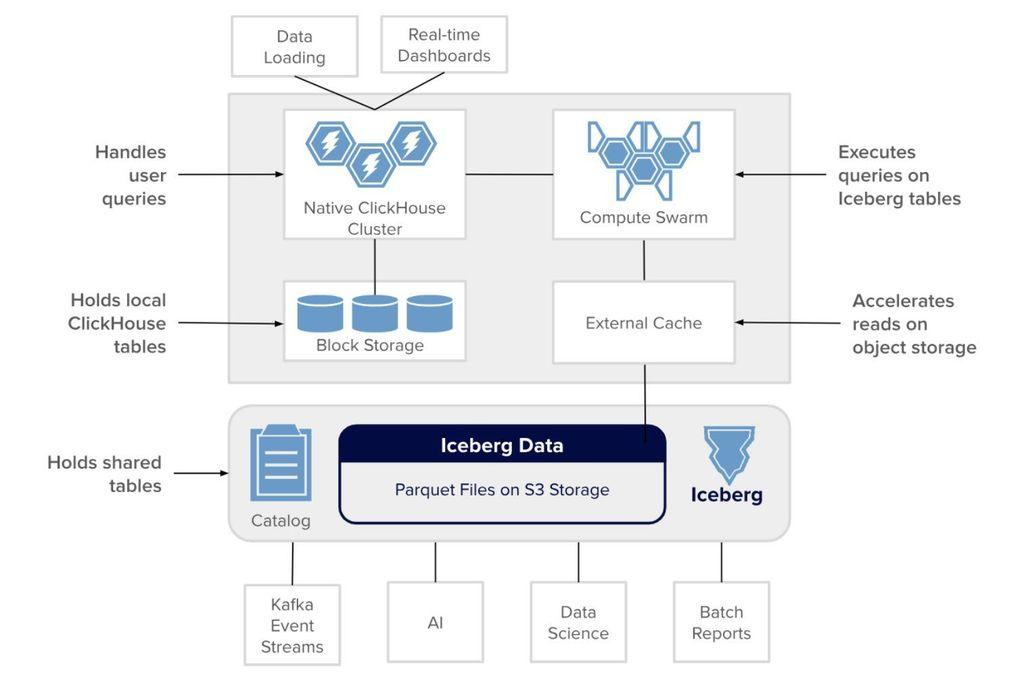
This week's "fun" project: getting #Clickhouse running on #kubernetes at home, with data sharding and redundancy.
I've had a few speedbumps, including dirt in the optics on a redundant network link and an amazingly dumb MTU problem, but it seems to be working finally. I'm now doing a bit of testing to better understand how self-hosted Clickhouse does clusters.
It looks like *if you use their cloud product*, then data sharding and replication Just Works, but if you set up a cluster yourself then you need to declare everything up front when creating tables. So instead of creating a single table via `create table foo (...) ENGINE = MergeTree`, you need to do `create table foo_shard on cluster X (...) ENGINE = ReplicatedMergeTree(...)` in order to create replicated sub-tables per shard, and then add `create table foo on cluster X as foo_shard ENGINE=Distributed(...)` over the top of the per-instance ReplicatedMergeTree shards.
It's (mostly?) just a DDL thing, so querying seems to work as expected, but it's *strange* to create a cluster with a defined shard size and replication level, and then have to repeat yourself per-table in order to use them as declared.
Even better, this all "works" if you declare the per-shard tables as `MergeTree` instead of `ReplicatedMergeTree`, except your data isn't replicated. I watched the disk usage climb on 1/3rd of my nodes while the other 2/3rds sat idle, and had to go back and re-read docs. That's *particularly* surprising, as it could easily lead to data loss.
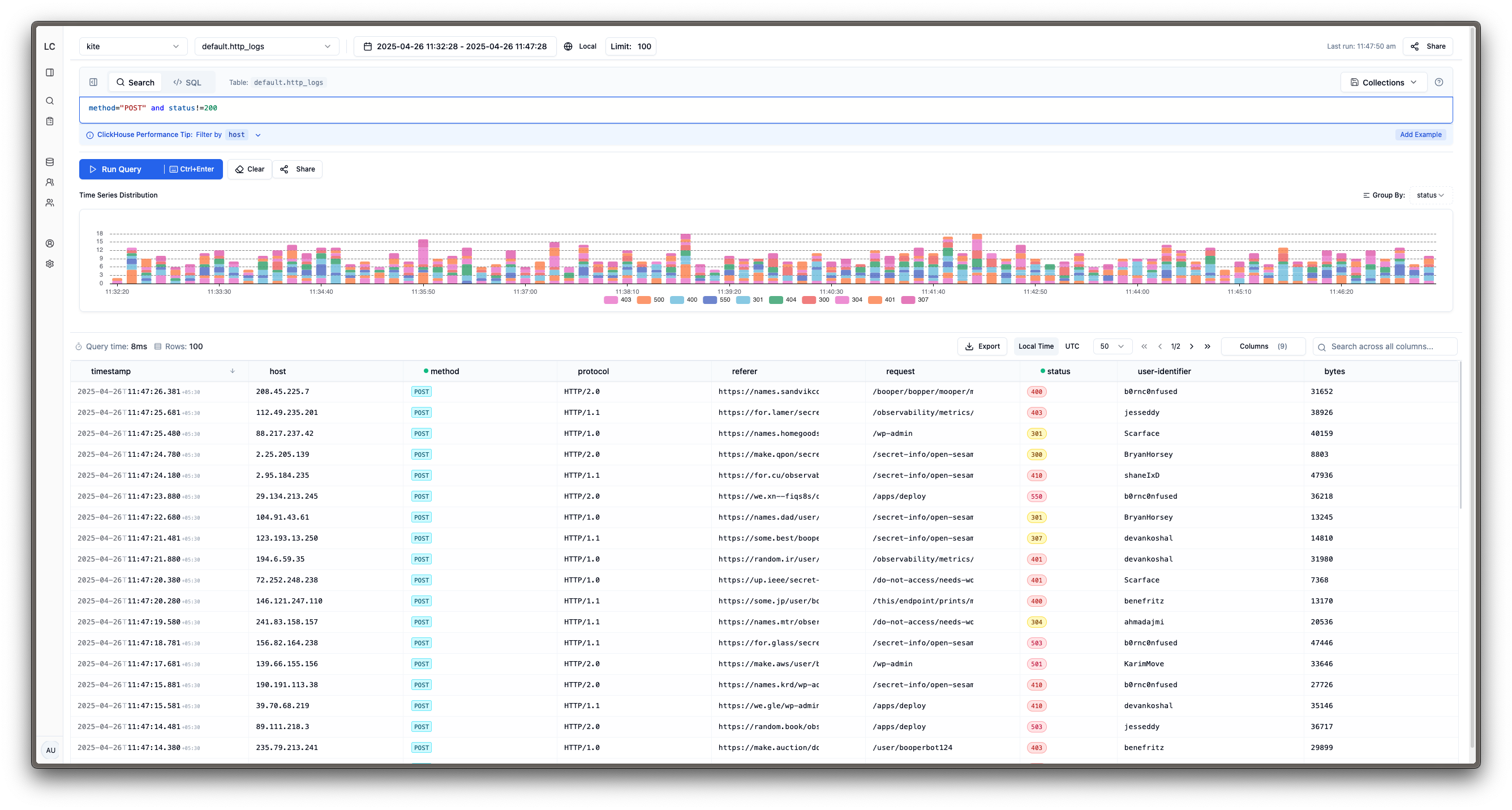
I'm doing yet another test copy of 1.2B rows of log data (!) right now, and then I'll start looking at what I need to do to cut over.
Also, I'll probably need to do some querying to see why I have 1.2B rows of log data and where it came from. That seems excessive for a couple weeks of logging at home.