In case you missed the Renku 2.0 Launch Webinar, here is the recording: https://youtu.be/xYFzysHInVc
#OpenResearchData
Renku 2.0 has launched! The new release was rolled out this week and replaced the "legacy" platform. This is a major milestone and represents ~18 months of work - a huge effort by the whole team! We're excited to see how our users leverage this new modular design - check it out at https://renkulab.io! Join us tomorrow for the launch webinar to learn more.
Release blog post: https://blog.renkulab.io/launch-renku-2/
Webinar: https://blog.renkulab.io/renku-2-launch/
The day is almost here! We'll be launching our rebuilt, reimagined and reinterpreted collaborative data science platform Renku 2.0 in less than two weeks! Join the webinar to learn more: https://blog.renkulab.io/renku-2-launch/
Data Steward / Data Manager (m/f/d), 80–100 %, befristet für 1 Jahr mit Verlängerungsoption | https://www.lib4ri.ch/hiring-data-stewarddata-manager-80-100 | https://bibliojobs.eu/stellenangebote/113623/
#bibliojobs
#datastewardship #FAIRData #Forschungsdatenmanagement #IT #OpenResearchData #wissenschaftlicheBibliothek
Renku 2.0 is quickly taking shape - we are just one build cycle away from full public release! You can use it already in "early access" mode - check out our blog-post for details: https://blog.renkulab.io/early-access/
#openscience #opendata #openresearchdata #openinfrastructure #datascience #renkuplatform
Open Research Data in Spanish University Repositories
https://microblogging.infodocs.eu/2024/11/19/open-research-data-in-spanish-university-repositories/
#InstitutionalRepositories #JuanJosePrietoGutirrez #OpenRepositories #OpenResearchData #PabloMonteagudoHaro #Spain
(Not yet a Dr.) Florin Hasler of @OpendataCH introduces the economic and social value of #OpenData with a glib "here's your way out if you are bored here" 🚂🆘
At the start of the #OpenResearchData Hackathon with #SDSC #EPFL #Lausanne

Swiss ORD Strategy Council - herding cats, or leading a transformational movement in science? We will see: I think their strategy sounds robust, and their use cases well chosen #OpenResearchData
https://openresearchdata.swiss/the-strategy-council/

"Spaces for people to come together and share collective practices" #teamscience #OpenScience #openresearchdata #EPFL
https://www.epfl.ch/research/open-science/

Economic valuation of open research data: A conceptual framework and methodological approach
#Innovation #JiashuShen #OpenResearchData #OpenScience #ResearchImpact #ZhifangTu
After more general inquiries into the topic of #metadata, this week on ShareTIGR (https://sharetigr.usi.ch/en/news/feeds/38844) we more concretely comment on the in-built metadata scheme of the Language repository of Switzerland LaRS @ SWISSUbase, where we intend to deposit the #TIGRcorpus. LaRS provides fields to describe data at study, dataset and file level. We found many useful categories, struggled to classify transcripts as either 'Texts' or 'Annotations' and observed the lack of categories concerning individual study participants and de-identification measures.
#openscience #openresearchdata
@corpuslinguistics
@linguistics
@dh

This week on the ShareTIGR lab blog (https://sharetigr.usi.ch/en/news/feeds/38589): Why #metadata is important for FAIR data sharing and reuse? Metadata is an important topic in data management. In this post, Nina Profazi reflects on the relevance of descriptive, technical and administrative metadata for interactional linguistics. Later, we will discuss the specific choices to be made at this regard for our conversational data on the LaRS repository. #openscience #openresearchdata #opendata #spokenlanguage #corpuslinguistics #interactionallinguistics
@dh @linguistics @corpuslinguistics
Dame Janet Thornton, former Director of European Bioinformatics Institute | EMBL-EBI, talked about SIB’s impact during her interview after her keynote speech at #SIBdays24, the Swiss bioinformatics summit.
Read the full interview 👉 https://www.sib.swiss/news/you-cant-understand-life-without-understanding-the-chemistry-of-it
#Bioinformatics #DataScience #OpenScience #OpenResearchData

In less than a week, we will have our 2024 Renku users meeting in Bern - we'll talk all things collaborative data science, explain the new direction the #renkuplatform is taking and hear from a few users that leverage Renku for their work. There will also be time to discuss issues around collaborative open research with other like-minded folks. More info here: https://blog.renkulab.io/users-meeting-2024
#datascience #researchcollaboration #openscience #openresearchdata #ord
In this week's ShareTIGR 📰 post and the associated silent 🎬video (https://sharetigr.usi.ch/en/news/feeds/37889), we present our first🐍Python script ever, which we wrote to process transcripts exported from the multimedia annotator ELAN. Its task is to "filter" timecode stamps to reduce their number. This is one of several steps to produce .txt transcripts that contain a maximum of information while still being readable to the human eye. #openresearchdata #openscience #EMCA #interactionallinguistics @dh @corpuslinguistics @linguistics
In this week's ShareTIGR 📰 post (https://sharetigr.usi.ch/en/news/feeds/38066) and in the associated 🎬video (https://www.youtube.com/watch?v=Ileqblg23_o) we talk about ⌚timecode in ELAN and ask ❓what to do with it when exporting a transcript as simple text.
#openresearchdata #FAIRdata #transcription #spokenlanguage #italianoparlato #emca
@dh @linguistics @corpuslinguistics
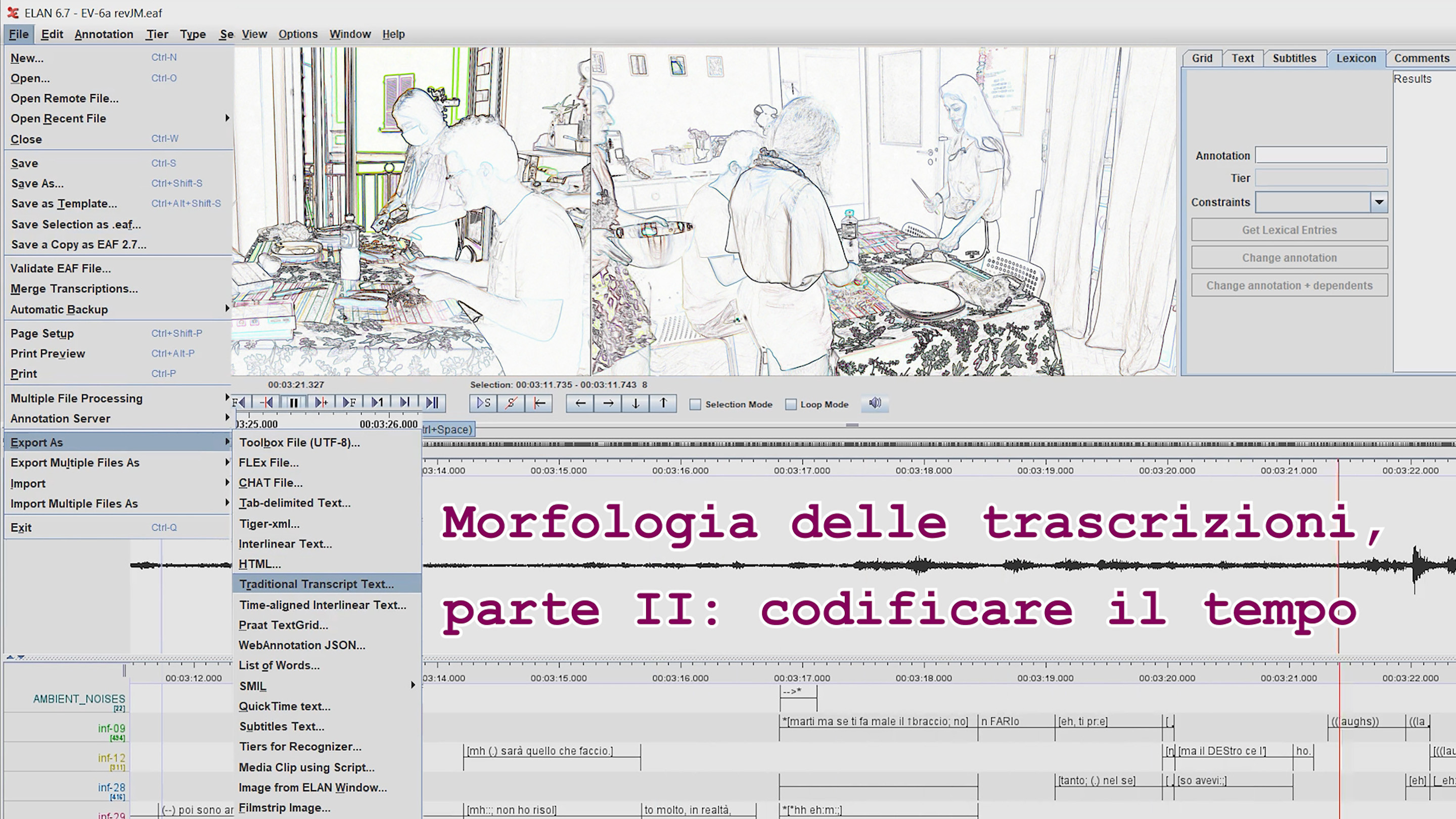
Nella gestione dei dati il problema dell'#interoperabilità si pone a vari livelli. In questo mese su ShareTIGR rifletteremo sul formato delle trascrizioni eseguite manualmente ascoltando conversazioni audio- e videoregistrate.
Morfologia delle trascrizioni, parte I: leggibili in che modo? https://sharetigr.usi.ch/it/news/feeds/38046
Una #trascrizione prodotta mediante un annotatore multimediale - come ELAN, che abbiamo usato nel progetto InfinIta - contiene del codice informatico che ha bisogno di software specializzato per essere visualizzato e interpretato correttamente. Quando si trasmettono le proprie trascrizioni ad altri/e studiosi/e, conviene perciò chiedersi: Quali applicazioni useranno i/le futuri/e utenti? Quelle applicazioni sapranno leggere i documenti creati dal nostro programma di trascrizione?
#FAIRdata #opendata #openresearchdata #spkenlanguage #transcription #italianoparlato #corpuslinguistics
@dh
@linguistics
Exploring LaRS @ SWISSUbase : https://lnkd.in/e6YKynrx. The Language Repository of Switzerland LaRS offers a specific file and #metadata structure for the studies deposited on the platform. In the sixth post of the ShareTIGR lab blog, we look into the details of this structure and into their implications for the searchability and findability of the #data records stored on the repository. #dh #fairdata #openresearchdata
Dall'evento al dataset: https://sharetigr.usi.ch/en/news/feeds/37851
Each event of the #TIGRcorpus includes various kinds of documents:🎤🎥 A/V recordings, 📋 technical notes, 📜 various kinds of transcripts and 🎞 an edited video. We present them and ask if they are primary or secondary data 🤔
#languagedata #fairdata #videodata #linguistics #corpuslinguistics #italianoparlato #linguaitaliana #openresearchdata
@linguistics @dh
Our work is partially supported by the ETH domain #OpenResearchData efforts to bridge gaps between various research infrastructures. We look forward to this next stage as we grow to support more diverse use-cases and build up #interoperability with other like-minded services.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst