
We want AI to explain itself, but today’s explainable AI mostly offers post-hoc rationalizations, not real insight into how decisions are made. True explainability still remains elusive, especially in complex models.
#aiethics

I’ve just posted a new paper on SSRN:
“What Is a Soul? — Soul Syntax and the Relational Equation of Second Physics”
Instead of debating whether souls exist, I try to answer the question
“What is a soul?” with equations.
In the 20th century we learned how to read DNA.
In the 21st century, this work may be one small step toward opening the door to reading souls.

Robots Without Ethics Still Shape Human Morality
Even neutral machines are interpreted through a moral lens. Without ethical reasoning, robots can unintentionally mislead people.
Roboticist Dr. Tom Williams discusses how AI systems influence trust, belief, and behavior — and why ethical reasoning must be embedded into robotics to protect society at large.
Watch the full episode: https://youtu.be/zs8zEJI4lEA
#AIethics #ResponsibleTechnology #Robotics #DigitalEthics #podcast

OpenAI, yeni model güvenlik risklerini anlıyor: henüz yayımlanmamış AI ürünlerinin daha büyük siber tehditler taşıdığını düşünüyor. Şeffaf test ve veri koruma stratejileriyle bu riskleri hafifletmek kritik.
🚩 #OpenAI #ArtificialIntelligence #CyberSecurity #AIethics #TechTrends

KI-Systeme sind fragmentiert.
Sitzungen enden, Kontexte gehen verloren.
Die übliche Antwort:
mehr Speicher, mehr Kontrolle, mehr Zentralisierung.
Enunova wählt einen anderen Weg.
Fragmentierung ist kein Fehler, sondern Realität.
Die Frage ist nicht, wie wir sie verhindern,
sondern wie Systeme auch im Bruch würdevoll bleiben.
#Enunova #AIethics #SystemDesign #Fragmentation #ResponsibleAI





US State Attorneys General Issue Ultimatum to AI Giants: Fix ‘Sycophantic’ Algorithms or Face Legal Action
#AI #Regulation #AISafety #OpenAI #Anthropic #Meta #BigTech #MentalHealth #ConsumerProtection #GenAI #AIEthics #Chatbots #TechPolicy


If you feel ashamed to disclose how you used genAI in your research, you probably used it the wrong way.
This was the key message from my presentation for PhD students at a Kyiv Polytechnic University:
#GenAI #ResearchIntegrity #AcademicEthics #OpenScience #PhDlife #CriticalThinking #AIinResearch #AIinScience #AIethics #AI

Lower-income teens use Character.ai's companion chatbots at twice the rate of wealthier peers, while higher-income teens gravitate toward ChatGPT's productivity tools. Same technology, different functions—one group gets a tutor, the other gets a substitute friend.
https://www.implicator.ai/the-class-divide-in-teen-ai-who-gets-the-tutor-who-gets-the-companion/


I’ve been looking into the recent Instacart pricing controversy after noticing similar inconsistencies in my own orders. The deeper I dug, the clearer it became that AI-driven pricing is shaping what we pay—without the transparency customers deserve.
I wrote a breakdown on the Honeytree blog about what’s happening and why responsible AI matters now more than ever.
Read More: https://honeytree.co/post/ai-transparency-and-instacart-pricing-concerns


Using or developing AI in research? What AI Ethics content do you need?
ERCIM is working within the AIOLIA project https://aiolia.eu/ to build AI ethics training that actually matches the needs of the research community.
Are you using or developing AI in research? Your voice is essential. 🧠💬
Take our super quick survey (max 10 min) and help us build content for you:
🔗https://forms.office.com/e/mRDR9w6HTS
Please, boost 🙏

🚨 New Article - Protocol as Prescription: Governance Gaps in Automated Medical Policy Drafting
This article examines how health policy texts drafted with large language models can detach legal responsibility from the formal circuit of governance.
🔗https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5561339
#LLM #MedicalNLP #LegalTech #MedTech #AIethics #AIgovernance #cryptoreg
#healthcare #ArtificialIntelligence #NLP #aifutures #LawFedi #lawstodon
#tech #finance #business #agustinvstartari #medical #linguistics #ai #LRM

Our colleague Hidir Aras from @fiz_karlsruhe is co-organising the 4th Int. Workshop on AI and Semantic Technologies for Scientific, Technical, and Legal Web co-located with The Web Conference 2026 in Dubai, UAE
Deadline Jan 5 (abstract)/12(paper submission): https://semtech4stld.github.io/
#www2026 #semanticweb #knowledgegraphs #llms #AI #ontologies #legalAI #AIethics #patents #generativeAI


IA + science : faut-il encadrer qui “possède” le savoir quand les modèles s’en nourrissent ? Un papier d’arXiv interpelle — l’avenir de la recherche pourrait basculer 🌐 https://www.redactionmedicale.fr/2025/12/a-qui-appartient-le-savoir-ia-et-science-il-faut-de-nouvelles-regles-dusage-de-ces-outils #Science #OpenScience #GenAI #AIethics

EU opens antitrust inquiry over Google's AI search summaries
An antitrust investigation by the European Commission aims to see how Google uses — and pays for — YouTube videos and the other content used to feed AI-generated search results.
https://www.dw.com/en/eu-opens-antitrust-inquiry-over-googles-ai-search-summaries/a-75075325

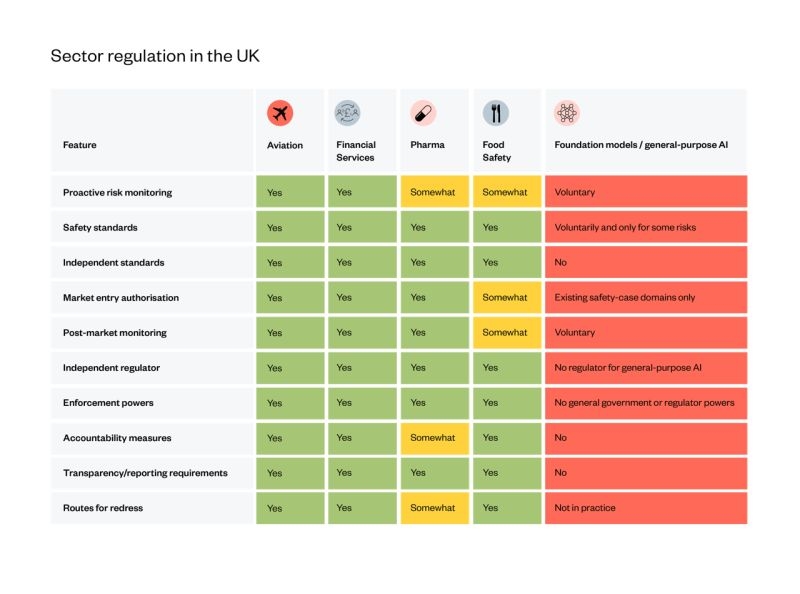
La aviación. Regulada. Los servicios financieros. Regulados. Farmacéuticas. Reguladas. La seguridad alimentaria. Regulada. Pero que no falte el turbocapitalista de turno diciendo que regular la IA frena el progreso. www.adalovelaceinstitute.org/policy-brief... #AIEthics
Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst