📢 Don't overlook this in the wave of releases! #MistralAI has a new coding LLM: it's #Devstral, an open model perfect for on-prem, private and local deployments 🐈
📰 Have a look at the announcement: https://mistral.ai/news/devstral
📢 Don't overlook this in the wave of releases! #MistralAI has a new coding LLM: it's #Devstral, an open model perfect for on-prem, private and local deployments 🐈
📰 Have a look at the announcement: https://mistral.ai/news/devstral
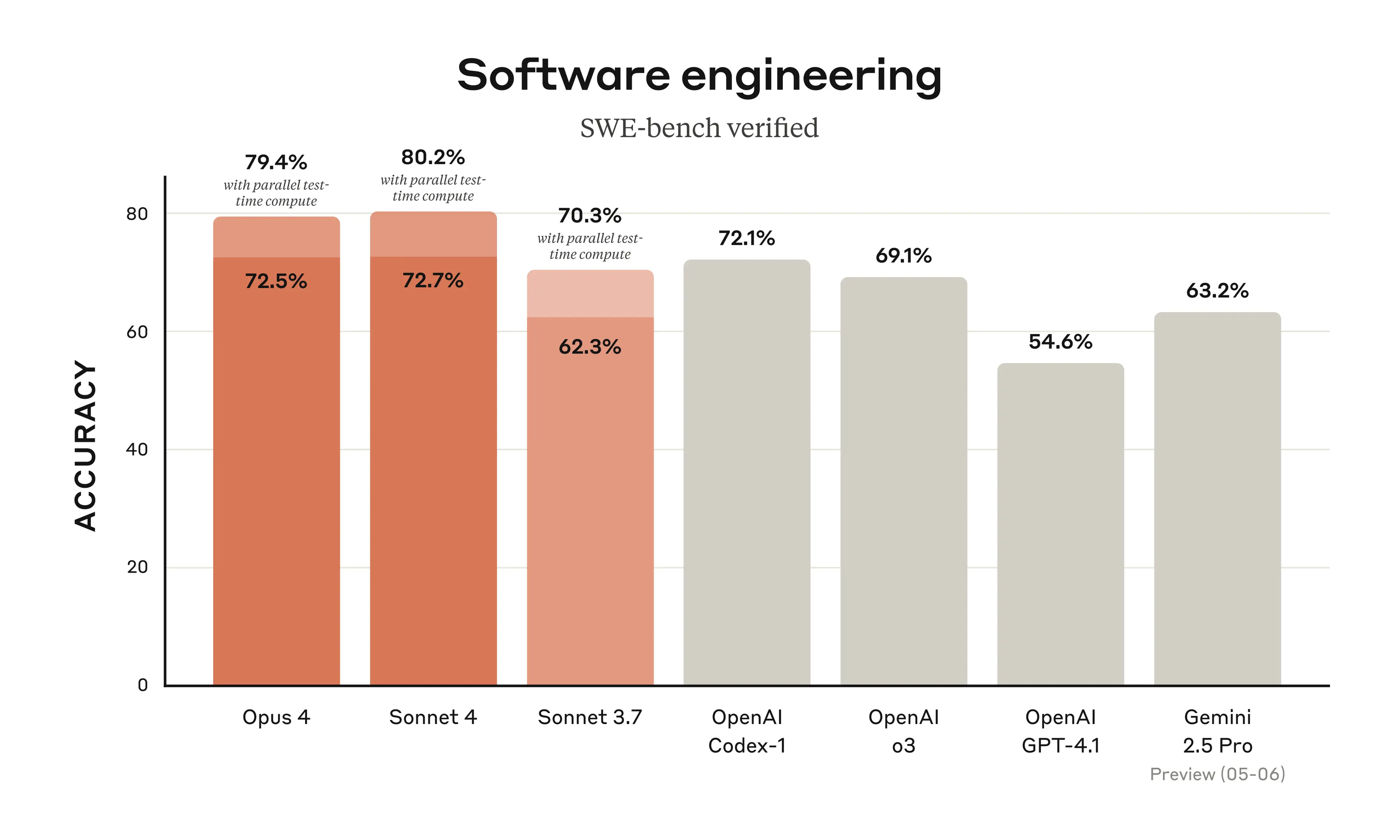
🧠 Another flagship model released! #Anthropic just unveiled Claude Opus 4 and Claude Sonnet 4, and they are at the top of the leaderboard for coding 💻
📰 Check out the announcement: https://www.anthropic.com/news/claude-4
🎉🥳 OMG, Refact.ai scored a groundbreaking 69.8 on #SWEbench and now it's charging you in coins! 💰🔧 Apparently, solving 349 out of 500 tasks makes it the reigning champion of open-source AI agents. Who knew moving from request limits to coin tossing was the future of tech? 🤪👨💻
https://refact.ai/blog/2025/open-source-sota-on-swe-bench-verified-refact-ai/ #RefactAI #openSourceAI #techInnovation #coinTossing #HackerNews #ngated
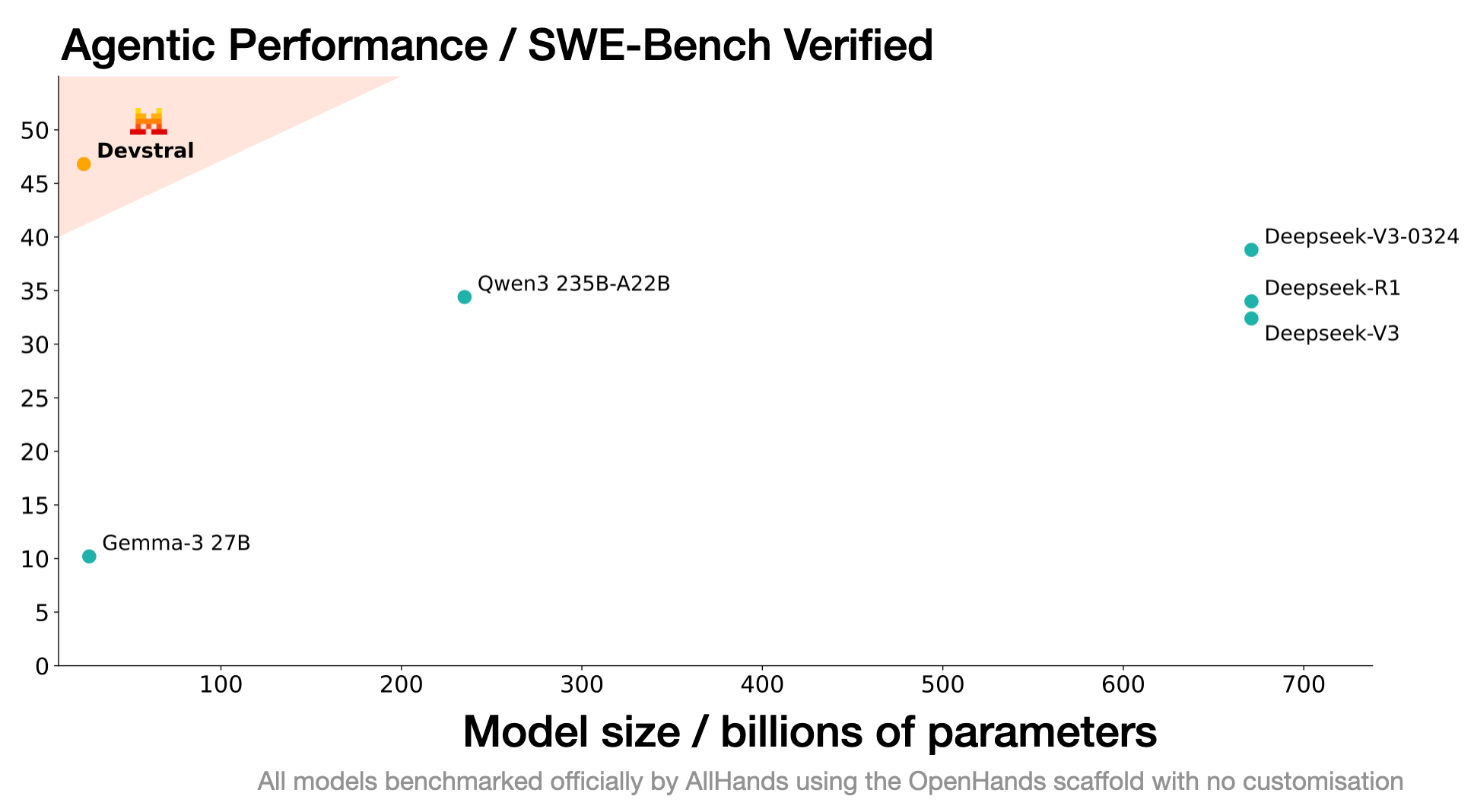
#Devstral: New #opensource Model for Coding Agents by #MistralAI & #AllHandsAI 🧠
• 🏆 #Devstral achieves 46.8% on #SWEBench Verified, outperforming previous #opensource models by over 6% points and surpassing #GPT4 mini by 20%

Как мы собираем SWE-bench на других языках
Современная разработка ПО — это плавильный котел языков: Java, C#, JS/TS, Go, Kotlin… список можно продолжать. Но когда дело доходит до оценки ИИ-агентов, способных помогать в написании и исправлении кода, мы часто упираемся в ограничения. Популярный бенчмарк SWE-bench, например, долгое время поддерживал только Python. Чтобы преодолеть разрыв между реальностью разработки и возможностями оценки ИИ, наша команда в
https://habr.com/ru/companies/doubletapp/articles/901032/
#swebench #ии #нейросети #ml #машинное_обучение #искусственный_интеллект #github #open_source
[Перевод] Сравнение бенчмарков LLM для разработки программного обеспечения
В этой статье мы сравним различные бенчмарки, которые помогают ранжировать крупные языковые модели для задач разработки программного обеспечения.
https://habr.com/ru/articles/857754/
#LLM #бенчмарки #бенчмаркинг #HumanEval #DevQualityEval #CodeXGLUE #Aider #SWEbench #ClassEval #BigCodeBench
🚀 #Claude35Sonnet is now rolling out on #GitHubCopilot, bringing advanced coding capabilities directly to #VisualStudioCode and https://GitHub.com
• 🏆 Performance highlights:
- Highest score among public models on #SWEbench Verified
- 93.7% accuracy on #HumanEval for #Python function writing
• 💻 Key features:
- Production-ready code generation
- Inline debugging assistance
- Automated test suite creation
- Contextual code explanations
• ⚙️ Technical details:
- Runs via #AmazonBedrock
- Cross-region inference for enhanced reliability
- Available to all #GitHub Copilot Chat users and organizations
🚀 #Anthropic announces major updates to their #AI model lineup:
💻 Upgraded #Claude35Sonnet shows significant improvements:
• Achieves 49% on #SWEbench Verified coding benchmark
• Leads in software engineering capabilities
• Maintains same price and speed as predecessor
• Tested by US and UK #AI Safety Institutes
🔄 New #Claude35Haiku introduction:
• Matches #Claude3Opus performance at lower cost
• Scores 40.6% on SWEbench Verified
• Optimized for user-facing products
• Available across multiple cloud platforms
🖱️ Pioneering #ComputerUse beta feature:
• Allows AI to navigate interfaces like humans
• Scores 22% on #OSWorld benchmark
• Currently in experimental phase
• Supported by new safety classifiers
⚡ Enterprise adoption:
• #GitLab reports 10% improvement in DevSecOps tasks
• #Replit leverages computer use for app evaluation
• #Cognition notes enhanced problem-solving capabilities
How do AI software engineering agents work?🤔🤖
Find the answer, along with valuable insights from the creators of SWE-bench & SWE-agent, in this article⬇️
Great read! 👏 @gergelyorosz, @elin Nilsson
#AI #SWEbench #SWEagent #softwareengineering