
Avi Chawla (@_avichawla)
RULER의 핵심 통찰은 절대 점수 부여보다 상대적 스코어링이 더 쉽다는 점입니다. LLM 심판이 각각에 절대 점수를 매기기보다 '궤적 A가 B보다 낫다'처럼 상대 비교를 통해 판단하는 것이 보상 평가에서 더 간단하다는 설명을 담고 있습니다.
Avi Chawla (@_avichawla)
RULER의 핵심 통찰은 절대 점수 부여보다 상대적 스코어링이 더 쉽다는 점입니다. LLM 심판이 각각에 절대 점수를 매기기보다 '궤적 A가 B보다 낫다'처럼 상대 비교를 통해 판단하는 것이 보상 평가에서 더 간단하다는 설명을 담고 있습니다.
MiniMax (official) (@MiniMax_AI)
CISPO를 GSPO 또는 GRPO 대신 선택하는 이유와 MoE(전문가 혼합) 적응성, RL 알고리즘 변경 시 아키텍처 리팩토링 요구 여부에 관한 질문과 논의입니다. 언급된 내용으로는 GRPO가 이전에 존재했으나 R1-Zero 재현 시 신뢰성이 낮았고, PPO 스타일의 클리핑이 토큰 수준 그래디언트 문제를 일으켰다는 경험적 관찰이 포함됩니다.
khazzz1c (@Imkhazzz1c)
토큰 단위 보상 신호(token-level reward signals)가 '완벽'해진다면, 평가 역할을 하는 critic 모델(가치 평가자)이 불필요해지는지 묻는 이론적·연구적 질문을 제기하고 있습니다.
What #Xi ’s Purge Of A Top General Means For #China And Its Neighbors
#RFE #RL #ZhangYouxia
https://www.rferl.org/a/china-general-zhang-youxia-military-russia-central-asia-taiwan/33660395.html
😃 💚 Hallo, moin, tach. 💚 Danke allen neuen FollowerInnen (m/w/d), es ehrt und freut mich sehr. 💚 Bin zurzeit nicht so präsent, bei mir im #RL brennt nicht nur die Luft.
Schaue mir alle an und folge gerne zurück, wenn es passt. 😉 😘
#Musik #Mucke #music
🎼 Streets of Philadelphia - Bruce Springsteen - 🎶
https://www.youtube.com/watch?v=4z2DtNW79sQ

😃 💚 Hello, everyone. 💚 Thank you to all my new followers (m/f/d), I am very honored and delighted. 💚 I'm not very active at the moment, as things are pretty hectic in my #RL.
I'll take a look at everyone and will be happy to follow back if it suits me. 😉 😘

Latest in the spat with my brother (who voted for Trump the first time and apparently just skipped the next two elections) - He refused to accept the xmas money I sent. I asked him to explain how he could support any part of Trump's behavior, and got silence in return. So yeah. Not the first time he's just left me on read about this stuff, so guess we'll see. Think he'll change his tune when he tries to cancel the midterms? #uspol #rl
TheCoderUX (@Motion_Viz)
코드 최적화를 RL(강화학습)으로 학습시키는 API를 발견했다는 내용입니다. iterx(작성자 @deep_reinforce)가 제공하는 4단계 루프(예: POST /api/task/create, /api/fetch_unevaluated_code_ids 등)를 통해 작업 생성·대기중인 코드 변형 가져오기 등으로 코드 최적화 작업을 반복적으로 학습시킬 수 있음을 소개합니다.
https://x.com/Motion_Viz/status/2013500237462065421
#rl #reinforcementlearning #codeoptimization #api #developertools
Sebastian Raschka (@rasbt)
저자는 GRPO를 사용해 '검증 가능한 보상(verifiable rewards)'을 갖춘 강화학습을 처음부터 구현하는 내용의 Chapter 6을 완성했다고 알렸습니다. 이번 장을 개인적으로 가장 마음에 드는 챕터라고 평가하며, 이 장의 목표는 검증 가능한 보상 체계를 구현하는 강화학습 방법론을 제시하는 것입니다.
Mới! Notebook Python minh họa RLVR kết hợp GRPO, được triển khai từ đầu trong dự án Reasoning‑from‑Scratch. Tài liệu chi tiết, ví dụ thực tế cho các nhà nghiên cứu RL. #AI #MachineLearning #RL #GRPO #Python #CôngNghệ #TríTuệNhânTạo
https://www.reddit.com/r/LocalLLaMA/comments/1qgcj8b/rlvr_with_grpo_from_scratch_code_notebook/
fly51fly (@fly51fly)
논문 'Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs'은 LLM의 창의적 문제 해결을 위해 희소성(uniqueness)을 인식하고 보상하는 'Uniqueness-Aware RL' 기법을 제안합니다. Z Hu, Y Wang, Y He, J Wu 등(MIT & NUS 공동연구)이 저자로, arXiv에 2026년 공개되어 LLM의 다양성·창의성 향상에 적용 가능성을 검토합니다.
Rohan Paul (@rohanpaul_ai)
AT2PO(Agentic Turn based Policy Optimization via Tree Search)는 도구를 사용하는 LLM 에이전트를 더 빠르고 안정적으로 학습시키기 위한 방법입니다. 에이전트가 불확실할 때 가능한 다음 행동의 트리를 확장하고, 그 중 최적 경로로부터 학습하여 정책을 개선하는 접근을 제안하며 기존의 전체 대화 단위 학습과 차별화됩니다.
🧠 New preprint by Greenstreet, Geerts, Gallego, and Clopath on #MotorLearning across #cortex, #cerebellum, and #BasalGanglia.
Key idea: supervised learning builds a low-dimensional action embedding, and #ReinforcementLearning operates directly in this structured space. This explains generalization, interference, and striatal similarity patterns as geometric consequences, not add-ons.
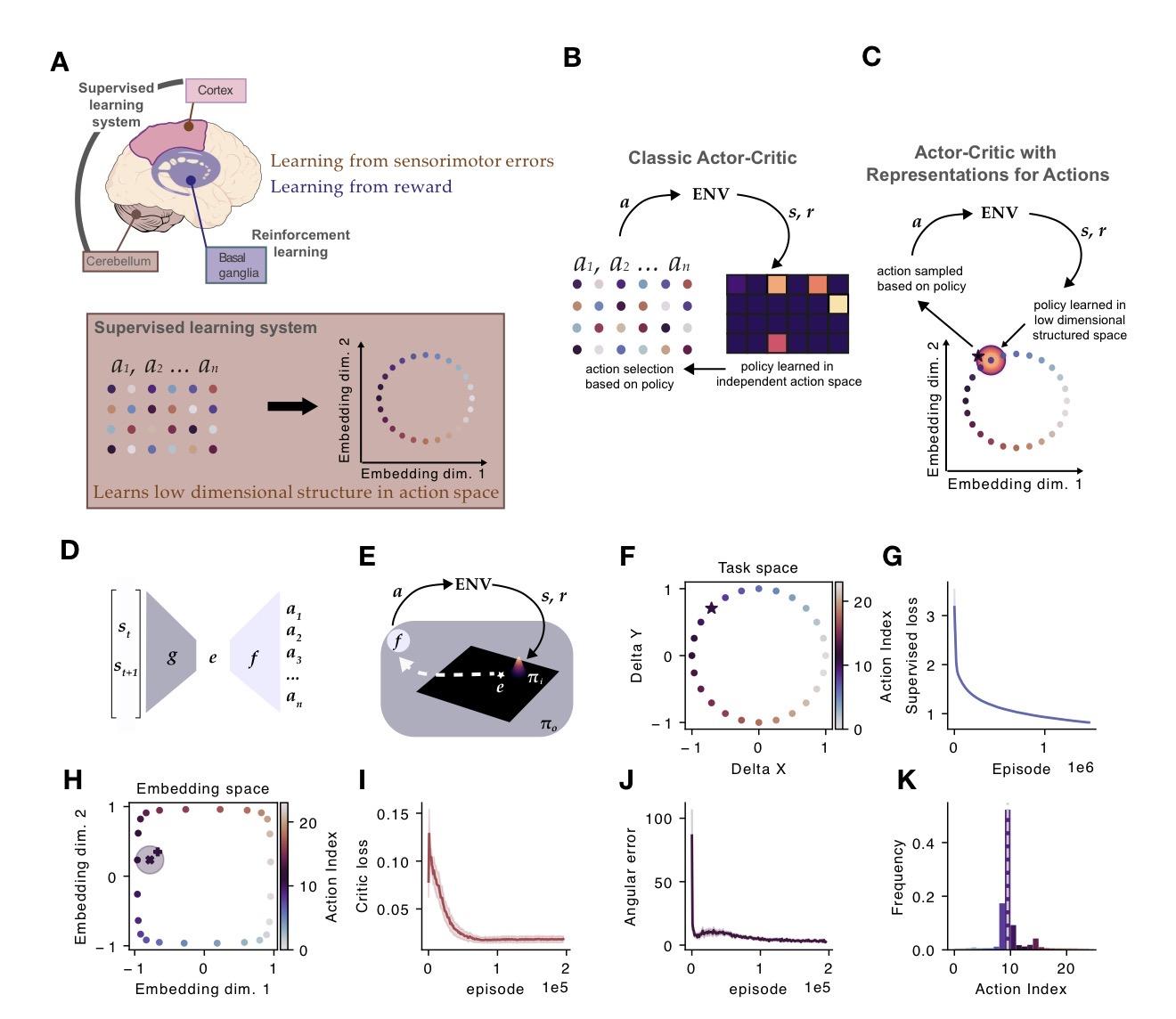
swyx (@swyx)
Cursor와 OpenAI 추론팀 소속 @ashvinair가 참여한 인터뷰를 포함한 'holiday drops'를 확인하라는 안내입니다. 해당 인터뷰는 강화학습(RL) 연구의 현황과 관련 논의를 다루는 것으로 보이며, RL 연구 동향을 파악하거나 관련 연구 업데이트를 확인하는 데 유용할 것으로 예상됩니다.
Richard Sutton – Father of RL thinks LLMs are a dead end
https://www.youtube.com/watch?v=21EYKqUsPfg
Richard Sutton is the father of reinforcement learning, winner of the 2024 Turing Award, and author of The Bitter Lesson. And he thinks LLMs are a dead end.
This is an interesting interview.
Private equity deal shows just how far America’s legacy rocket industry has fallen https://arstechni.ca/ZVUM #privateequity #propulsion #rocketdyne #L3Harris #Space #rl-10 #RS-25
Michelle Bakels (@MichelleBakels)
Day 16 업데이트로 여러 영상 링크와 주제를 공유한 내용입니다. Arman Hezarkhani( Tenex)의 'Paying Engineers like Salespeople'와 함께 'State of RL/Reasoning' 관련 논의에서 IMO/IOI Gold, OpenAI o3/GPT-5, 그리고 Cursor Composer 등이 언급되었고 Ashvin Nair( Cursor)의 관련 발언도 함께 소개됩니다.
Spent an hour trying to get Fallout 76 (the Microsoft app store version) to stream from the desktop to my laptop so I could be cozier. No dice.
Did start Detroit: Become Human and decided pretty quick that wasn't the mood I wanted to go into the new year in. (For those who haven't played it, imagine playing various androids and experiencing racism from society plus the slavery of your programming.)
Returning home after spending xmas with the family is like PCD, but worse in ways.
After a con it's 'I won't get to be myself until next con'
After family visits it's 'I had to aggressively be less-myself the whole time' but still with the drop that comes from returning to a cold, empty home.
I know it's on me. If I came out to my family I could be more myself and it's up to them if they accept a more-genuine me. Just a coward who doesn't want to put up with condescending 'phase' stuff. #RL
MiniMax (official) (@MiniMax__AI)
우리 팀의 RL & Eval 책임자 @olive_jy_song이 AIE NY에서 발표했으며, 전문가(Experts-in-the-loop)가 다국어 코딩 성능 강화를 이루는 데 핵심적 역할을 했고 그 성과가 M2.1에서 입증되었다는 내용입니다. 다국어 코드 처리와 평가 루프를 통한 모델 개선 사례를 공유한 발표 소식입니다.







