
I finally got around to testing BitBIRCH. TL;DR on a set of 1,000 molecules BitBIRCH did it in 2 Secs, while Butina took 11 Secs. #cheminformatics #python https://tlint101.github.io/practice-in-code/posts/18-Clustering%20wiht%20Bitbirch.html
#cheminformatics

the analysis includes the Journal of #Cheminformatics
https://mastodon.social/@hansonmark.bsky.social@bsky.brid.gy/115886840997900335

Consider the #cheminformatics fingerprints expressed in binary:
1111
0110
1000
1110
The pairwise Jaccard/Tanimoto scores contain no duplicates. The upper-triangular matrix is:
2/4,1/4,3/4
0/3,2/3
1/3
Is there a solution with *five* 4-bit fingerprints? (1/5)

a @wikipedia page about aromaticity in #cheminformatics: https://en.wikipedia.org/wiki/Aromaticity_(cheminformatics)
Anything missing?
Just submitted my paper to the Journal of #Cheminformatics.
*sigh*
Just noticed the J. #Cheminformatics table guidelines at https://link.springer.com/journal/13321/submission-guidelines#cms-Preparing-additional-files :
• Tables should not be embedded as figures or spreadsheet files, but should be formatted using ‘Table object’ function in your word processing program.
• Color and shading may not be used.
Guess who exported their spreadsheet as SVG so it preserved color used as shading, and could use text rotated 90 degrees.
@jerven okay, rough estimate of the number of owl:sameAs links now in the @wikipathways RDF (part of the release on the 10th):
- 1250+ owl:sameAs to SwissLipids
- 5000+ owl:sameAs to @lipidmaps.bsky.social
- 1600+ owl:sameAs to @rhea-db.bsky.social
- 77k+ owl:sameAs to UniProtKB
(powered by @wikidata via their SPARQL)
looking at @dalke's "Superimposed Coding of Count Fingerprints to Binary Fingerprints" https://doi.org/10.26434/chemrxiv-2026-j3hbj
"This paper proposes a novel method based on random superimposed coding to convert count fingerprints to binary fingerprints such that the binary Tanimoto similarity between two binary fingerprints better approximates the multiset Tanimoto similarity between their original count form."
ChemRXiv has accepted my #cheminformatics preprint "Superimposed Coding of Count Fingerprints to Binary Fingerprints". It is available at https://chemrxiv.org/engage/chemrxiv/article-details/69442a39e3cb457e13780fbd .

Euclid 2.14 is released: https://doi.org/10.5281/zenodo.17996224 https://github.com/BlueObelisk/euclid/releases/tag/euclid-2.14
Minor update with upgraded dependencies to Log4j 2.25.3 and Commons IO 2.21 and Lang3 3.20.
Euclid is a library of numeric, geometric and XML routines.
I just submitted a #cheminformatics preprint to ChemRxiv, based on the #RDKit count fingerprints, #chemfp, and some one-off R&D code I wrote over the last few months.
"Superimposed Coding of Count Fingerprints to Binary Fingerprints"
In short, my superimposed coding method gives k-recall@k nearest neighbor scores ~0.9 relative to using full count fingerprints and the multiset Tanimoto (aka MinMax, aka Ruzicka similarity). Recall can be over 0.95 w/ 8192 bits!
#OpenBabel is dead, long live #RDKit!
https://github.com/RMeli/spyrmsd/issues/149
On a more serius note, it would be cool to have a cheminformatics library that actually works. Don't get me wrong, RDKit is very cool - but you can feel all the underlying problems it has when using it.
If you've money left in your #cheminformatics, #chemfp makes a nice Christmas present. :)

💐👏 Congratulations to Sabrina Jaeger-Honz from our Project D04! She won the Airbus Research Award "Claude Dornier" for her #dissertation "Combining Bio- and Cheminformatics for Small Data Sets: Microcystins as a Use Case".
💡 Using computational methods, Sabrina's thesis presents multiple interconnected approaches in order to overcome difficulties associated with studying small datasets in bio- and #cheminformatics.
➡️ https://www.sfbtrr161.de/news/Airbus-Forschungspreis-Claude-Dornier-for-Sabrina-Jaeger-Honz/


🤖 What happens when we let a Transformer model, not a docking engine, judge protein–ligand affinity?
🔗 DrugForm-DTA: Towards real-world drug-target binding affinity model. Computational and Structural Biotechnology Journal, DOI: https://doi.org/10.1016/j.csbj.2025.09.023
📚 CSBJ: https://www.csbj.org/
#DrugDevelopment #DrugDiscovery #Cheminformatics #StructuralBiology #ChemicalBiology #DrugTargetAffinity #QSAR

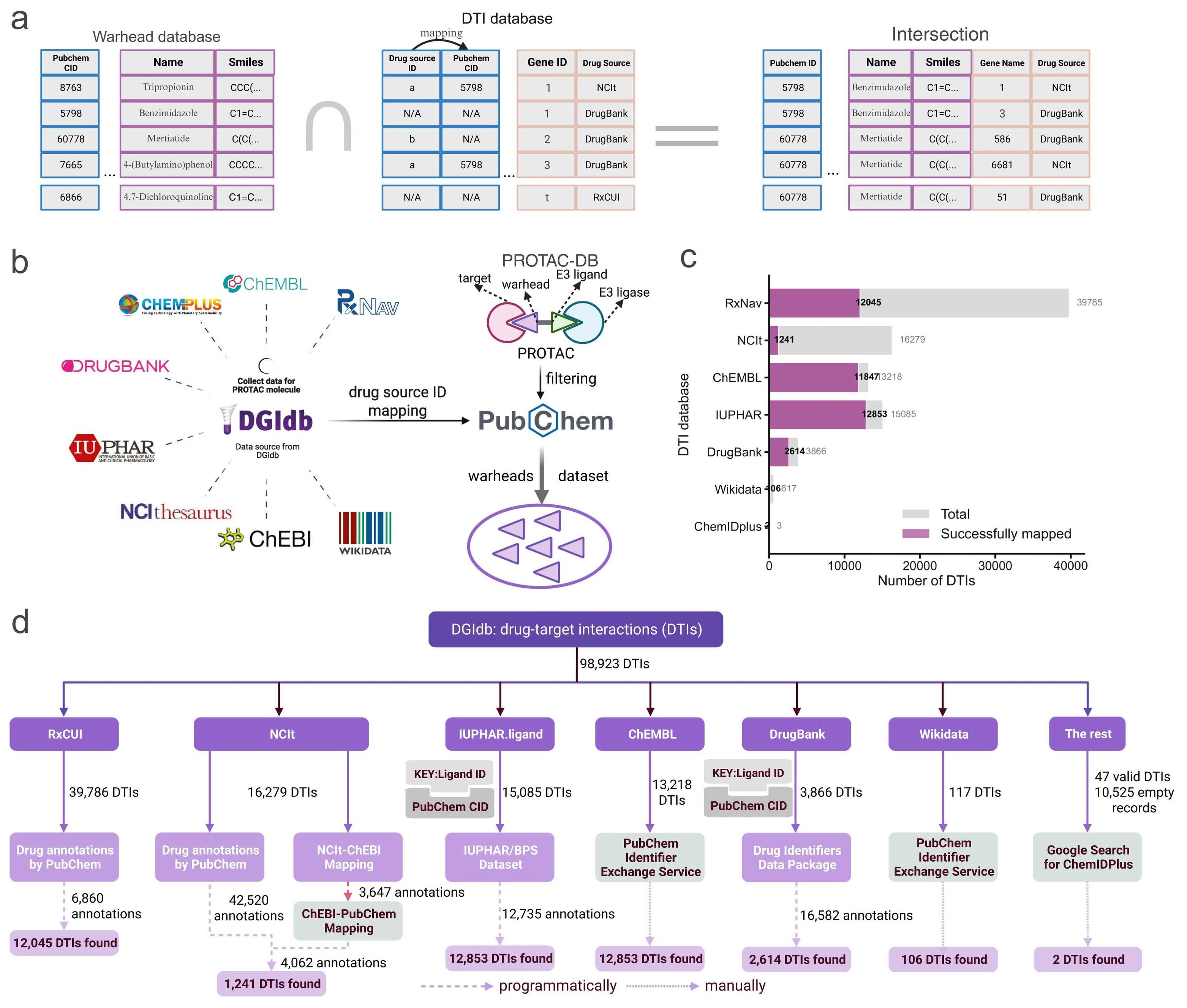
🤖 Can AI help us predict and prevent off-target effects in PROTAC drug design?
🔗 Predicting PROTAC off-target effects via warhead involvement levels in drug–target interactions using graph attention neural networks. Computational and Structural Biotechnology Journal, DOI: https://doi.org/10.1016/j.csbj.2025.10.028
📚 CSBJ: https://www.csbj.org/
#DrugDevelopment #StructuralBiology #ChemicalBiology #PROTAC #DrugDiscovery #Cheminformatics #Bioinformatics #PrecisionMedicine #TargetedProteinDegradation
new blog: "WikiPathways curation reports on profile pages" https://doi.org/10.59350/s7vw2-r7y02 https://chem-bla-ics.linkedchemistry.info/2025/11/30/wikipathways-curation-reports-on-profile-pages.html
Replies to this post show up as comments in the blog post.


The submission deadline for the ICCS Collection in the Journal of Cheminformatics will be extended to March 1. We currently have four papers under review and expect at 2 more submissions.

Yesterday, we were very happy to host the November meeting of the InChI developer team at the Beilstein-Institut. Many thanks to the Aachen side of the InChI team for coming to Frankfurt!
Find out more about our #BeilsteinCheminfoLabs projects where we are supporting InChI and other open source projects ➡️ https://www.beilstein-institut.de/en/projects/cheminfo-labs/inchi/?M=y

💊 Why do some medications unexpectedly harm the kidneys — and can single-cell data uncover the reason?
🔗 Cell-type specific single-cell signatures reveal nephrotoxic drug effects. Computational and Structural Biotechnology Journal, DOI: https://doi.org/10.1016/j.csbj.2025.11.012
📚 CSBJ: https://www.csbj.org/
#Nephrotoxicity #CellBiology #Cheminformatics #AcuteKidneyInjury #DrugDiscovery #SingleCellGenomics #DrugDevelopment #CellAtlas

Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst