replaced a broken HDD in my Ceph cluster.

Also #ceph ist ja schon spannend...
ich versuche einen Container zu starten.
Fehler: libceph kann monmap nicht lesen
Hinweis: 'ceph min dump' sagt das ein mon nur eine IP hat.
Lösung: den betreffenden mon töten und neu erstellen...
Auf einem ganz anderen node...
Gemacht, getan, geht...

This feature landed in the #Ceph Pacific release, more than 5 years ago.
I wonder how common it is to use this in production.
https://docs.ceph.com/en/squid/rados/operations/stretch-mode/#stretch-mode1
Short thread:
Can a #Postgres person please explain something to me?
CloudNativePG seems to assert that if a Kubernetes cluster uses #Ceph or Longhorn for persistent storage, replication in the underlying storage layer is superfluous.
https://cloudnative-pg.io/documentation/current/storage/#block-storage-considerations-cephlonghorn
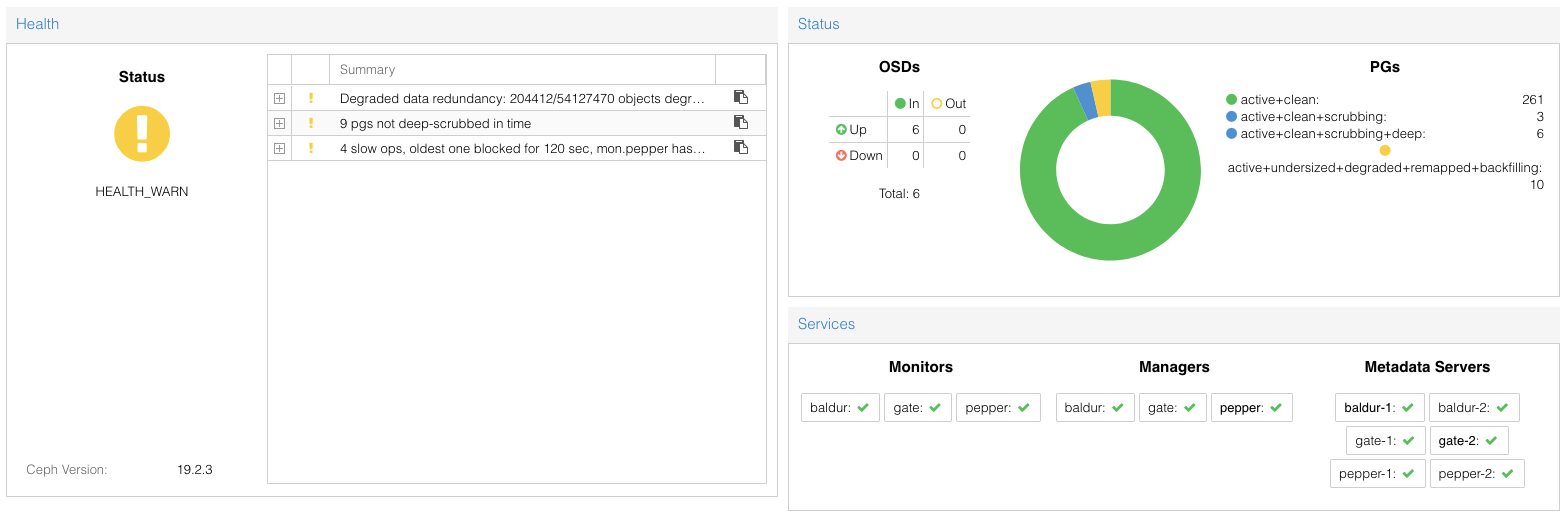
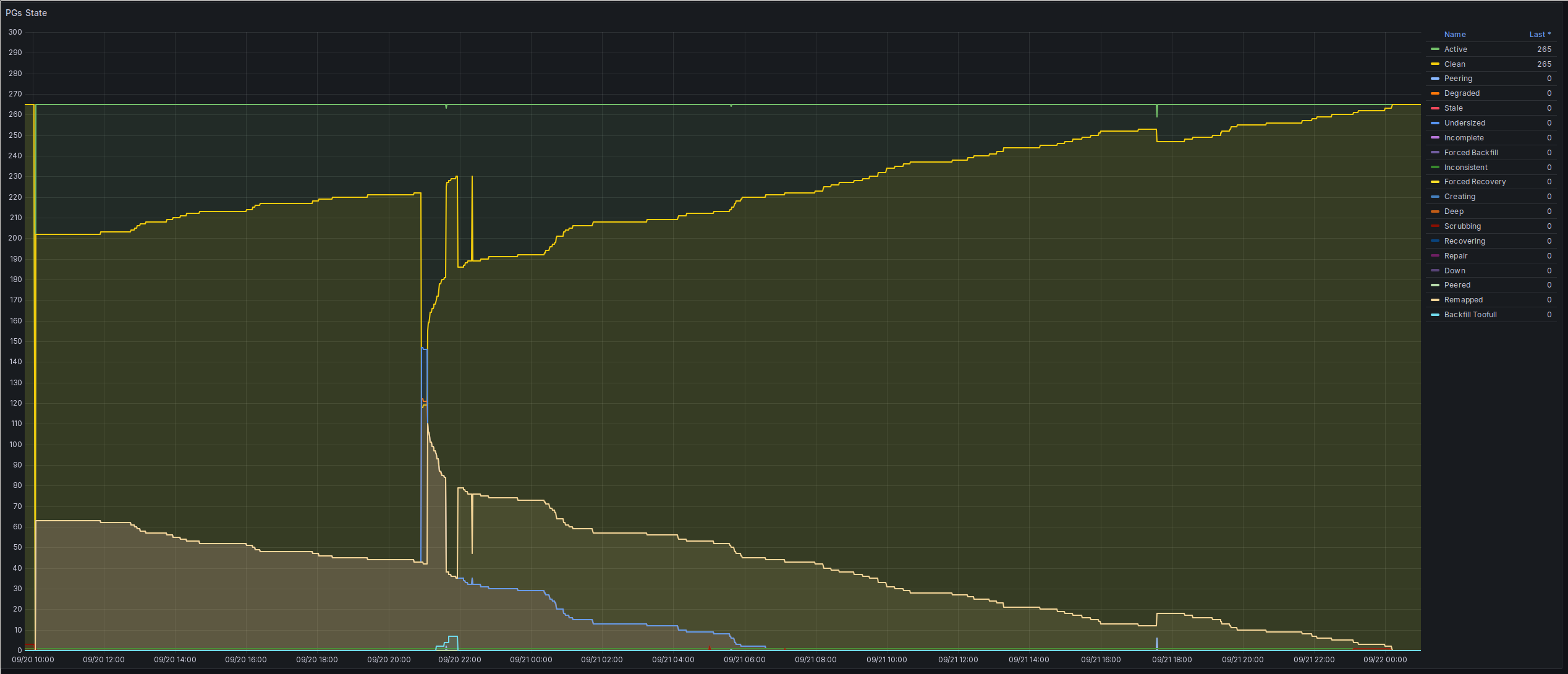
Short recap of the weekend: Since this morning around 00:15, my cluster is back in a healthy state. The dangertime with reduced redundancy lasted from Saturday 21:00, when I took out the old HDD until Sunday morning around 07:00, when the last undersized PG was remapped.
With the switch from a 4TB to an 8TB HDD, I gained about 1.33TB usable space in the cluster.
The new HDD does feel a bit louder when being accessed.
Blog post to come.


"Cephalopod ID Guide for the Mediterranean Sea", C. Drerup and G. Cooke, 2019
The Ceph cluster backfill onto the new HDD is still ongoing, but I was already out of the woods this morning around 07:00 , when the last degraded+undersized PGs got backfilled. Since then, the cluster has merely been filling up the new HDD, and now it seems to have decided to move a few additional PGs around to the new disk.
The peak around 21:00 was when I temporarily shut down one of the Ceph hosts to replace the HDD after realising I didn't have enough space left.
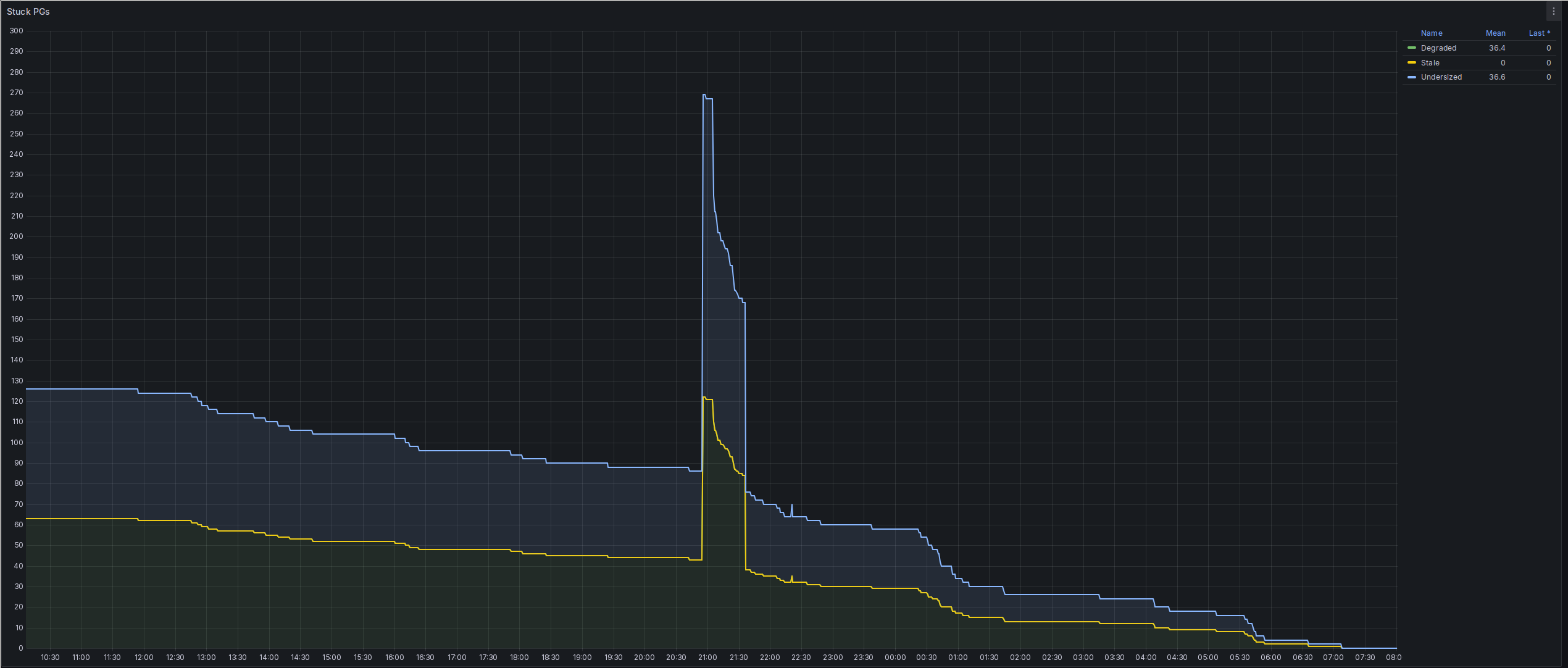

Dang, I might have miscalculated. I've still got 16% of PGs to remap, and one of my disks is already almost full. Seems I don't actually have enough storage to survive with an entire disk gone.
Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst