https://archive.org/details/2dartistmagazine
Archive.org sigue siendo un regalo para todos.
Aqui os dejo con un montón de numeros del 2DArtist Magazine, para inspiraros.
#ArchiveOrg #2dArtistMagazine #ReferenciasEInspiracionAArtistas
https://archive.org/details/2dartistmagazine
Archive.org sigue siendo un regalo para todos.
Aqui os dejo con un montón de numeros del 2DArtist Magazine, para inspiraros.
#ArchiveOrg #2dArtistMagazine #ReferenciasEInspiracionAArtistas
ArchiveBox - dein eigenes Internetarchiv
#ArchiveOrg #EnsOfTermArchive #LotsMoreSaved
I support Archive dot org
I can't send much, but I do donate every year. I encourage anyone who can, to do so as well
Per A o per B, tinc accés a 9 (NOU) plataformes d'streaming i em cabreja molt quan a cap d'elles hi és disponible un clàssic de fa 70 anys. Ho trobo absolutament indigne.
Sort que continuem tenint archive.org, que fa una feina imprescindible de conservació de material escrit, visual, d'àudio o de qualsevol altra disciplina que pugui digitalitzar.
Feu-los una donació, ni que sigui petita, no em puc imaginar el cost (i la feinada) que porta aquest servei.
This looks like fun - I might give this a whirl! #publicdomain #archiveorg #creative #film
https://blog.archive.org/2025/12/01/2026-public-domain-day-remix-contest/
503 Service Unavailable
No server is available to handle this request.

Today fb reminded me about Torn Flesh Recods... what a flashback!
Under creative commons license and free downloads albums, metal and extreme, on bandcamp and archive.org.
Seems no updated by time but over 1100 album still there!
Enjoy!
https://archive.org/details/tornfleshrecords
#metal #TornFleshRecords #music #freemusic #archiveOrg #CreativeCommons #NetLabel
#djfreak #sterozza #annwn #chlorophyllfluxbunny #circuitparalelle #terrymullet #xfa #trampelfad #sadistic #chaosvg #memero #free #mix #archive #sci-fi #flashcore #experimental #bass #industrial #breakcore #noise #music #IDM #download #archiveorg #dj #mix
Marvellous mix by Dj Freak featuring two tracks from my new album "No gods, only everlasting compost".
Dialog unterm Galgen – Der Fall Ohlendorf – Gerhard Zwerenz
Der Fall Ohlendorf basiert auf Protokollen des ersten Nürnberger Prozesses gegen die Hauptkriegsverbrecher, bei dem Ohlendorf als Zeuge aussagte, sowie dem 9. Nürnberger Prozess, ´The United States of America against Otto Ohlendorf, et al.´, dem sogenannten Einsatzgruppen-Prozess. Gerhard Zwerenz´ Hörspiel zitiert teils wörtlich aus den Prozessen die mit verhaltenem Entsetzen gestellten Fragen des Anklägers und die Antworten des fast unbeteiligt erscheinenden Angeklagten. Zum Hintergrund: Nach der deutschen Invasion der Sowjetunion 1941 befehligte Ohlendorf auf Anweisung von Heinrich Himmler bis Juni 1942 die Einsatzgruppe D, die in der Südukraine und im Kaukasus operierte. Die SS-Einsatzgruppen hatten die Aufgabe, die in den eroberten Gebieten lebenden Juden und Führungskader der Kommunistischen Partei der Sowjetunion zu vernichten. Ohlendorf war damit verantwortlich für die Ermordung von etwa 90.000 Menschen. Otto Ohlendorf wurde am 7. Juni 1951 hingerichtet.
Gerhard Zwerenz (1925–2015), deutscher Schriftsteller, wurde in Gablenz in Sachsen geboren. Seit 1956 arbeitete Gerhard Zwerenz als freiberuflicher Schriftsteller.
#archiveOrg #einsatzgruppenProzess #gerhardZwerenz #horspiel #nazis #ottoOhlendorf
Here is your seasonal reminder that all of #WKRP is available on #archiveorg, including the #TurkeysAway episode we're all so fond of this time of year. You can stream it, or download them all for offline viewing while you cope with family time tomorrow.
https://archive.org/details/wkrp-s-1-e-20-young-master-carlson/WKRP+S1E07+Turkeys+Away.mp4
continuano (finché continuano) le pagine di questa specie di differxdiario
tipo, oggi, qui:
https://noblogo.org/differx/con-tutti-sti-substack-e-pagine-fb-e-profili-professionali-su-instagram
https://differx.noblogs.org/2025/11/26/continuano-finche-continuano-le-pagine-di-questa-specie-di-differxdiario/
#kritik #teoria #TestiDiMgOnline #Archiveorg #diario #differx #differxdiario #fediverso #friendica #Mastodon #media #MediaGeneralisti #noblogo #noblogsorg #social #SocialGeneralisti
wayback machine
salvare gli immani monnezzoni!
https://noblogo.org/differx/ego-scripsit-years-ago
https://differx.noblogs.org/2025/11/25/wayback-machine/
#ZinesAuthors #Archiveorg #monnezzoni #poesia #WaybackMachine
Wer ist Wer? – Von Rod Beacham
Sir John Carlyle, ein reicher Baulöwe mit schmutzigen Nebengeschäften, engagiert über einen Mittelsmann einen Auftragskiller. Ein belastender Brief muss gefunden und sein Besitzer beseitigt werden. Noch heute Nacht, im Nachtexpress von London nach Edinburgh. Wenig später trifft eine illustre Gesellschaft im Schlafabteil des Zugs aufeinander: ein junger Verleger, der ungarische Schachgroßmeister Hans Tabor, eine Londoner Salondame und der Geschäftsmann Henry Carstairs. Wer ist der Jäger und wer der Gejagte? – https://archive.org/details/wer_ist_wer
https://dn710207.ca.archive.org/0/items/wer_ist_wer/wer_ist_wer.mp3
#archiveOrg #horspiel #krimi #peterFricke #rodBeacham #werIstWer
Il se passe un truc. Vous savez pourquoi la Wayback Machine a arrêté de sauvegarder aussi souvent les sites web depuis mai ?
La wayback est passée de "Sauvegarder plusieurs fois par jour" certains sites avant mai, à "Presque une seule sauvegarde par mois" en octobre 2025.
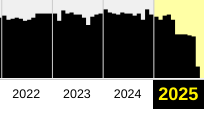
The Wayback Machine appears to be offline, according to testing and public reporting.
According to a post on their official social media account, the outage was caused by some network gear failing.
https://mastodon.archive.org/@internetarchive/115582351252189547
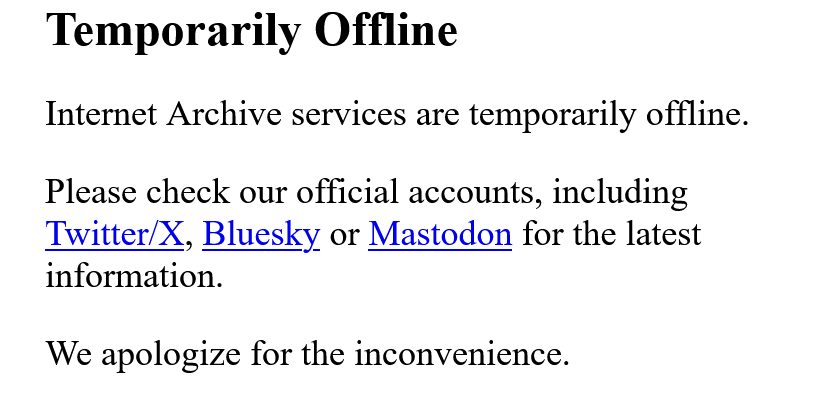
Ah Putain Ces Enculers D'internet Archive On Viré Mes Photos Des Quai De Moênne Et Moênne Le Soir, C'est Malin Je Doit Les Envoyé Sur MEGA Du Coup.
Apparament Internet Archive Veulent Pas Mon Monde.
Jedes Ding ein Gefäß – Von Rainer Maria Rilke
„Noch für unsere Großeltern war fast jedes Ding ein Gefäß, indem sie Menschliches vorfanden und Menschliches hinzu sparten. Nun drängen, von Amerika her, leere, gleichgültige Dinge herüber, Schein-Dinge, Lebensattrappen. –
Die belebten, die erlebten, die uns mitwissenden Dinge gehen zur Neige und können nicht mehr ersetzt werden. Wir sind vielleicht die letzten, die noch solche Dinge gekannt haben. Auf uns ruht die Verantwortung, nicht allein ihr Andenken zu erhalten. Das wäre wenig und unzuverlässig, sondern ihren humanen und larischen Wert (larisch im Sinne der Hausgottheiten.)
Die Erde hat keine andere Ausflucht, als unsichtbar zu werden: in uns! … Die wir mit einem Teil unseres Wesens am Unsichtbaren beteiligt sind, Anteilscheine (mindestens) haben an ihm, und unseren Besitz an Unsichtbarkeit mehren können während unseres Hier seins, – in uns allen kann sich diese intime und dauernde Umwandlung des Sichtbaren in Unsichtbares, vom sichtbar- und greifbar- sein nicht länger abhängiges vollziehen, wie unser eigenes Schicksal in uns fortwährend zugleich vorhandener und unsichtbar wird“.
https://web.archive.org/web/20100311224745/http://daoweg.wordpress.com/
#archiveOrg #erde #larisch #lebensattrappen #rainerMariaRilke #unsichtbarkeit #wissen #zitat
I Dream Of Wires - Part 2
Hardcore Edition
Part Two: the Resurrection, and Phenomenal Resurgence, of the Modular Synthesizer
https://archive.org/details/i-dream-of-wires-hardcore-edition-part-2
#music #documentary #history #modular #synthetizer #ambient #electronic #electronicmusic #spacemusic #berlinschool #sequencer #synth #modularsynth #analogsynth #atmospheric #soundscapes #archive #archiveorg
I Dream Of Wires - Part 1
Hardcore Edition
Part One: the Dawn, and near extinction of the Modular Synthetizer
https://archive.org/details/i-dream-of-wires-hardcore-edition-part-1
#music #documentary #history #modular #synthetizer #ambient #electronic #electronicmusic #spacemusic #berlinschool #sequencer #synth #modularsynth #analogsynth #atmospheric #soundscapes #archive #archiveorg
“Archiving Your Tweets at Archive.Org” for Dummies
[UPDATE: As of May 26, 2025, I don’t think the instructions on this page work anymore, because I believe Twitter/X has blocked archive.org from archiving tweets.]
I’m all done with Twitter, but I also didn’t want to just delete my account and remove over a decade of content that I created from the internet. I’m not so arrogant as to believe that anyone’s ever going to want to look at my tweets again, but (a) maybe I will want to link to one of my historical tweets at some point in the future when talking about something else online, and (b) I’m worried about the historical record that Twitter represents and the fact that if it disappears a great source for future historical research will be lost.
For all these reasons, I decided that before deleting all of my tweets and locking my account, I was going to archive my tweets at archive.org using the instructions they provide. Unfortunately, I found those instructions to be somewhat vague, and furthermore I discovered that they didn’t archive all of my tweets the first time around and I had to resubmit some of them a second time. I’ve put together this blog posting to give people more detailed instructions for how to archive your tweets successfully.
Step 1: Ask archive.org to generate a list of potential archive URLs for you
data/tweets.js from it.tweets.js file for upload, and click the “Upload” button.Step 2: Filter out the bad URLs so archive.org doesn’t have to do work trying to archive them
Here is where my instructions start to diverge from the ones provided by archive.org. Some of the URLs in the list that archive.org gave you are no longer valid. It will help archive.org archive your tweets faster, and reduce unnecessary load on its servers, if you get rid of those URLs before submitting the list to archive.org. You can use this script to do that:
Save this script to your computer, e.g., as wayback-check.py, make sure you have the Python 3 requests module installed, and run something like python3 wayback-check.py --fetch twitter-urls.csv > filtered-urls.csv to generate a new file called filtered-urls.csv with the URLs that archive.org shouldn’t attempt to archive filtered out.
Step 3: Create a Google Sheet for archive.org to read URLs from
We’re now back on the standard archive.org instructions track.
Step 4: Submit the list of URLs to archive.org for archiving
You don’t need to leave this web page open; the archiving process will continue to run even if you close it. Archive.org will eventually sent you an email telling you that it has started processing your request with a link for monitoring the status of the request. This email won’t come right away, but it will come. Once it comes, you’ll also be able to see the status of the job at the above wayback-gsheets URL (after logging into Google again).
While the archiving process is running the progress may jump around, i.e., sometimes the number of URLs and percentage completed may go down instead of up. Furthermore, the number of errors reported may jump around as well. I have no idea why this is. In fact, while one of my archive jobs was running for some reason it “cloned” itself and there were two jobs listed with the same status URL. I have no idea why this happened but it didn’t seem to hurt anything.
Eventually archive.org will send you another email telling you that the archiving job is finished. This could take days.
Step 5: After the archiving is finished, check which URLs need to be submitted again
As I mentioned above, I don’t know why, but not all of my tweets were successfully archived on the first pass, so they needed to be submitted again. I wanted to submit just the missing URLs rather than all of them, to minimize the load on archive.org and also minimize the amount of time for the second archiving run. Fortunately the script above will help with this.
python3 wayback-check.py --check-archive filters-urls.csv > filtered-urls2.csv . The newly created CSV will list URLs that still aren’t archived in archive.org.Once the list of remaining URLs is small enough, you can go to archive.org and search the Wayback Machine for individual URLs that are still missing to add them one by one. Note, however, that the “Send me email when done” option there doesn’t seem to work, i.e., the email never seems to arrive, so you’ll have to just wait a while and then search for the URLs again to confirm that they’ve been added.
When you’re all done you can delete all the Google Sheets.
P.S. If you’re relying on the Internet Archive to preserve copies of your tweets forever, then please consider kicking in at least a small donation to help defray the cost of doing that. Storage is cheap, but it isn’t free.