What are we (NRENs deploying SAML) gonna do about libxml2? It is now sort of unmaintained and reading the announcement for it, I can totally understand why the maintainer wants to step away.
#xml
@nickbearded I am trying to stay on execution front and iterate but have to get v basics done first. let's talk more about this - having it run over tor or ip2 may be a nice option. the thought of having ability to shortcut to specific scripts through bash is good osint due diligence; the harnessing collective intelligence part is really the cornerstone #tags #semantic search #tagcloud #distributed decentralized federations #devops #bashcore scripting #xml #xslt #pagerank algo

XML Fragment Interchange
https://www.w3.org/TR/2001/CR-xml-fragment-20010212
うげー、 CR で止まったまま終わったのか
XML documents are much like humans they are cute and fun to deal with when they're small but can get really annoying as they grow bigger.
— Andy Hunt
如何优雅地升级ruby标签:正则表达式指南
在支持HTML的环境(包括不少现代的Markdown编辑器1)使用<ruby>标签为汉字等表意文字添加注音(如拼音或振假名),是一个非常实用的功能。然而,一个常见的痛点是,在不支持该标签的纯文本渲染环境下,内容的可读性会大大降低。
例如,一个标准的<ruby>标签:
<ruby>大学<rt>だいがく</rt></ruby>在纯文本的渲染环境中会显示为大学だいがく,这显然不够理想。2
优雅降级的方案:<rp>标签
HTML标准为此提供了一个优雅的解决方案:<rp>(ruby parenthesis)标签。它的作用是包裹“备用字符”(通常是括号),这些字符只在不支持<ruby>的环境中显示。
理想的格式应该是这样:
<ruby>大学<rp>(</rp><rt>だいがく</rt><rp>)</rp></ruby>这样可以实现两全其美的效果:
- 在支持的环境3:正常显示注音样式,括号被隐藏。
- 在不支持的环境(纯文本):显示为
大学(だいがく),未尝有损可读性。
那么,如何将手上的文字(譬如说电子笔记库)中所有旧格式的<ruby>标签批量升级到这种新格式呢?自然会想到的是全局搜索与正则表达式。
第一版方案:简单替换
(警告:请不要急着一行行跟着以下方案批量替换,建议先看看下文再做决定。另外,任何时候都请记得做好备份,再批量修改。)
这里用可以直接管理包括.markdown文件在内的笔记文档的VS Code来举例。我们最直接的想法是找到所有的注音标签,然后给它们加上括号。
- 查找:
<rt>(.*?)<\/rt> - 替换:
<rp>(</rp><rt>$1</rt><rp>)</rp>
这个方案可以处理最简单的情况。但很快我们就会发现第一个问题。
边界情况:一个词组内的多个注音
当遇到像日语“地震”这样的词,其源代码可能是:
<ruby>地<rt>じ</rt>震<rt>しん</rt></ruby>上面的简单方案能正确工作吗?是的。它会独立地将<rt>じ</rt>替换为<rp>(</rp><rt>じ</rt><rp>)</rp>,并将<rt>しん</rt>替换为<rp>(</rp><rt>しん</rt><rp>)</rp>,最终得到正确的结果:
<ruby>地<rp>(</rp><rt>じ</rt><rp>)</rp>震<rp>(</rp><rt>しん</rt><rp>)</rp></ruby>到目前为止,一切似乎都很顺利。但一个更隐蔽的“定时炸弹”埋藏在这个方案中。
第二版方案:解决重复执行的bug
问题在于,如果我们不小心再次运行4这个替换脚本,会发生什么?
它会找到已经修复好的<rp>(</rp><rt>じ</rt><rp>)</rp>中的<rt>じ</rt>,然后再次为它套上括号,导致灾难性的结果:
<rp>(</rp><rp>(</rp><rt>じ</rt><rp>)</rp><rp>)</rp>这破坏了幂等性5原则。一个健壮的脚本必须能够安全地重复执行而不产生副作用。
因此,我们需要一个最终的、更智能的查找逻辑:只查找那些尚未被<rp>(</rp>和<rp>)</rp>包裹的<rt>标签。
终极解决方案:使用反向否定查找
正则表达式的“反向否定查找”(negative lookbehind),写作(?<!...),是解决这个问题的完美工具。它允许我们匹配一个模式,但前提是它的前面不是某个特定的字符串。
最终的查找与替换规则
- 打开VS Code的“在文件中查找和替换”面板 (
Ctrl+Shift+H或Cmd+Shift+H)。 - 确保启用正则表达式模式 (点击
.*图标)。 - 在“查找”(Find)输入框中,粘贴以下表达式:
(?<!<rp>\(<\/rp>)<rt>(.*?)<\/rt> - 在“替换”(Replace)输入框中,粘贴以下内容:
<rp>(</rp><rt>$1</rt><rp>)</rp>
工作原理解析
- 查找:
(?<!<rp>\(<\/rp>)<rt>(.*?)<\/rt>(?<!<rp>\(<\/rp>):这是关键。它是一个反向否定查找,意思是:“从当前位置往前看,前面的文本不能是<rp>(</rp>”。注意,为了匹配字面上的括号(,我们用\(对其进行了转义。<rt>(.*?)<\/rt>:这部分和之前一样,用于匹配<rt>标签及其内容。
这个查找表达式现在变得非常智能:
- 它能匹配
<ruby>地<rt>じ</rt>...中的<rt>じ</rt>,因为它的前面是字符地,不是<rp>(</rp>。 - 它不能匹配
<ruby>地<rp>(</rp><rt>じ</rt>...中的<rt>じ</rt>,因为它前面的文本正好是我们排除了的<rp>(</rp>。
这样,无论对文件执行多少次这个替换操作,它都只会影响那些尚未被修复的旧标签,而对已经符合新格式的标签秋毫无犯,完美地保证了操作的安全性和幂等性6。
通过这个逐步优化的过程,我们最终得到了一个强大、安全且一劳永逸的解决方案,可以放心地用它来优化整个笔记库。
尾注
- 尽管
<ruby>标签并不是标准的Markdown语法——从“<”与“>”就能看出它的XML色彩,但是不少现代的Markdown编辑器——例如Obsidian之类——都会尽量支持HTML语法,<ruby>标签也就包含在内了。 ↩︎ 偏偏市面上大把网页都是这个样子,吾辈任重道远呐。↩︎- 大到现代浏览器,小到Obsidian之类支援HTML的笔记软件的预览界面。 ↩︎
- 甚至还有种情况,就是——虽然是头一回尝试批量执行,但是待执行的文档里面已经包含有写好了
<rp>的<ruby>标签了。 ↩︎ - 幂等性(idempotence)指的是在一次或多次执行相同操作后,系统的状态保持不变,即无论执行多少次,结果都是相同的。 ↩︎
- 对“幂等性”概念的解释参见前文。 ↩︎
Le format texte et le balisage léger, indispensables pour une production écrite souveraine et interopérable. À rebours des logiques courts termistes et commerciales.
🚀 Version 1.1.0 of selfphp/data-converter is out!
Now supports:
✅ Array ↔ JSON (with flexible flags like UNESCAPED_SLASHES)
✅ Array ↔ XML (with @attributes and #text)
Ideal for APIs, configs, and data exports.
💻 https://github.com/selfphp/data-converter
📦 https://packagist.org/packages/selfphp/data-converter
#php #opensource #json #xml #packagist
🚀 New on Packagist:
selfphp/data-converter – Convert arrays to XML and back.
No dependencies. Supports @attributes, #text, nested elements and clean structure.
Perfect for APIs, config files, or data transformation.
💻 https://github.com/selfphp/data-converter
📦 https://packagist.org/packages/selfphp/data-converter
#php #xml #opensource #packagist #selfphp
Yes, XML is still around and will be for a long time! Learn more about handling XML in the Oracle Database from Fabian Neureiter.
https://knowledgebase.hyand.com/q/xml_oracle #orclapex #plsql #xml

Les inscriptions sont ouvertes ! #Formation #Initiation à l’encodage #XML #TEI des textes patrimoniaux (imprimés & manuscrits). 27-28-29 oct. 2025
#CESR – Centre d’études supérieures de la Renaissance - Université de Tours
Avec le soutien de @biblissima et du consortium Ariane (#Huma-Num #CNRS)
++ Infos & candidatures : https://bvh.hypotheses.org/13433
! Notez que la formation s'adresse aux #débutants et AUSSI à ceux qui travaillent sur des textes modernes #TEIforEverythingAndEveryone #vivelaTEI

Нюансы работы с протоколом SAML 2.0
Привет, Хабр! На связи Дмитрий Грудинин. Современные корпоративные веб-приложения и облачные сервисы в обязательном порядке требуют безопасной аутентификации и авторизации пользователей. Как правило, для этого используются протоколы: SAML 2.0 или OpenID Connect (OIDC) на базе OAuth. Оба решают схожие задачи, связанные с делегированием ответственности за верификацию пользователя стороннему доверенному провайдеру. При этом оба протокола скрывают за собой обширный арсенал различных вариантов использования, к тому же OIDC постоянно расширяется. В данной статье мы рассмотрим сценарий использования протокола SAML так сказать «for dummies» . Идея статьи – без излишеств рассказать о том, что на самом деле нужно знать в SAML. И не рассказывать о том, без чего можно прекрасно обойтись.
https://habr.com/ru/companies/avanpost/articles/915566/
#saml_20 #avanpost #аутентификация_пользователей #service_provider #identity_provider #xml #base64 #saml
Poster 17/07:
"DoTS: FAIRly publishing your textual data with the #DTS API"
#SaxonJS 3.0.0-beta2 erschienen: https://www.saxonica.com/saxonjs/index.xml
SEF-Kompilation nun auch mit #SaxonEE 12.7 möglich. 👍
https://datenverdrahten.de/xslt3/saxon-js/funktionen3/
#Xml oder warum digitales scheitert
Was der Bauer nicht kennt, das frisst er nicht.
Was der Anwender nicht sieht, das misstraut er.
#xml Anhänge sind toll, damit kann toll automatisiert werden.
Wenn man weiß wie und wo.
Json geht auch..
Aber lieber in KI investieren die nur zu 99% genau Daten auslesen kann, immer neu trainiert werden kann und nicht nachhaltig ist.
SQL Workbench – Republicans not welcome
https://www.sql-workbench.eu/
#ycombinator #sql #query #tool #analyzer #gui #jdbc #database #isql #viewer #frontend #java #dbms #oracle #postgres #h2database #firebirdsql #hsql #hsqldb #sqlplus #replacement #import #export #csv #unload #convert #insert #blob #clob #xml #etl #migrate #compare #diff #structure #table
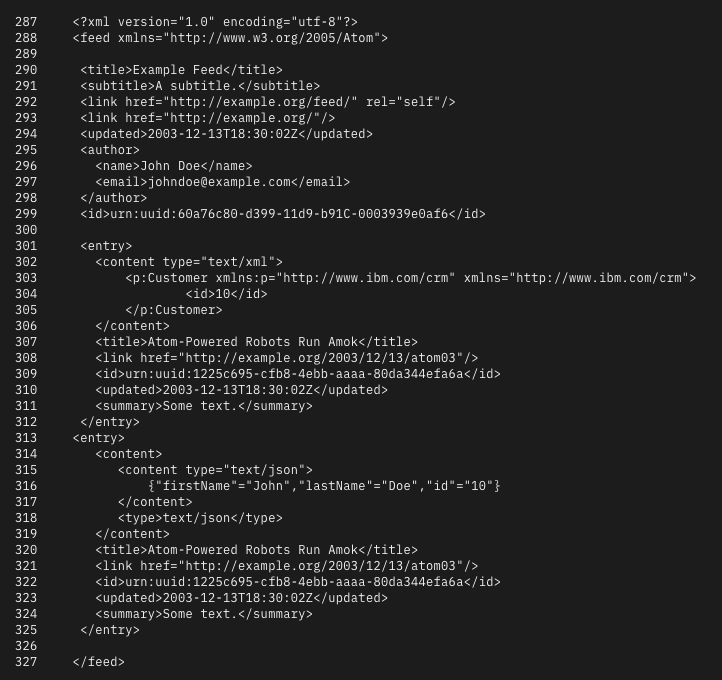
I'm researching for a rewrite of our OData tutorials in our SAP Developer Centre and came across this example of an Atom feed (you know the connection, right?). I cannot unsee the absolute randomness of indentation here, so I thought it only right that I share it here. #XML #Indentation #Atom #OData
Struggling with Odoo data import? Our guide to Odoo Create Records XML makes it simple! Learn step-by-step how to load complex data using XML files. Boost your Odoo skills today! #Odoo #XML #DataImport #OdooDevelopment #Tutorial
https://teguhteja.id/odoo-create-records-xml-a-comprehensive-tutorial/
Fascinating.
tmp $ wc -c < somefile.xopp
735772
tmp $ file somefile.xopp
somefile.xopp: gzip compressed data, from Unix, original size modulo 2^32 2086031
tmp $ gunzip < somefile.xopp |file -
/dev/stdin: XML 1.0 document, ASCII text, with very long lines (12483)
tmp $ gunzip < somefile.xopp |wc
937 204466 2086031
tmp $ gunzip < somefile.xopp |bzip2 -9 |wc -c
619543
tmp $ gunzip < somefile.xopp |bzip3 |wc -c
575115
tmp $ gunzip < somefile.xopp |xz -9e |wc -c
519764
tmp $ gunzip < somefile.xopp |grep -m1 "^.stroke" |cut -c 1-160
<stroke tool="pen" color="#3333ccff" width="2.26 0.72691752 0.73026261 0.73809079 0.74588449 0.74364294 0.72915908 0.71467521 0.71133013 0.70908858 0.7057435 0.
tmp $ gunzip < somefile.xopp |grep -oE "\<[0-9]+\.[0-9]+\>" |wc -l
201692
tmp $ echo "735772/201692" |bc -l
3.64799793744917993772
tmp $ echo "519764/201692" |bc -l
2.57701842413184459472
tmp $ echo "2086031/201692" |bc -l
10.34265612914741288697
tmp $
#Compression #XML #Xournal #Xournalpp #Xournal++
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst