How to print multiline file content starting from start_pattern and ending at end_pattern? #commandline #textprocessing
#Textprocessing
remove commas in double quotes #commandline #bash #textprocessing #sed #awk
Von Dateiinhalten anzeigen über präzises Suchen bis zum Vergleichen: Diese Linux-Befehle sind unverzichtbar für die tägliche Administration und die LPIC-1-Prüfung.
https://itdocs.wiki/lpic-1-serie/lpic-1-dateiinhalte-anzeigen-und-bearbeiten.shtml
#LPIC1 #LinuxCommands #TextProcessing #FileManagement #FindCommand #DiffCommand
Building on the 90s, statistical n-gram language models, trained on vast text collections, became the backbone of NLP research. They fueled advancements in nearly all NLP techniques of the era, laying the groundwork for today's AI.
F. Jelinek (1997), Statistical Methods for Speech Recognition, MIT Press, Cambridge, MA
#NLP #LanguageModels #HistoryOfAI #TextProcessing #AI #historyofscience #ISE2025 @fizise @fiz_karlsruhe @tabea @enorouzi @sourisnumerique

#TIL you can pass variables to an #awk script with the option -v. This is useful, for example, when you want to include the file name in the output:
```
find . -type f -iname '*.csv' -exec awk -F, -v filename={} '{print filename, $2}' {} \;
```
Even though seemingly awkward at first glance, #awk is definitely one of the most versatile and useful tools on #linux.
🚀 Behold the epic tale of Janet's #PEG #module, where the author heroically excludes regular expressions like they're yesterday's news. 💥 Marvel at the labyrinth of #parsing magic that claims to be more readable, but only if you have a PhD in arcane text processing. 📜✨
https://bakpakin.com/writing/how-janets-peg-works.html #Janet #readability #textprocessing #regex #HackerNews #ngated
Once again, keyword matching to the rescue…
🔠 Panel: More than Chatbots: Multimodal Large Language Models in Humanities Workflows
At #DHd2025, Nina Rastinger explores how well #AI handles abbreviations & NER:
✅ NER works well, even with small, low-cost models
❌ Abbreviations are tricky—costs & resource demands skyrocket
🚀 GPT o1 improves performance, even on abbreviations, but remains resource-intensive
Balancing accuracy & efficiency in text processing remains a challenge! ⚖️

Master regular expressions for efficient substring extraction in Python! Learn greedy vs. non-greedy matching & capturing groups for precise results. #Regex #Python #StringExtraction #Tutorial #Programming #TextProcessing
https://tech-champion.com/data-science/regex-string-extraction-in-python-mastering-regular-expressions-for-substring-search
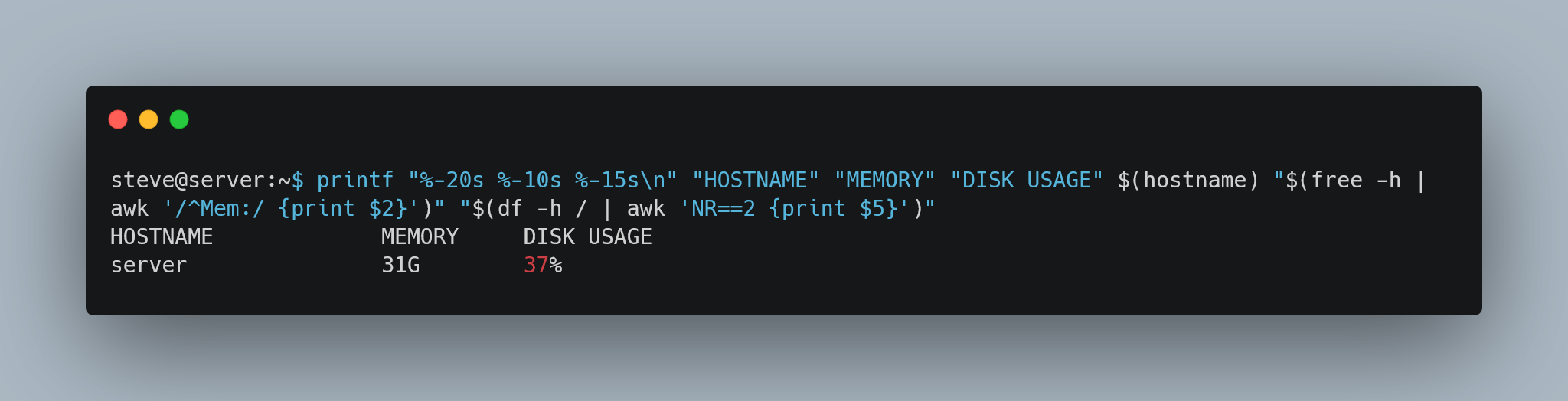
🐧 Struggling with text formatting in Linux? You're not alone! My new article breaks down the essentials for beginners.
Read more at https://www.spsanderson.com/steveondata/posts/2025-01-24/ and let’s discuss!
#Programming #linux #tech #printf #nl #fold #groff #TextProcessing #Formatting #Blog #CLI #CommandLineTips
🐧 Struggling with text formatting in Linux? You're not alone! My new article breaks down the essentials for beginners.
Read more at https://www.spsanderson.com/steveondata/posts/2025-01-24/ and let’s discuss!
#Programming #linux #tech #printf #nl #fold #groff #TextProcessing #Formatting #Blog #CLI #CommandLineTips
New at PragProg
Staffan Nöteberg helps you really understand how the machinery works under the hood. Learn advanced tools like reluctant, lookbehind and nondeterministic finite automata to write efficient and elegant regexes with ease.
In this illustrated guide, you gain precisely that understanding., even with no prior knowledge of Regular Expressions.
http://pragprog.com/titles/d-snrem
#regularexpressions #patternmatching #regex #regexp #textprocessing

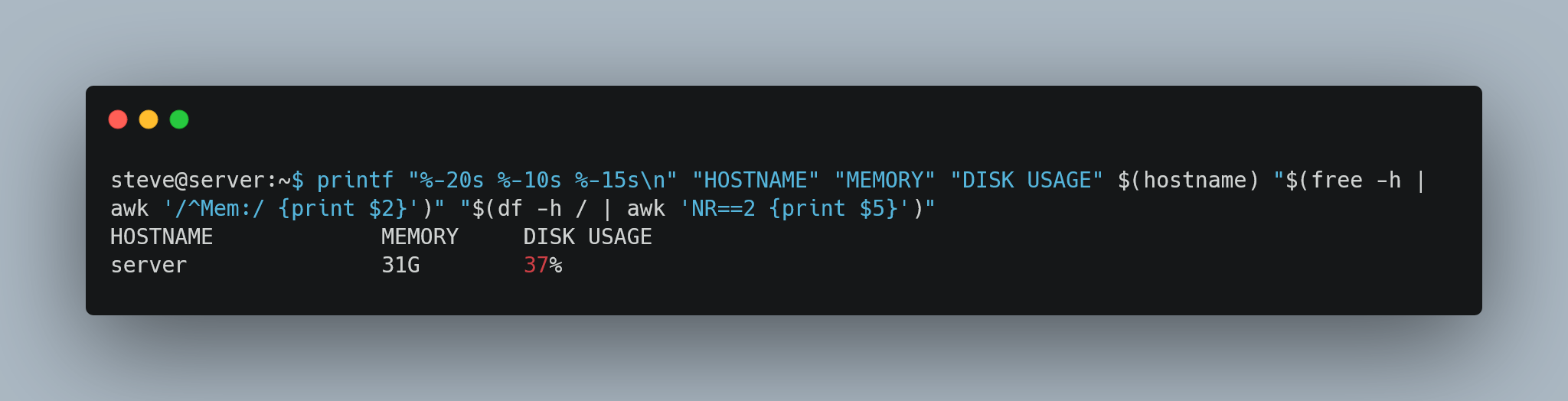
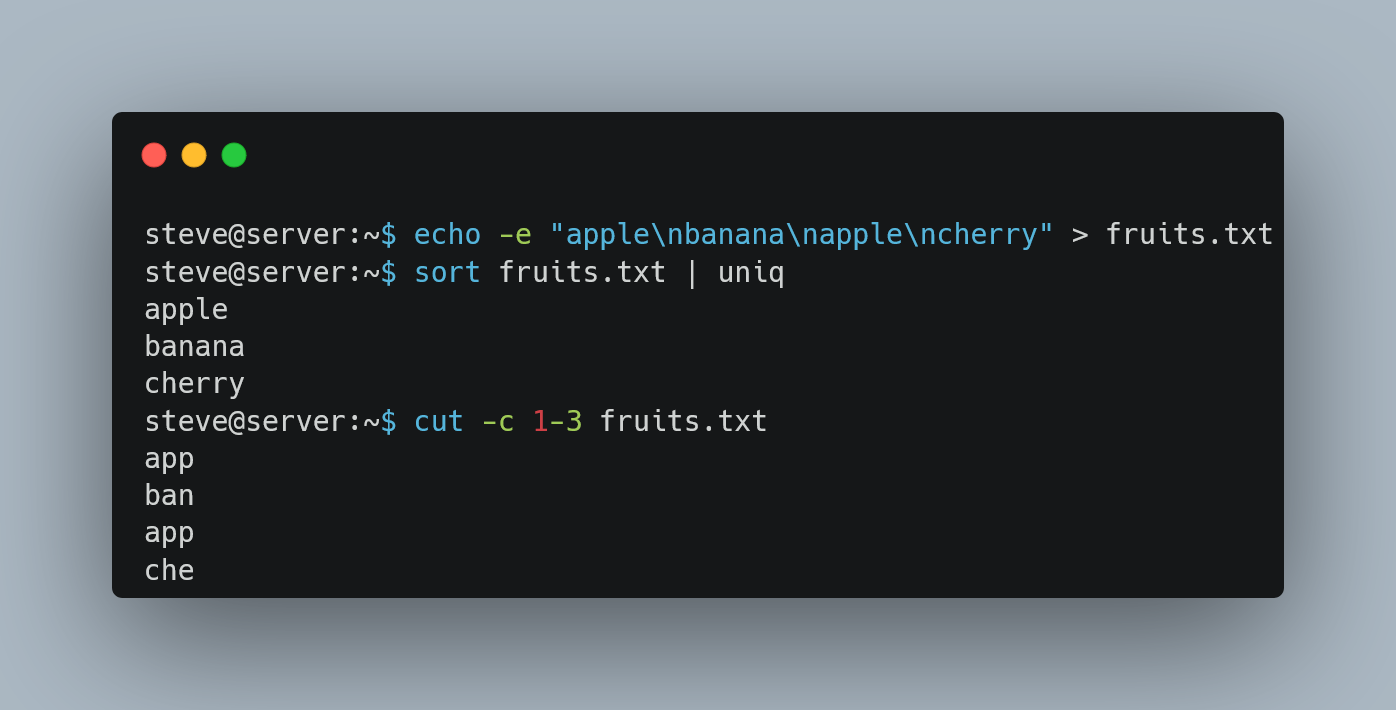
💡 Struggling with text processing in Linux?
My latest blog post at https://www.spsanderson.com/steveondata/posts/2025-01-17/ breaks down common challenges and offers practical solutions! Learn how to tackle duplicates and sort data with ease. 📊🔍
#Text #Blog #Technology #Textprocessing #Programming #Linux #Help
Let me know what you think!
💡 Struggling with text processing in Linux?
My latest blog post at https://www.spsanderson.com/steveondata/posts/2025-01-17/ breaks down common challenges and offers practical solutions! Learn how to tackle duplicates and sort data with ease. 📊🔍
#Text #Blog #Technology #Textprocessing #Programming #Linux #Help
Let me know what you think!
Back when I first wrote text processing code in the 90s on my Amiga 1200, I always used the ¤ symbol as a placeholder character for splitting and replacing to exclude things I wanted skipped without affecting character count. It was available on the Norwegian keyboard, and practically never used in text.
Recently I discovered that Unicode has two "Not a character" symbols perfect for the same usage: \uFFFE and \uFFFF.
They can be really useful!
2. Immediately after the split, replace U+FFFF with newline, but keep both versions of the line, and pass the one with the U+FFFF to the text paragraph parser. Everything else (like headings) gets the cleaned one.
3. After paragraph lines with a single break between them (belonging to the same paragraph) have been processed, THEN I replace the U+FFFF characters there.
It seems to work, but it took me like 3-4 hours to crack. 😅
4/4
I tried using the alternative line and paragraph separators from Unicode, but splitlines accepts them too. Then I discovered these Unicode characters:
U+FFFE <noncharacter-FFFE> not a character.
U+FFFF <noncharacter-FFFF> not a character.
The solution, then was:
1. Replace all occurrences of [br] with or without a trailing newline, using regex pattern "(?i)(?<!\\)(\[br\]\n?)", with a U+FFFF character.
3/4
This works fine in principle, but it is incredibly hard to figure out exactly when to make the replacement.
For instance, if I do it too early, the parser will split on the breaks as I use splitlines() early on. If I do it too late, I get double line breaks some places.
2/4
I've been struggling with solving an issue with my text editor project. The editor is plain text and uses a blank line to separate paragraphs.
The editor has an option to preserve or not preserve single line breaks inside paragraphs when generating the output.
However, some users want to not preserve them, but still want to be able to add hard breaks sometimes. So I've been trying out using [br] as a hard break shortcode.
1/4
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst