#lockfree #hazardpointers can be make #waitfree
https://threadnought.wordpress.com/2025/05/26/wait-free-hazard-pointers-using-std-atomics/
There's about 3 or so ways of doing it, one of which has been published already. Seems to run about 50% faster in the async memory barrier version, about .7 nsecs vs 1.0 nsecs. Probably due to not having a conditional branch. No plans to implement it myself.
#LockFree
Next #swad release will still be a while. 😞
I *thought* I had the version with multiple #reactor #eventloop threads and quite some #lockfree stuff using #atomics finally crash free. I found that, while #valgrind doesn't help much, #clang's #thread #sanitizer is a very helpful debugging tool.
But I tested without #TLS (to be able to handle "massive load" which seemed necessary to trigger some of the more obscure data races). Also without the credential checkers that use child processes. Now I deployed the current state to my prod environment ... and saw a crash there (only after running a load test).
So, back to debugging. I hope the difference is not #TLS. This just doesn't work (for whatever reason) when enabling the address sanitizer, but I didn't check the thread sanitizer yet...
#LockFree
I did a lock-free queue implementation which is kind of off piste for me since I work with deferred reclamation and a queue is not a something you want to use deferred reclamation for or test with. So basically you want to use a ring buffer so you don't need reclamation to avoid the ABA problem. Most of the implementations I've seen aren't actually lock-free.
Anyway, I can get about 5 million enqueued/dequeues /sec using eventcounts for synchronization.
The #lockfree command #queue in #poser (for #swad) is finally fixed!
The original algorithm from [MS96] works fine *only* if the "free" function has some "magic" in place to defer freeing the object until no thread holds a reference any more ... and that magic is, well, left as an exercise to the reader. 🙈
Doing more research, I found a few suggestions how to do that "magic", including for example #hazardpointers ... but they're known to cause quite some runtime overhead, so not really an option. I decided to implement some "shared object manager" based on the ideas from [WICBS18], which is kind of a "manually triggered garbage collector" in the end. And hey, it works! 🥳
https://github.com/Zirias/poser/blob/master/src/lib/core/sharedobj.c
[MS96] https://dl.acm.org/doi/10.1145/248052.248106
[WICBS18] https://www.cs.rochester.edu/u/scott/papers/2018_PPoPP_IBR.pdf
This redesign of #poser (for #swad) to offer a "multi-reactor" (with multiple #threads running each their own event loop) starts to give me severe headaches.
There is *still* a very rare data #race in the #lockfree #queue. I *think* I can spot it in the pseudo code from the paper I used[1], see screenshot. Have a look at lines E7 and E8. Suppose the thread executing this is suspended after E7 for a "very long time". Now, some dequeue operation from some other thread will eventually dequeue whatever "Q->Tail" was pointing to, and then free it after consumption. Our poor thread resumes, checks the pointer already read in E6 for NULL successfully, and then tries a CAS on tail->next in E9, which is unfortunately inside an object that doesn't exist any more .... If the CAS succeeds because at this memory location happens to be "zero" bytes, we corrupted some random other object that might now reside there. 🤯
Please tell me whether I have an error in my thinking here. Can it be ....? 🤔
Meanwhile, after fixing and improving lots of things, I checked the alternative implementation using #mutexes again, and surprise: Although it's still a bit slower, the difference is now very very small. And it has the clear advantage that it never crashes. 🙈 I'm seriously considering to drop all the lock-free #atomics stuff again and just go with mutexes.

I guess this funny looking graph showing response time percentiles is exactly the result of one of 8 service worker threads having a lot more to do than all others. I wonder whether this could be a behavioral artifact of the #lockfree #queue used to distribute the accepted connections. 🤔
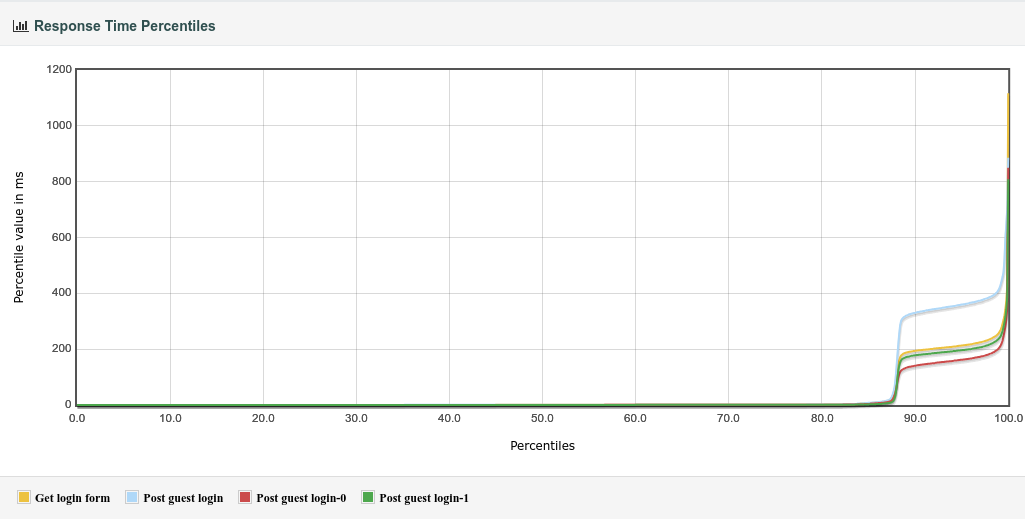
More interesting progress trying to make #swad suitable for very busy sites!
I realized that #TLS (both with #OpenSSL and #LibreSSL) is a *major* bottleneck. With TLS enabled, I couldn't cross 3000 requests per second, with somewhat acceptable response times (most below 500ms). Disabling TLS, I could really see the impact of a #lockfree queue as opposed to one protected by a #mutex. With the mutex, up to around 8000 req/s could be reached on the same hardware. And with a lockfree design, that quickly went beyond 10k req/s, but crashed. 😆
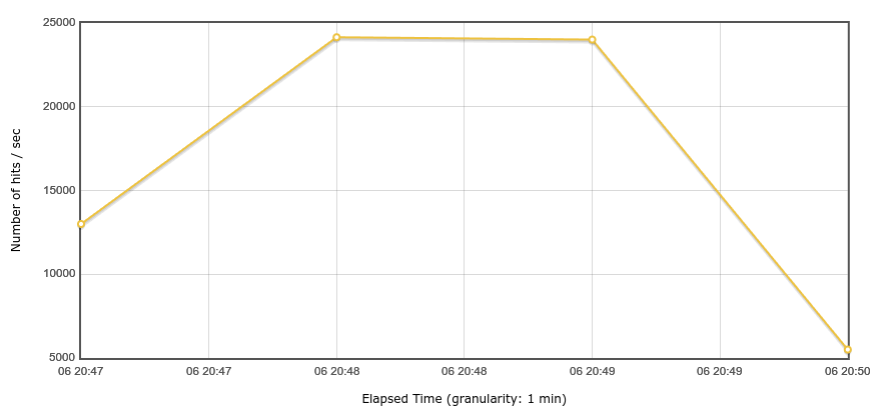
So I read some scientific papers 🙈 ... and redesigned a lot (*). And now it finally seems to work. My latest test reached a throughput of almost 25k req/s, with response times below 10ms for most requests! I really didn't expect to see *this* happen. 🤩 Maybe it could do even more, didn't try yet.
Open issue: Can I do something about TLS? There *must* be some way to make it perform at least a *bit* better...
(*) edit: Here's the design I finally used, with a much simplified "dequeue" because the queues in question are guaranteed to have only a single consumer: https://dl.acm.org/doi/10.1145/248052.248106
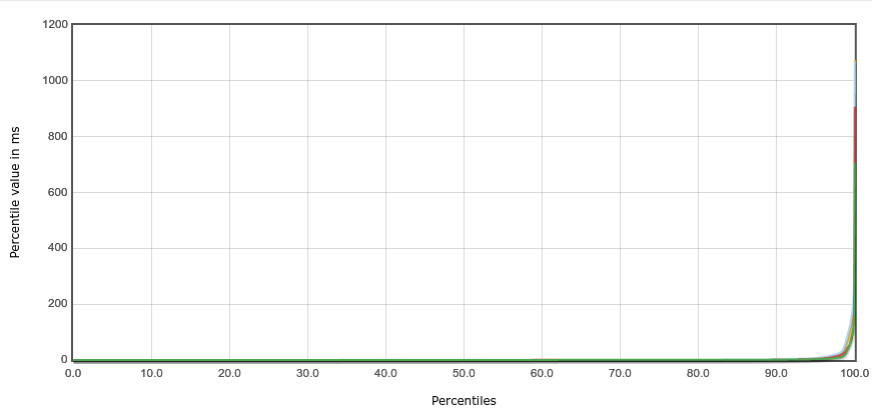
Getting somewhat closer to releasing a new version of #swad. I now improved the functionality to execute something on a different worker thread: Use an in-memory queue, providing a #lockfree version. This gives me a consistent reliable throughput of 3000 requests/s (with outliers up to 4500 r/s) at an average response time of 350 - 400 ms (with TLS enabled). For waking up worker threads, I implemented different backends as well: kqueue, eventfd and event-ports, the fallback is still a self-pipe.
So, #portability here really means implement lots of different flavors of the same thing.
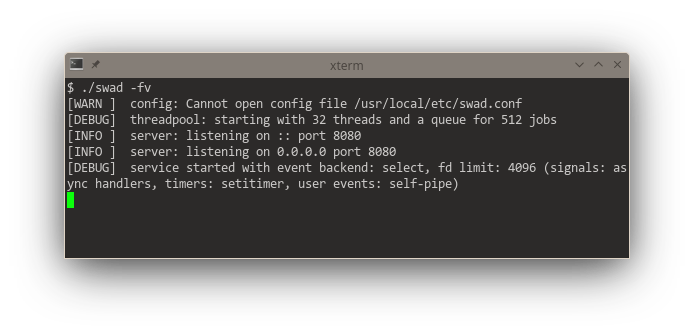
Looking at these startup logs, you can see that #kqueue (#FreeBSD and other BSDs) is really a "jack of all trades", being used for "everything" if available (and that's pretty awesome, it means one single #syscall per event loop iteration in the generic case). #illumos' (#Solaris) #eventports come somewhat close (but need a lot more syscalls as there's no "batch registering" and certain event types need to be re-registered every time they fired), they just can't do signals, but illumos offers Linux-compatible signalfd. Looking at #Linux, there's a "special case fd" for everything. 🙈 Plus #epoll also needs one syscall for each event to be registered. The "generic #POSIX" case without any of these interfaces is just added for completeness 😆
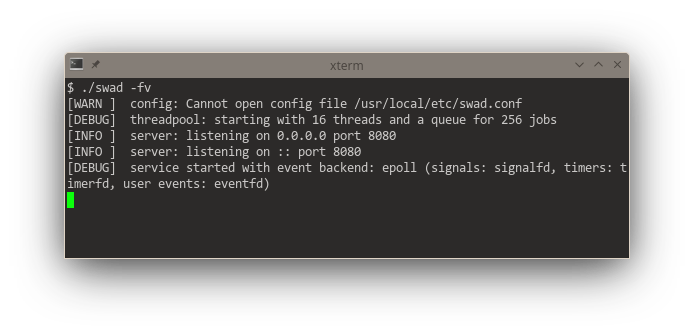
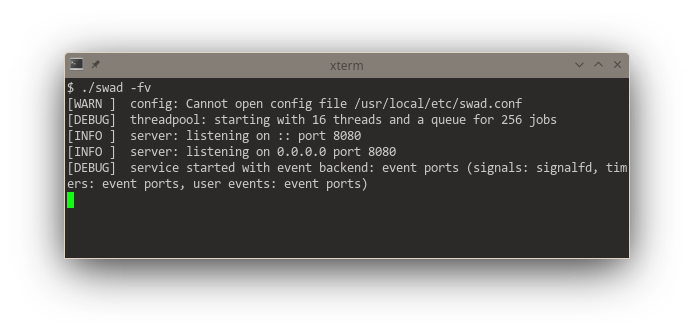
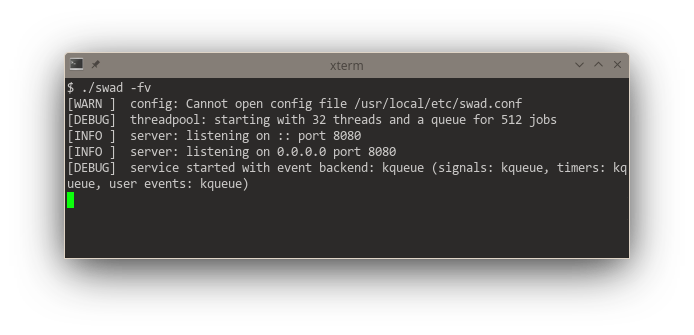
I now experimented with different ideas how to implement the #lockfree #queue for multiple producers and multiple consumers. Unsurprisingly, some ideas just didn't work. One deadlocked (okaaay ... so it wasn't lockfree) and I eventually gave up trying to understand why.
The "winner" so far is only "almost lockfree", but at least slightly improves performance. Throughput is the same as with the simple locked variant, but average response times are 10 to 20% quicker (although they deviate stronger for whatever reason). Well, that's committed for now:
https://github.com/Zirias/poser/commit/4f2f80a8266e4762e04ead2b802e7a7c1b55090b
I now added a #lockfree version of that MPMC job queue which is picked when the system headers claim that pointers are lockfree. Doesn't give any measurable performance gain 😞. Of course the #semaphore needs to stay, the pool threads need something to wait on. But I think the reason I can't get more than 3000 requests per second with my #jmeter stress test for #swad is that the machine's CPU is now completely busy 🙈.
Need to look into actually saving CPU cycles for further optimizations I guess...
Ruby, Ractors, and Lock-Free Data Structures
https://iliabylich.github.io/ruby-ractors-and-lock-free-data-structures/
#HackerNews #Ruby #Ractors #LockFree #DataStructures #ProgrammingConcurrency
Обсуждаем изменения в Go 1.24, мьютексы и пакет unsafe — открытие сезона митапов для гоферов в Москве
С приходом весны из-под сугробов снова начинают прорастать полезные митапы. На первой в сезоне Go-сходке от YADRO предлагаем присоединиться к обсуждению изменений Go 1.24. Эксперты из AvitoTech, Yandex и YADRO подискутируют, как обновления повлияют на код разработчиков. Также вы узнаете, как обеспечить высокопроизводительную конкурентность в Go и с умом применять пакет unsafe. Офлайн-участников ждет демозона с оборудованием для ЦОД и телеком-операторов, технические интерактивы и подарки.
CppCon 2024 SESSION ANNOUNCEMENT: When Lock-Free Still Isn't Enough: An Introduction to Wait-Free Programming and Concurrency Techniques by Daniel Anderson
Register now: https://cppcon.org/registration/
CppCon 2024 SESSION ANNOUNCEMENT: Multi Producer, Multi Consumer, Lock Free, Atomic Queue - User API and Implementation by Erez Strauss
Register now: https://cppcon.org/registration/
Volatile, Lock-free, Immutable, Atomic в Java. Как понять и начать использовать
Привет, меня зовут Денис Агапитов, я руководитель группы Platform Core компании Bercut. Сегодня хочу поговорить об одном из вариантов lock-free алгоритмов в Java. Разберём как с ним связано ключевое слово volatile и паттерн immutable .
https://habr.com/ru/companies/bercut/articles/822253/
#java #atomic #volatile #multithreading #immutable #lockfree
ACCU 2024 SESSION ANNOUNCEMENT: Introduction to Lock/Wait Free Algorithms: Defining and Understanding the Terms by Jeffrey Mendelsohn
Register now at https://accuconference.org/pricing/
[Перевод] Xv6: учебная Unix-подобная ОС. Глава 6. Блокировки
Ядро ОС выполняет программы параллельно и переключает потоки по таймеру. Каждый процессор выполняет поток независимо от других. Процессоры используют оперативную память совместно, поэтому важно защитить структуры данных от одновременного доступа. Потоки испортят данные, если процессор переключится на другой поток, когда первый поток еще не завершил запись. Потоки конкурируют за доступ к структуре данных. Ядро кишит структурами, которые потоки используют совместно. Блокировки защищают данные при конкурентном доступе. Глава расскажет, зачем нужны блокировки, как xv6 реализует и использует блокировки.
https://habr.com/ru/articles/797557/
#xv6 #блокировки #прерывания #взаимоблокировки #потоки #параллельное_программирование #многопоточность #pthreads #lockfree
Code generation around atomics is strange.
What is desired is `lock cmpxchg16b` but it hard work to make compiler produce it.
clang has the best codegen IMO. It took me a while to realize I needed `alignas(16)`
This promises to be a good series on #lockfree #algorithms.
Wrote a #LockFree (and Obstruction-Free) memory #allocator for use in low-latency real-time threads.
Blocks are 64-byte aligned to avoid false sharing, alloc+free calls of the underlying Bucket- and Bump-Allocators are O(1).
A seperate thread is notified when the Bump-Allocator reaches a watermark. It will then extend the pool of pre-allocated (and pre-faulted) memory, so the Bump-Allocator can continue to serve requests concurrently without syscalls.
https://github.com/tim-janik/anklang/blob/trunk/ase/loft.hh
#Anklang
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst