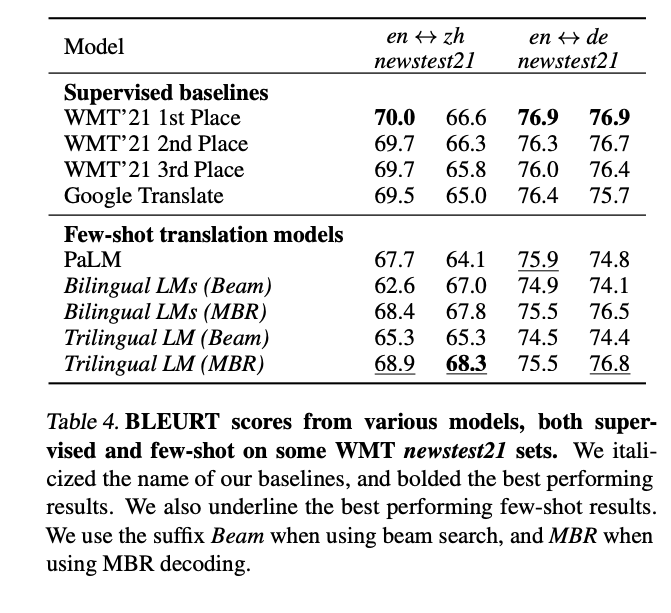
So many warn that evaluating with GPT favors GPT
(or any LLM evaluating itself).
Now it is also shown
Science, not just educated guesses
(Fig: T5, GPT, Bart each prefer their own) https://arxiv.org/abs/2311.09766
#enough2skim #scientivism #NLP #nlproc #GPT #LLM #eval #data