Here's an ~ official ~ release announcement for #numpydantic
repo: https://github.com/p2p-ld/numpydantic
docs: https://numpydantic.readthedocs.io
Problems: @pydantic is great for modeling data!! but at the moment it doesn't support array data out of the box. Often array shape and dtype are as important as whether something is an array at all, but there isn't a good way to specify and validate that with the Python type system. Many data formats and standards couple their implementation very tightly with their schema, making them less flexible, less interoperable, and more difficult to maintain than they could be. The existing tools for parameterized array types like nptyping and jaxtyping tie their annotations to a specific array library, rather than allowing array specifications that can be abstract across implementations.
numpydantic is a super small, few-dep, and well-tested package that provides generic array annotations for pydantic models. Specify an array along with its shape and dtype and then use that model with any array library you'd like! Extending support for new array libraries is just subclassing - no PRs or monkeypatching needed. The type has some magic under the hood that uses pydantic validators to give a uniform array interface to things that don't usually behave like arrays - pass a path to a video file, that's an array. pass a path to an HDF5 file and a nested array within it, that's an array. We take advantage of the rest of pydantic's features too, including generating rich JSON schema and smart array dumping.
This is a standalone part of my work with @linkml arrays and rearchitecting neurobio data formats like NWB to be dead simple to use and extend, integrating with the tools you already use and across the experimental process - specify your data in a simple yaml format, and get back high quality data modeling code that is standards-compliant out of the box and can be used with arbitrary backends. One step towards the wild exuberance of FAIR data that is just as comfortable in the scattered scripts of real experimental work as it is in carefully curated archives and high performance computing clusters. Longer term I'm trying to abstract away data store implementations to bring content-addressed p2p data stores right into the python interpreter as simply as if something was born in local memory.
plenty of todos, but hope ya like it.
#linkml #python #NewWork #pydantic #ScientificSoftware

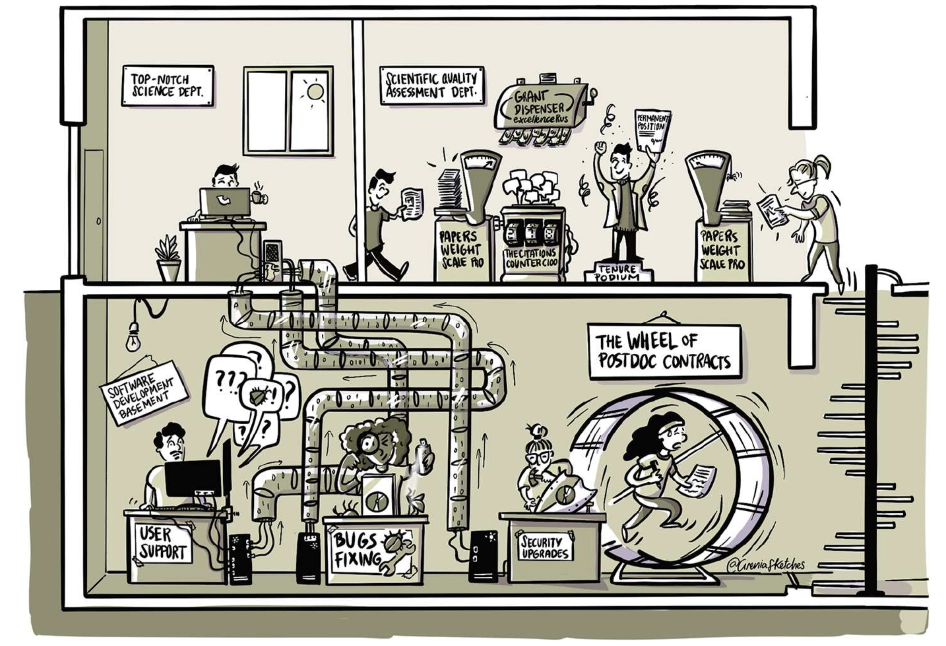
![[This and the following images aren't very screen reader friendly with a lot of code in them. I'll describe what's going on in brackets and then put the text below.
In this image: a demonstration of the basic usage of numpydantic, declaring an "array" field on a pydantic model with an NDArray class with a shape and dtype specification. The model can then be used with a number of different array libraries and data formats, including validation.]
Numpydantic allows you to do this:
from pydantic import BaseModel
from numpydantic import NDArray, Shape
class MyModel(BaseModel):
array: NDArray[Shape["3 x, 4 y, * z"], int]
And use it with your favorite array library:
import numpy as np
import dask.array as da
import zarr
# numpy
model = MyModel(array=np.zeros((3, 4, 5), dtype=int))
# dask
model = MyModel(array=da.zeros((3, 4, 5), dtype=int))
# hdf5 datasets
model = MyModel(array=('data.h5', '/nested/dataset'))
# zarr arrays
model = MyModel(array=zarr.zeros((3,4,5), dtype=int))
model = MyModel(array='data.zarr')
model = MyModel(array=('data.zarr', '/nested/dataset'))
# video files
model = MyModel(array="data.mp4")](https://files.mastodon.social/cache/media_attachments/files/112/499/382/097/815/294/original/b47efacd3a8e56de.png)
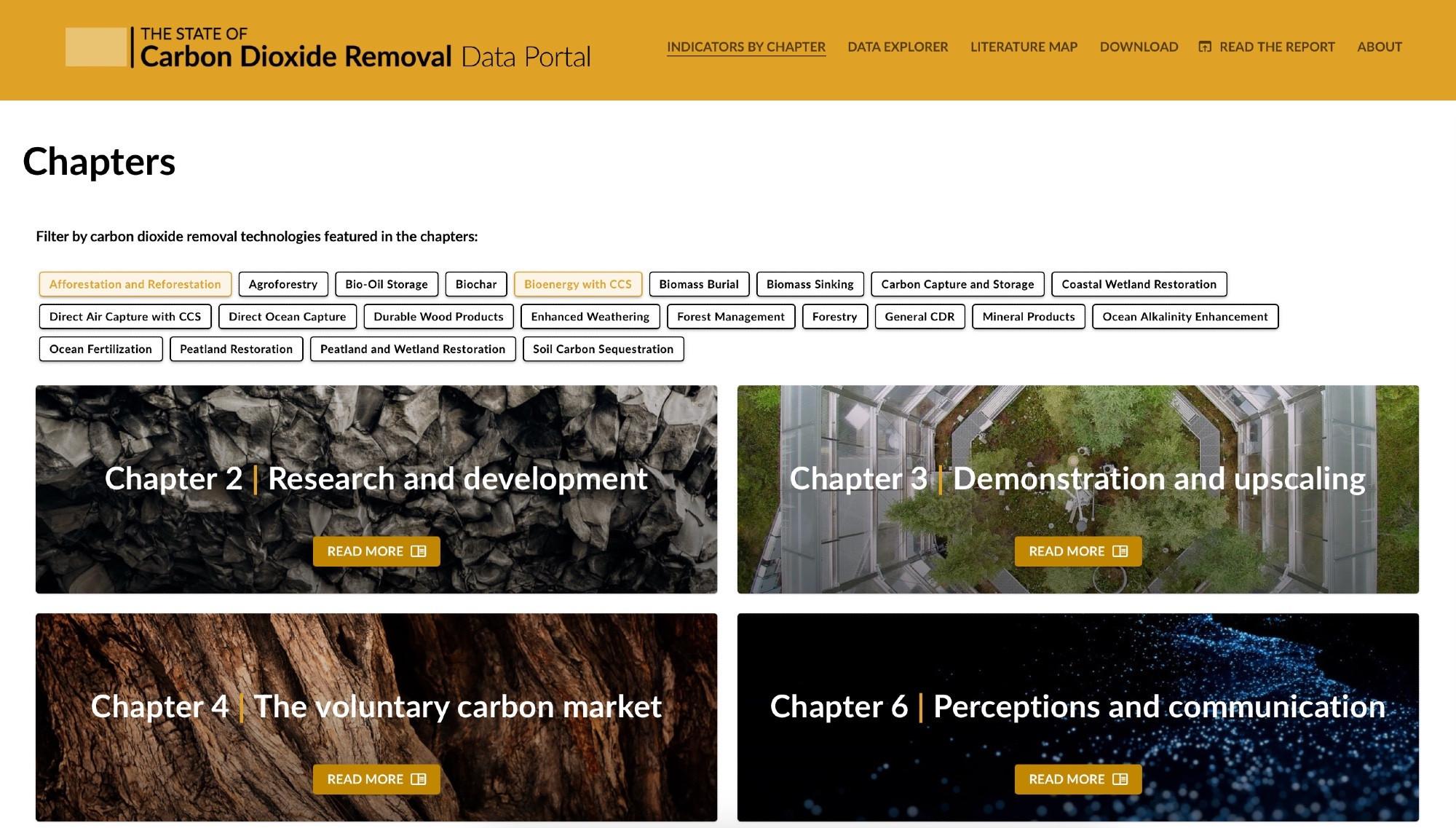
![[Further demonstration of validation and array expression, where a Union of NDArray specifications can specify a more complex data type - eg. an image that can be any shape in x and y, an RGB image, or a specific resolution of a video, each with independently checked dtypes]
For example, to specify a very special type of image that can either be
a 2D float array where the axes can be any size, or
a 3D uint8 array where the third axis must be size 3
a 1080p video
from typing import Union
from pydantic import BaseModel
import numpy as np
from numpydantic import NDArray, Shape
class Image(BaseModel):
array: Union[
NDArray[Shape["* x, * y"], float],
NDArray[Shape["* x, * y, 3 rgb"], np.uint8],
NDArray[Shape["* t, 1080 y, 1920 x, 3 rgb"], np.uint8]
]
And then use that as a transparent interface to your favorite array library!
Interfaces
Numpy
The Coca-Cola of array libraries
import numpy as np
# works
frame_gray = Image(array=np.ones((1280, 720), dtype=float))
frame_rgb = Image(array=np.ones((1280, 720, 3), dtype=np.uint8))
# fails
wrong_n_dimensions = Image(array=np.ones((1280,), dtype=float))
wrong_shape = Image(array=np.ones((1280,720,10), dtype=np.uint8))
# shapes and types are checked together, so this also fails
wrong_shape_dtype_combo = Image(array=np.ones((1280, 720, 3), dtype=float))](https://files.mastodon.social/cache/media_attachments/files/112/499/382/190/097/393/original/7186355a4d480606.png)
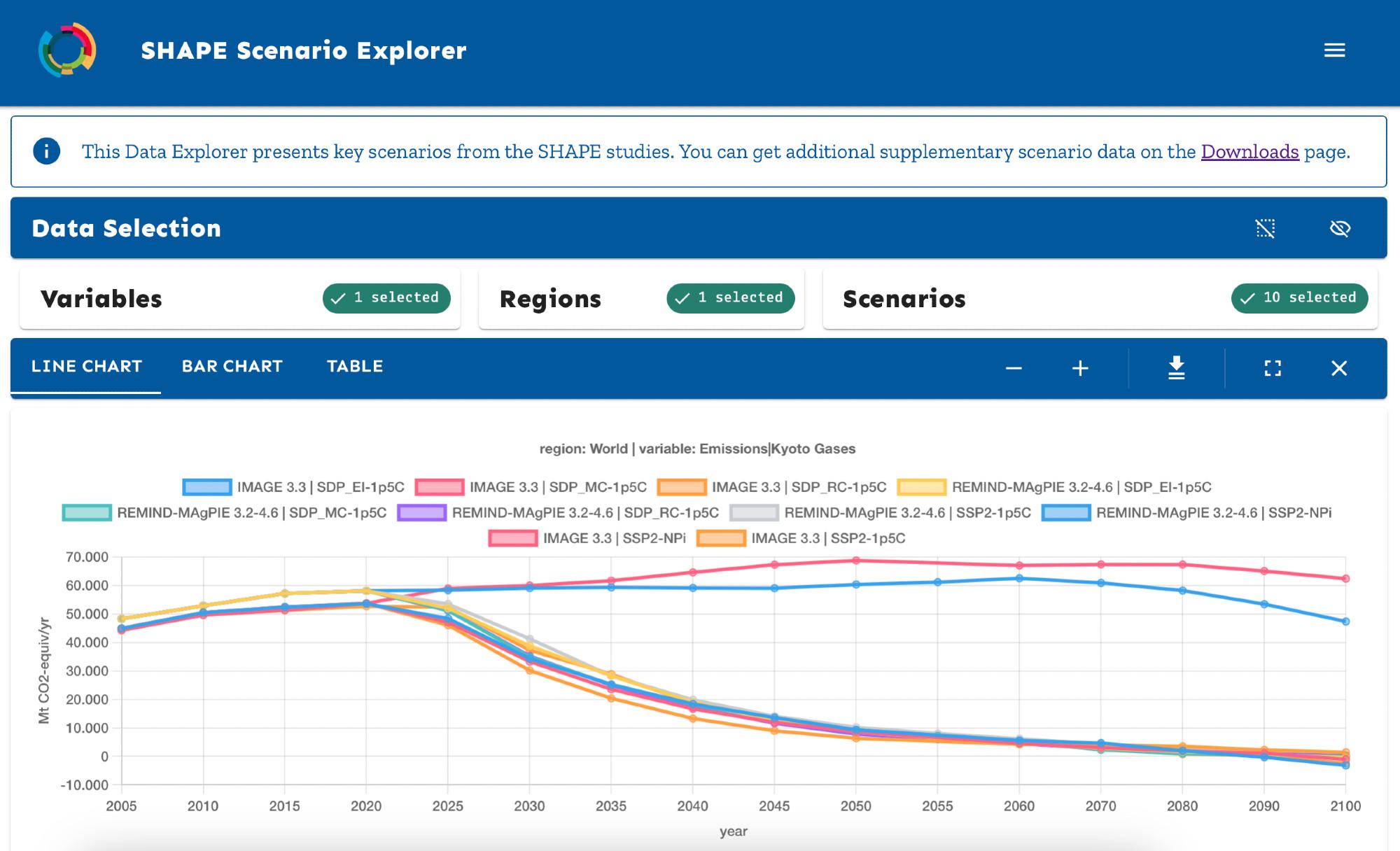
![[Demonstration of usage outside of pydantic as just a normal python type - you can validate an array against a specification by checking it the array is an instance of the array specification type]
And use the NDArray type annotation like a regular type outside of pydantic – eg. to validate an array anywhere, use isinstance:
array_type = NDArray[Shape["1, 2, 3"], int]
isinstance(np.zeros((1,2,3), dtype=int), array_type)
# True
isinstance(zarr.zeros((1,2,3), dtype=int), array_type)
# True
isinstance(np.zeros((4,5,6), dtype=int), array_type)
# False
isinstance(np.zeros((1,2,3), dtype=float), array_type)
# False](https://files.mastodon.social/cache/media_attachments/files/112/499/382/292/594/245/original/c6377435b995a0b4.png)
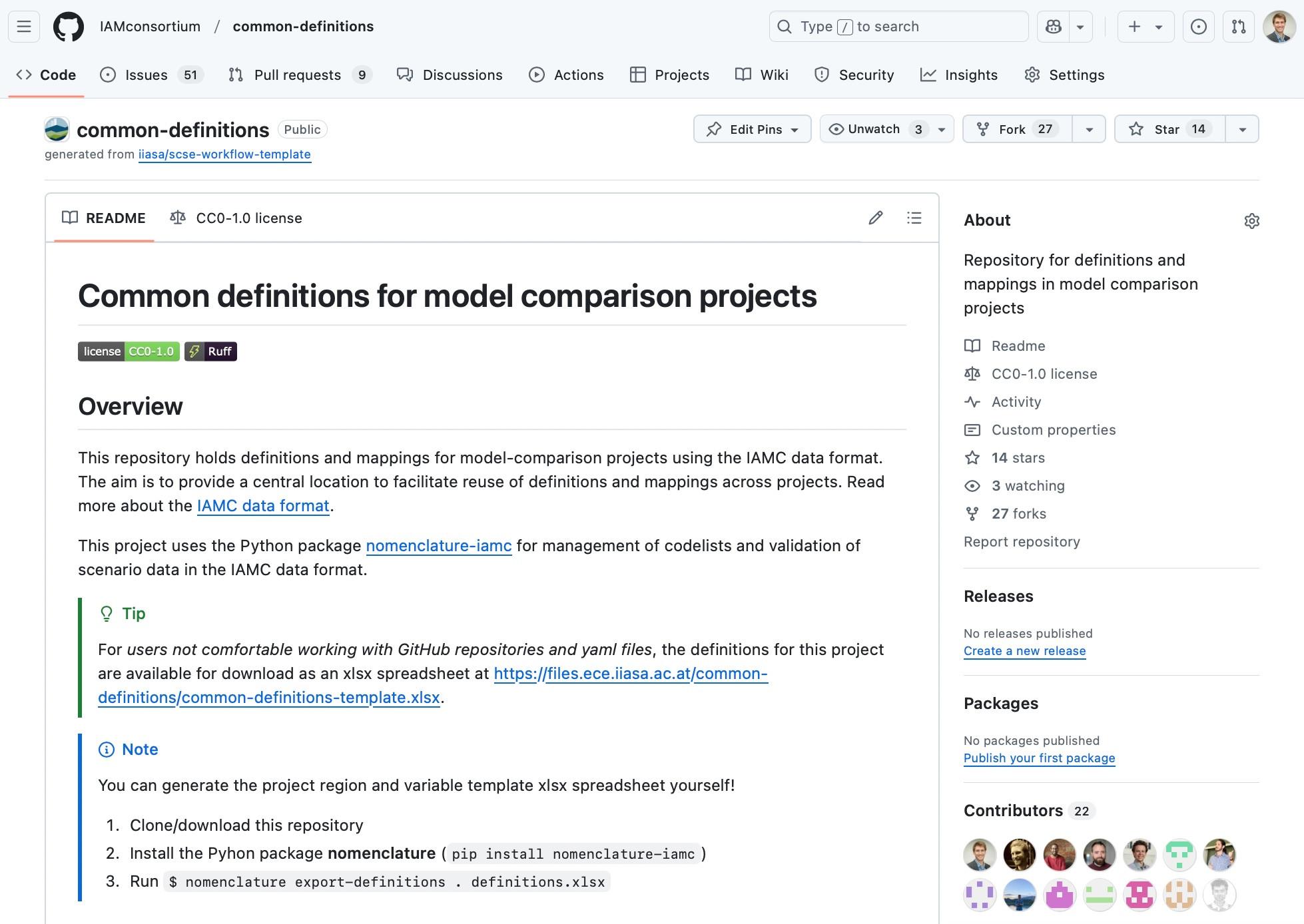
![[Demonstration of JSON schema generation using the sort of odd case of an array with a specific dtype but an arbitrary shape. It has to use a recursive JSON schema definition, where the items of a given JSON array can either be the innermost dtype or another instance of that same array. Since JSON Schema doesn't support extended dtypes like 8-bit integers, we encode that information as maximum and minimum constraints on the `integer` class and add it in the schema metadata. Since pydantic renders all recursive schemas like this in the same $defs block, we use a blake2b hash against the dtype specification to keep them deduplicated.]
numpydantic can even handle shapes with unbounded numbers of dimensions by using recursive JSON schema!!!
So the any-shaped array (using nptyping’s ellipsis notation):
class AnyShape(BaseModel):
array: NDArray[Shape["*, ..."], np.uint8]
is rendered to JSON-Schema like this:
{
"$defs": {
"any-shape-array-9b5d89838a990d79": {
"anyOf": [
{
"items": {
"$ref": "#/$defs/any-shape-array-9b5d89838a990d79"
},
"type": "array"
},
{"maximum": 255, "minimum": 0, "type": "integer"}
]
}
},
"properties": {
"array": {
"dtype": "numpy.uint8",
"items": {"$ref": "#/$defs/any-shape-array-9b5d89838a990d79"},
"title": "Array",
"type": "array"
}
},
"required": ["array"],
"title": "AnyShape",
"type": "object"
}](https://files.mastodon.social/cache/media_attachments/files/112/499/382/411/490/065/original/6f8183a70263557d.png)