Recently learnt about the #C 23 feature _BitInt, which vastly simplifies writing the GHASH128 algorithm. I wonder if #LLVM will emit a i128 if the same algorithm is written with a struct.
#llvm
Also I am curious about #FreeBSD with #ports and #poudriere, how do you guys manage #Firefox and possibly #LibreOffiice? It took me~5h to compile #LLVM default flavor on my laptop, I would just assume giants I listed above will take more than 10 hours? I still remember old days when I was using #Gentoo #Linux and whenever there was updates for them I had to keep my PC on overnight...But nowadays #Firefox seems to update more frequently, I dare not to compile few times a month.
#BSD #Unix #UseBSD #RUNBSD #FOSS
#BSD #Unix #UseBSD #RUNBSD #FOSS
Curious if anyone knows why rust produces worse asm for some of these bit munging functions?
Like why isn't 5 the same as 3, it should be doing less work!
Nice to see my initial naive color_3_1 comes out fast though 🦀
I've created my first RFC for #llvm project!
https://discourse.llvm.org/t/rfc-tblgen-generate-linker-code-with-tablegen/86918
My idea is to generate value-inserting code for linker via llvm-tblgen and data from InstrInfo.td
@glocq #Haskell has some cool toys like trifecta, liquid-haskell, and quickcheck, and afaik, there are no equivalents in OCaml. I wouldn't think that outdated #LLVM bindings would bother you so much, as they're pretty easy to generate mechanically: just write a Perl script; it shouldn't take more than a week of work. If the idea is to have fun and keep the compiler small, why not use Haskell? The #OCaml ecosystem is healthier in general, as it is actually used to build real software (by say, Jane Street or the #Rocq community). If ecosystem is so important to you, why not pick #Rust, which has high-quality packages like chumsky/ariadne? Would you be having fun though?
It looks like there are several CRC loops in the wild that would benefit from the proposed optimization: it even has an impact on i2c in the #kernel. The optimization has no compile-time impact when there is nothing to be optimized, so it seems like a clear win. #LLVM
https://github.com/dtcxzyw/llvm-opt-benchmark/pull/2472/files
In what will be a huge improvement to link time/memory footprint and size footprint of generated artifacts in #LLVM, we're making progress on doing dynamic linking by default. This will make life easier for contributors without beefy machines.
https://discourse.llvm.org/t/rfc-llvm-link-llvm-dylib-should-default-to-on-on-posix-platforms/85908
I’ve been working on an optimization that uses the results from the HashRecognize analysis to optimize cyclic-redundancy-check loops, but I’m not sure how to test it rigorously: the CRC pattern is too specific for a fuzzer to generate. So far, I have a pretty comprehensive set of positive tests in llvm-test-suite that verifies the correctness of the optimization, and I’m not sure what more I can do. Any ideas? #LLVM
A couple of weeks ago I published a little blog post about setting up a new #LLVM #Buildbot.
This points out a few changes for actual local development and testing.
Check it out at https://jplehr.de/2025/06/02/testing-and-developing-llvm-buildbots/
clang(1)/llvm/lld(1) updated to version 19 https://www.undeadly.org/cgi?action=article;sid=20250612123207 #openbsd #clang #llvm #lld #development #compiler #update
Part2: #dailyreport #cuda #nvidia #gentoo #llvm #clang
I learned cmake config files and difference between
Compiler Runtime Library (libgcc and libatomic,
LLVM/Clang: compiler-rt, MSVC:vcruntime.lib) and C
standard library (glibc, musl) and C++ Standard Library
(GCC: libstdc++, LLVM: libc++, MSVC STL) and linker
(GCC:binutils, LLVM:lld) and ABI. Between “toolchain”
and “build pipeline”.
Gentoo STL:
- libc++: sys-devel/gcc
- libstdc++: llvm-runtimes/libcxx
Gentoo libc: sys-libs/glibc and sys-libs/musl
I learned how Nvidia CUDA and CUDNN distribud and what
tools PyTorch have.
Also, I updated my daemon+script to get most heavy
current recent process, which I share at my gentoo
overlay as a package.
Part1: #dailyreport #cuda #nvidia #gentoo #llvm #clang
#programming #gcc #c++ #linux #toolchain #pytorch
I am compiling PyTorch with CUDA and CUDNN. PyTorch is
mainly a Python library with main part of Caffe2 C++
library.
Main dependency of Caffe2 with CUDA support is
NVIDIA "cutlass" library (collection of CUDA C++
template abstractions). This library have "CUDA code"
that may be compiled with nvcc NVIDIA CUDA compiler,
distributed with nvidia-cuda-toolkit, or with LLMV
Clang++ compiler. But llvm support CUDA only up to 12.1
version, but may be used to compile CUDA for sm_52
architecture. Looks like kneeling before NVIDIA. :)
Before installing dev-libs/cutlass you should do:
export CUDAARCHS=75
I sucessfully compiled cutlass, now I am trying to
compile PyTorch CUDA code with Clang++ compiler.
Of course llvm target triples can sometimes have four identifiers.
Beautifully showcasing two out of the three two hardest things in computer science 🙃

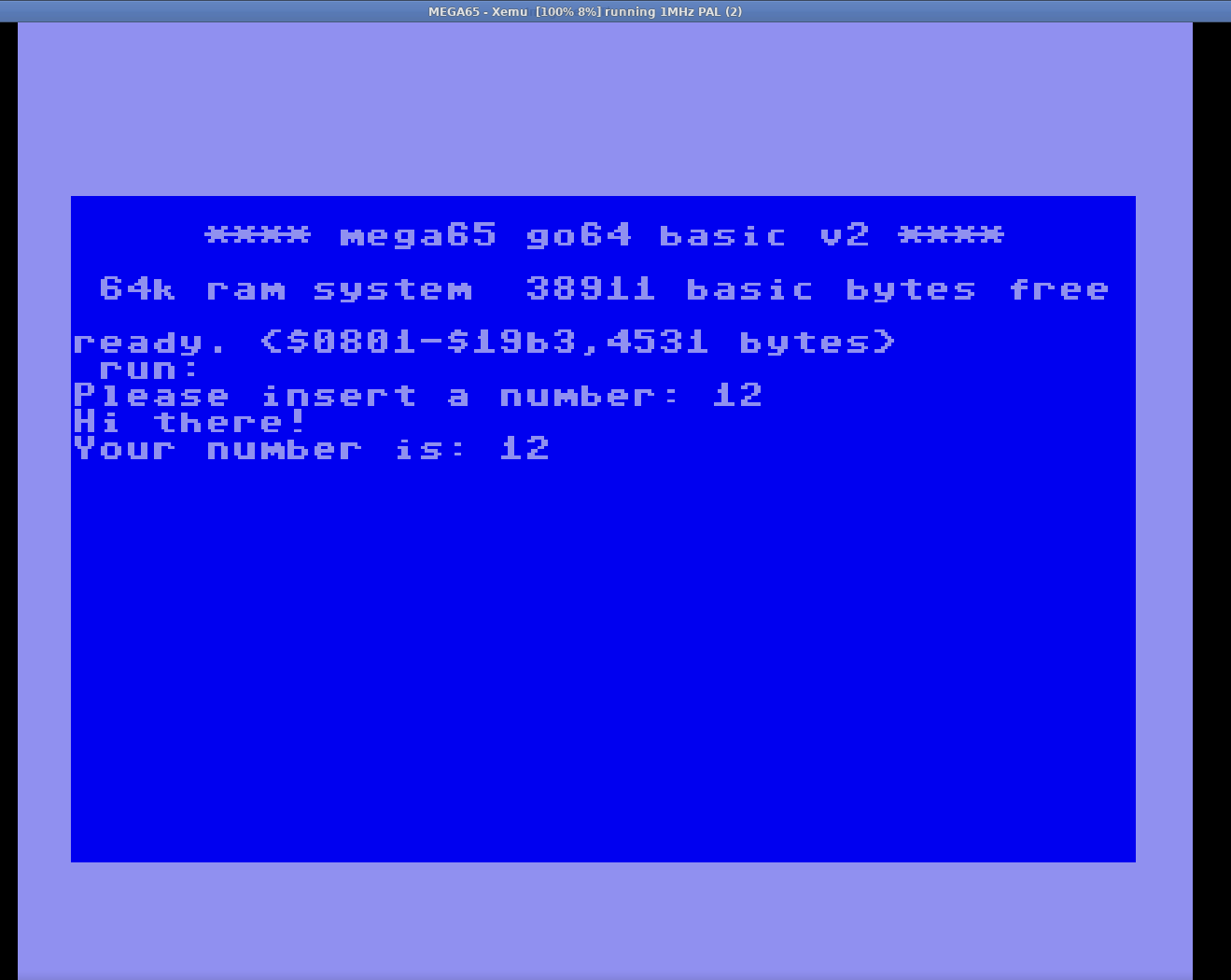
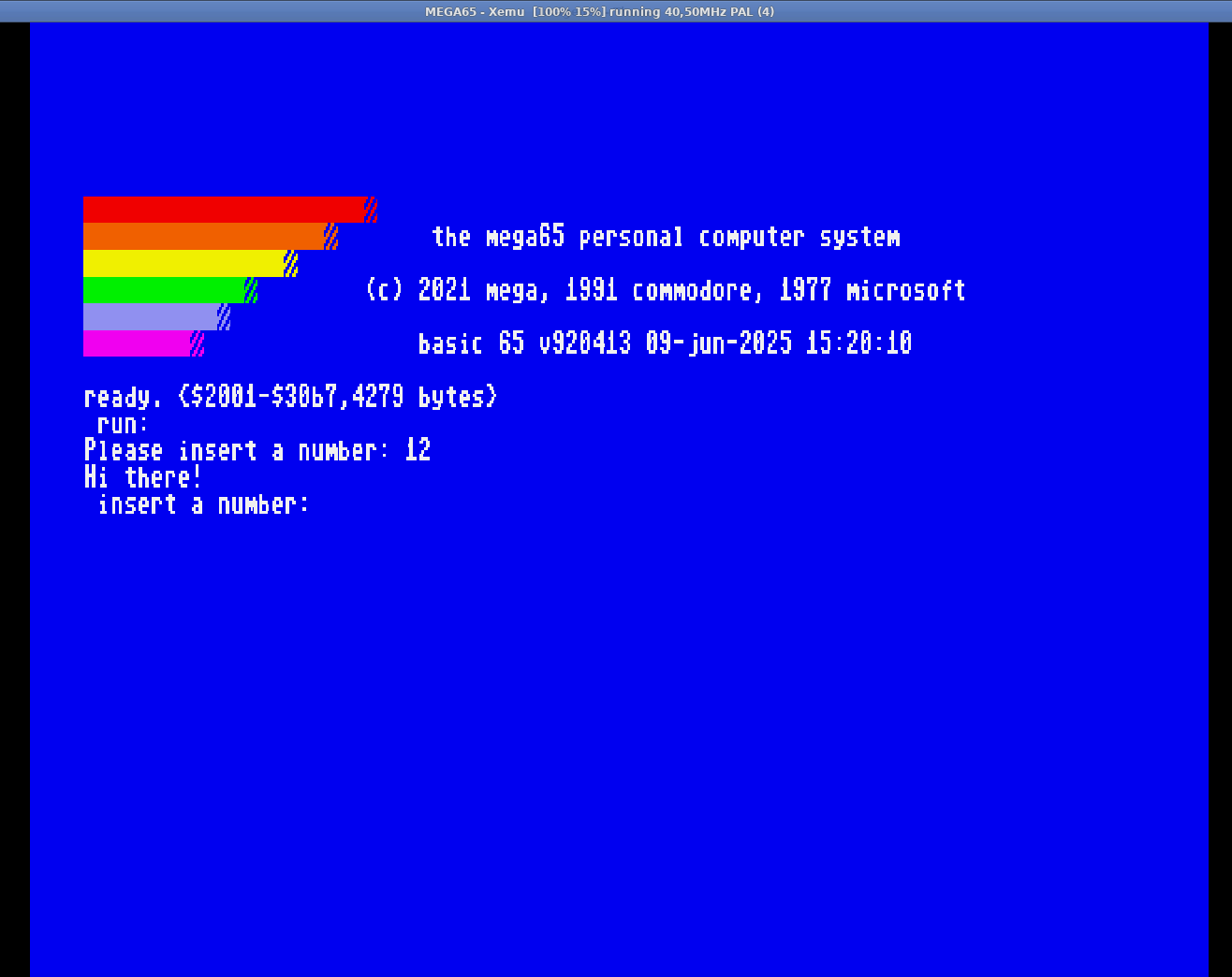
On the other hand I was not so lucky using C. I tried a very simple C program and compiled it with #llvm-mos mos-mega65-clang and it didn't work as expected. I recompiled it using the very same compiler with mos-c64-clang and it works like a charm on the GO C64 mode. I’m not sure yet whether it’s something related to the emulator or the compiler.
🎉 Breaking: Zig devs decide to reinvent the wheel because why not? 🚀 Instead of the tried-and-tested #LLVM, let's use our own x86 backend, just for giggles! Oh, and Windows? Nah, not today, Satan. 🤡
https://ziglang.org/devlog/2025/#2025-06-08 #ZigLang #Reinvention #x86Backend #DevHumor #HackerNews #HackerNews #ngated
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst