New resource for medicines & drug development researchers: Markdown files from regulatory documents (#EMA) in public repository, continually updated. 15,000+ files are semi-structured data. Simple examples, background, contributing: https://regulatorysciencedata.eu/posts/emamds/ #medicines #regulatory #evidence #review

Ralf HEROLD
Paediatrician - Cancer - Medicines Research & Regulatory Science - Information Technology - Public Health - Views my own - https://paediatricdata.eu/
Ralf HEROLD boosted:

My students are often surprised to learn that LLMs aren’t answering their questions. Rather, an LLM answers the question “what would a reply to this look like?” It’s one of the first things I explain in the “Should I use LLMs?” portion of my syllabus.

📬#Regulatory science #research #needs 2025 now available, thanks to work across @european Medicines Agency led by Pierpaolo Moscariello and public consultation💡We seek to engage #academia, #industry and #funders 👉 https://europa.eu/!FyQtVH #Medicines #PublicHealth #RSRN

Tools for trials: update of ctrdata to leverage public #trials #register #data -- accelerated using registers, including the EU Clinical Trials Register with its treasure of structured results data, and modernised some underlying technology, see https://paediatricdata.eu/clinical-trials-analyses-a-tool-for-leveraging-register-data/
@dailydrop.hrbrmstr.dev jora-cli is a great find and suggestion! Would it make sense to create R bindings, perhaps using https://jeroen.r-universe.dev/articles/V8/npm.html, or have you come across any work to link jora-cli with R? Many thanks!
Another great episode for starting a sunny day run, on Maurice Merleau-Ponty #science #neurology #consciousness #laufen https://podcasts.apple.com/de/podcast/in-our-time/id73330895?i=1000700766225
Ralf HEROLD boosted:

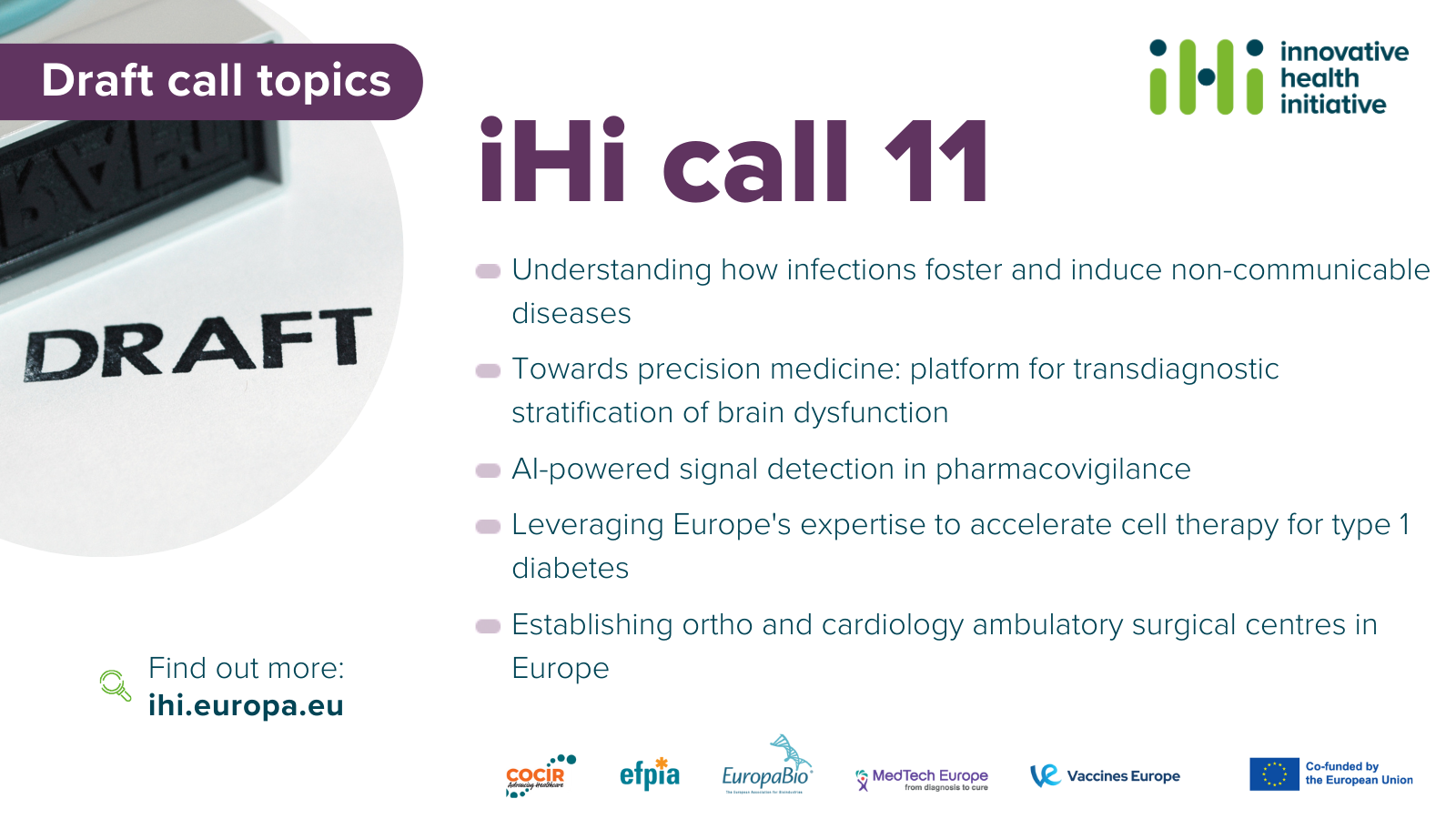
📢 JUST PUBLISHED! Draft topic texts for IHI call 11 at https://europa.eu/!8d3rF8
🔎 The topics for this two-stage call cover #infections, #BrainDisease, #pharmacovigilance, #Type1Diabetes and #surgery
🚴♀️ Get ahead of the game and start studying the topics - the time to start thinking about your proposal and building a consortium is now!
💡 Keep following us for updates on the topics plus alerts for our info sessions.
#IHITransformingHealth #HorizonEU #Health #Research #Funding
Excellent discussion of public private partnerships purpose and impact including for patients by IHI ED Niklas Blomberg (start in video at 10:36:45) @IHIEurope
Brief tool update: across clinical trial registers, analyse data with new pre-defined functions (https://rfhb.github.io/ctrdata/reference/ctrdata-trial-concepts.html) and retrieve trials with new easy "ctrGenerateQueries" function (https://rfhb.github.io/ctrdata/reference/ctrGenerateQueries.html) #clinical #trials #R #research #tool #methodology #health #science
Godspeed, Germany, for general elections of well-meaning colours (blue ain't one)
Interesting work💡on new foundations for discussing trial design & conduct, and seeking to improve, am still digesting: https://mathstodon.xyz/@dcnorris/113995166045270161
Recently on Deutsche Bahn, could not access iceportal.de with my devices using Tailscale and NextDNS. Solution that may also work for similar VPNs: set a DNS entry 172.18.1.110 for iceportal.de
1️⃣ Presentations, recording available: workshop Advancing Regulatory Science Research 18 Nov many thanks 🙏 to great speakers 💙 @EMA_News
2️⃣ Until 18 Dec your comments welcome: on platform and research needs proposed for regulatory science
👉 https://www.ema.europa.eu/en/events/public-event-advancing-regulatory-science-research
Over years, #paediatric & #oncology colleagues asked me about #shortages of #medicines -great that the EU platform launched by #EMA colleagues now monitors shortages, patients & professionals can find supply shortages in our medicines' list 👉 https://www.ema.europa.eu/en/news/european-shortages-monitoring-platform-enables-better-monitoring-shortages-eu

Could you share your thoughts on the drafts: updated research needs in regulatory science + concept for a European platform for regulatory science research? Thank you! Public consultation open until 18 December 2024 #medicines #regulation #science https://www.ema.europa.eu/en/events/public-event-advancing-regulatory-science-research
Join us on 18 Nov 2024 for Advancing regulatory science research - to discuss the new Regulatory science research needs (RSRN) and European platform for Regulatory science research, with academic and regulatory experts and a multi-stakeholder panel 👉 https://www.ema.europa.eu/en/events/advancing-regulatory-science-research
Ralf HEROLD boosted:

The #ELLISPhD application portal is now open! Apply to top #AI labs & supervisors in Europe with a single application, and choose from various research areas and three distinct tracks.
The call for applications: https://ellis.eu/news/ellis-phd-program-call-for-applications-2024
Deadline: 15 November
#PhD #PhDProgram #MachineLearning #PhDinEurope #PhDLife #PhDPosition
Inviting mid-career life science academics to a secondment to the European Medicines Agency: help us advance working with academia for accelerating the translation of academia-originating solutions into medicinal products, drug development tools and regulatory science progress!
Applications welcome until 30 September 2024. Details: https://careers.ema.europa.eu/job/Amsterdam-SNEScientific-Specialist-%28science-&-regulation%29/1111848701/
#medicines #research #publichealth #regulatory #science #regulatoryscience #clinicalresearch #methodsresearch #lifesciences
Ralf HEROLD boosted:

sqlite-vec & sqlite-rembed
Before we begin, a quick note that I tidied up the uk Deno CLI project from the other day, and there’s more comments, a README, and Justfile to make it easier to walk through it. Even if you’re not interested in URL-ops, it’s not a horribad generic example of how to wrap a small JS library into an executable CLI tool.
Also, one update to the Apple Intelligence section from the other day: Apple started giving me AI-generated response suggestions in Messages. I now fear for all textboxes on macOS.
Just one section, today, as we walk through a recent pair of add-ons to SQLite3 that makes it pretty straightforward to get into vector search ops on your own hardware (no OpenAI tax required!).
Type your email…
Subscribe
sqlite-vec & sqlite-rembed
Photo by Skitterphoto on Pexels.comAlex Garcia has made some extensions to the venerable SQLite that makes it (I try not to use this phrase lightly) really easy to get into vector search ops:
sqlite-vecis “an extremely small, [C-based] “fast enough” vector search SQLite extension”. It’s a project sponsored by the Mozilla Builders project.sqlite-rembedis “a [Rust-based] SQLite extension for generating text embeddings from remote APIs (OpenAI, Nomic, Cohere, llamafile, Ollama, etc.)”
There are pre-built extensions for sqlite-vec in the GH releases, and — if you do make release in a cloned sqlite-remebd repo, the targets/release directory will contain the extension for that. For macOS folks: I needed to switch to Homebrew sqlite3 for the extensions to work. YMMV.
Once you have the extensions in a directory, you need some data! I need to go back and add TL;DR’s for legacy Drops, but many of them, now, have such a section, so I threw together a small R script to create a SQLite database from those resource entries:
library(RSQLite)library(tidyverse)# make a sequence from range in a 2-item vectorsseq <- \(.x) seq.int(.x[1], .x[2])# extract the individual entries in the Drop's TL;DR sectionextract_tldrs <- \(.x) { .x <- .x[sseq(which(grepl("^###", .x))[1:2] + c(1, -1))] .x <- .x[(!grepl("^>|^_|^$", .x))] .x[.x != ""] trimws(sub("^\\-", "", .x[grepl("^\\-", .x)]))}# final all Drops with TL;DR sectionsres <- system(r"(rg -l --no-line-number "### TL;DR[[:space:]]*$" ~/projects/dropchat)", intern=TRUE)# read them in posts <- lapply(res, readLines, warn=FALSE)# associate the filename with the resource descriptionsmap2_df(basename(res), posts, \(.drop, .post) { tibble( drop = .drop, tldr = extract_tldrs(.post) )}) |> mutate( id = 1:n() # add an index ) -> xdf# save it outcon <- dbConnect(RSQLite::SQLite(), "~/projects/vector-search/drop.db")dbWriteTable(con, "articles", xdf)dbDisconnect(con) That ended up making ~300 entries:
Rows: 298Columns: 3$ drop <chr> "2023-10-04-index.md", "2023-10-04-index.md", "2023-10-04-index…$ tldr <chr> "This section discusses the anatomy of a mature design system e…$ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, …
You can do something similar with your own content, but be aware that you’ll need to handle breaking it up into segments manually if the each piece is large. That’s why I went with the TL;DR summary entries vs the entire contents of each section.
We’ll be making embeddings from those entries, so we need something to help us do that with our new SQLite3 extensions. I used the mxbai-embed-large-v1 - llamafile (that’s a direct d/l link) llamafile since it’s small and fast. Download it and fire it up at the command line so it’s in server mode.
With the new extensions and that database in the same directory fire up sqlite3 drop.db and prepare for the work:
.load rembed0.load vec0-- this is a required table that the `rembed` function references. -- it knows the URL/port configs for ollama and llamafile but-- you can specify anything that works. the README has all the infoinsert into temp.rembed_clients(name, options) values('llamafile', 'llamafile');-- this will hold our article embeddingscreate virtual table vec_articles using vec0( tldr_embeddings float[1024] ); Now, we need to generate the embeddings:
insert into vec_articles(rowid, tldr_embeddings) select rowid, rembed('llamafile', tldr) from articles; Yep. That’s it. Really!
That took just under eight seconds on my MacStudio (I’ll try it on lesser hardware at some point).
Now, we can just query it! Each query needs embeddings generated for it, too, but that’s quick work. Let’s find top Drops that are about web scraping in some way, shape, or form:
with matches as ( select rowid, distance from vec_articles where tldr_embeddings match rembed('llamafile', 'web scraping tool') order by distance limit 5)select *from matchesleft join articles on articles.rowid = matches.rowid; Despite the vector search operation being plain ol’ brute-force, that query finished in 0.077 seconds and returned entries from the 2023-11-29, 2024-02-21, 2024-02-14, 2024-01-10, and 2023-09-25 (in distance order, which ranged from 0.796438753604889 to 0.844647645950317). These were the entries:
- The edition concludes with a mention of Flyscrape, a tool for internet scraping written in Golang. Flyscrape uses an embedded JavaScript interpreter for configuration and processing functions. The author plans to convert his Capitol insurrection DoJ scraper to Flyscrape and will report back on the results. The tool can be installed via a command provided in the post or through pre-built binaries on the site source.
- Waybackpack: A command-line tool for downloading the entire Wayback Machine archive for a given URL, allowing users to scrape data from older versions of resources or resources that have disappeared. Installation and usage instructions are available at https://github.com/jsvine/waybackpack.
- Webhook.Site: An online tool that provides a unique, random URL (and email address) for testing webhooks or arbitrary HTTP requests. It displays requests in real-time for inspection without needing own server infrastructure. The site also features a custom graphical editor and scripting language for processing HTTP requests, making it useful for connecting incompatible APIs or quickly building new ones.
- The post discusses two tools for archiving and preserving digital content. The first tool is Monolith, a Rust-based CLI tool that can convert any HTML page into a self-contained HTML file. This tool embeds all necessary assets such as CSS, JavaScript, and images into a single HTML file, allowing for offline access and preservation of the original webpage.
- tldts: A JavaScript library for extracting hostnames, domains, public suffixes, top-level domains, and subdomains from URLs. It is fast, supports Unicode/IDNA, and is continuously updated. Check it out on npm and GitHub.
(I never did do the Flyscrape thing.)
Not a bad job for a terrible query!
I tried “monospace font” and the first result was the post on Monaspace (older posts with monospace font content had no TL;DR, remember), and “docker or container” had solid top three results for this corpus. Oddly enough, neither “syntax highlight” nor “terminal editor” had the results I thought they would in the top five.
One really nice thing about sqlite-vec is that it runs everywhere (including SQLite in the browser). Which means browser-based search for, say, static sites will soon be leveled up quite a few notches.
Both of these extension are in the early stages of development, so they’re only going to get better (they’re already pretty dope), and they’re definitely helping democratize working with embeddings and vector search.
FIN
Remember, you can follow and interact with the full text of The Daily Drop’s free posts on Mastodon via @dailydrop.hrbrmstr.dev@dailydrop.hrbrmstr.dev ☮️
https://dailydrop.hrbrmstr.dev/2024/08/02/drop-510-2024-08-02-sqlite-vector-search/
Ralf HEROLD boosted:

📦 [A package a day - Database 1]
Today's Database package is nodbi
NoSQL Database Connector
🙏 Maintained by @rfhb
📝 https://docs.ropensci.org/nodbi/
Do you use this package? Tell us about it!
🗺️ https://discuss.ropensci.org/c/usecases/10
Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst