Ah yes, the future is here! 🌟 A "commercial-scale diffusion language model" that can't even handle a basic website prompt without a condescending "Just a moment..." 🙄. Truly groundbreaking tech that requires you to sacrifice #JavaScript and #cookies at the altar of web browsing functionality. 🍪💻
https://www.inceptionlabs.ai/introducing-mercury #futuretech #diffusionmodel #webdevelopment #HackerNews #ngated
#diffusionmodel
AI Face Anonymizer Masks Human Identity in Images
We're all pretty familiar with AI's ability to create realistic-looking images of people that don't exist, but here's an unusual implementation of using that technology for a different purpose: masking people's identity without altering the substance of the image itself. The result is the photo's content and "purpose" (for lack of a better term) of the image remains unchanged, while at the same time becoming impossible to identify the actual person in it. This invites some interesting privacy-related applications.
Originals on left, anonymized versions on the right. The substance of the images has not changed.
The paper for Face Anonymization Made Simple has all the details, but the method boils down to using diffusion models to take an input image, automatically pick out identity-related features, and alter them in a way that looks more or less natural. For this purpose, identity-related features essentially means key parts of a human face. Other elements of the photo (background, expression, pose, clothing) are left unchanged. As a concept it's been explored before, but researchers show that this versatile method is both simpler and better-performing than others.
Diffusion models are the essence of AI image generators like Stable Diffusion. The fact that they can be run locally on personal hardware has opened the doors to all kinds of interesting experimentation, like this haunted mirror and other interactive experiments. Forget tweaking dull sliders like "brightness" and "contrast" for an image. How about altering the level of "moss", "fire", or "cookie" instead?
#artificialintelligence #ai #aiimagegenerator #anonymity #anonymizer #diffusionmodel

If I had the time, energy, and education to pull it off, I'd do some scholarship and writing elaborating on this juxtaposition:
- Statistics, as a field of study, gained significant energy and support from eugenicists with the purpose of "scientizing" their prejudices. Some of the major early thinkers in modern statistics, like Galton, Pearson, and Fisher, were eugenicists out loud; see https://nautil.us/how-eugenics-shaped-statistics-238014/
- Large language models and diffusion models rely on certain kinds of statistical methods, but discard any notion of confidence interval or validation that's grounded in reality. For instance, the LLM inside GPT outputs a probability distribution over the tokens (words) that could follow the input prompt. However, there is no way to even make sense of a probability distribution like this in real-world terms, let alone measure anything about how well it matches reality. See for instance https://aclanthology.org/2020.acl-main.463.pdf and Michael Reddy's The conduit metaphor: A case of frame conflict in our language about language
Early on in this latest AI hype cycle I wrote a note to myself that this style of AI is necessarily biased. In other words, the bias coming out isn't primarily a function of biased input data (though of course that's a problem too). That'd be a kind of contingent bias that could be addressed. Rather, the bias these systems exhibit is a function of how the things are structured at their core, and no amount of data curating can overcome it. I can't prove this, so let's call it a hypothesis, but I believe it.
#AI #GenAI #GenerativeAI #ChatGPT #GPT #Gemini #Claude #Llama #StableDiffusion #Midjourney #DallE #LLM #DiffusionModel #linguistics #NLP
- Statistics, as a field of study, gained significant energy and support from eugenicists with the purpose of "scientizing" their prejudices. Some of the major early thinkers in modern statistics, like Galton, Pearson, and Fisher, were eugenicists out loud; see https://nautil.us/how-eugenics-shaped-statistics-238014/
- Large language models and diffusion models rely on certain kinds of statistical methods, but discard any notion of confidence interval or validation that's grounded in reality. For instance, the LLM inside GPT outputs a probability distribution over the tokens (words) that could follow the input prompt. However, there is no way to even make sense of a probability distribution like this in real-world terms, let alone measure anything about how well it matches reality. See for instance https://aclanthology.org/2020.acl-main.463.pdf and Michael Reddy's The conduit metaphor: A case of frame conflict in our language about language
Early on in this latest AI hype cycle I wrote a note to myself that this style of AI is necessarily biased. In other words, the bias coming out isn't primarily a function of biased input data (though of course that's a problem too). That'd be a kind of contingent bias that could be addressed. Rather, the bias these systems exhibit is a function of how the things are structured at their core, and no amount of data curating can overcome it. I can't prove this, so let's call it a hypothesis, but I believe it.
#AI #GenAI #GenerativeAI #ChatGPT #GPT #Gemini #Claude #Llama #StableDiffusion #Midjourney #DallE #LLM #DiffusionModel #linguistics #NLP
#Platforms throw away the diffusion on innovations idea that you need 'knowledge' to be an innovator or early adopter.
#AI gets incorporated into your workflow whether you have knowledge, are persuaded, or not.
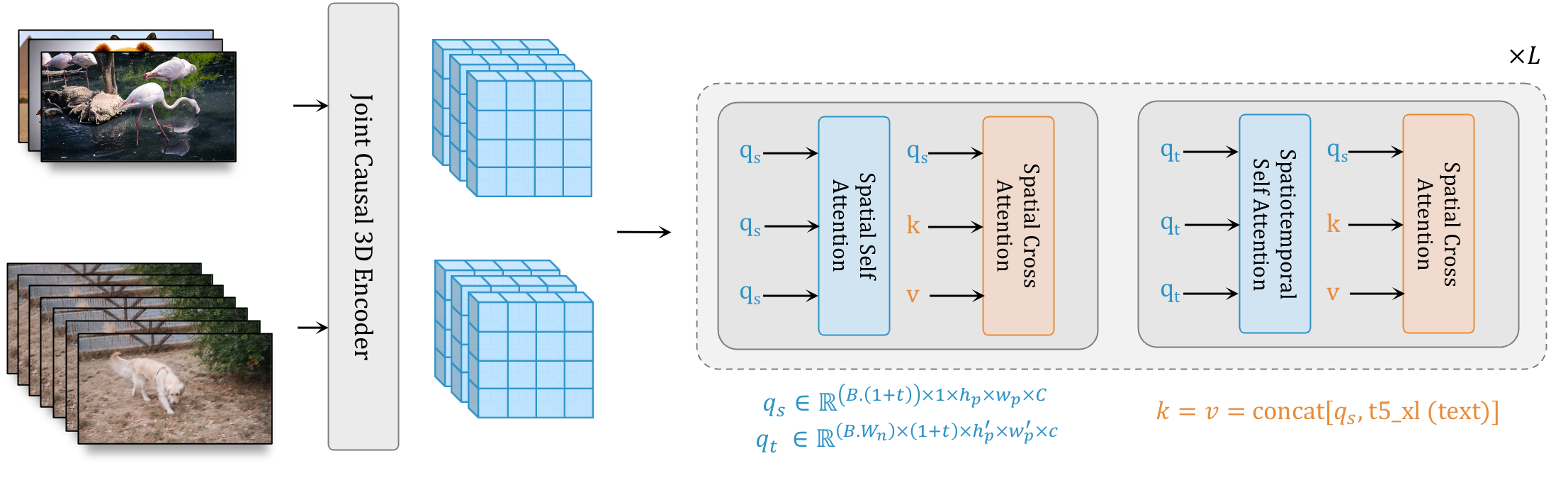
This is the next stage: W.A.L.T, a #DiffusionModel for #photorealistic #VideoGeneration 🤖🎬 Developed by Gupta et al. (2023), based on a #transformer that is trained on image and video generation in a shared #LatentSpace.
🌍 https://walt-video-diffusion.github.io (including many sample movies)
📔 https://arxiv.org/abs/2312.06662
Remove the poodle で犬が画像から取り除かれてる。こういうのは他の画像生成AIでもできてると思うけど、どうなんですか。
#Meta #AI #Emu #diffusionModel #video
Meta、テキストからの動画生成モデル「Emu Video」とマルチタスク画像編集モデル「Emu Edit」を発表
https://atmarkit.itmedia.co.jp/ait/articles/2311/24/news050.html
#Meta #AI #Emu #diffusionModel #video
Generate:Biomedicines describes its Chroma generative A.I. model in yesterday's issue of the journal Nature, and is making the model available as open source through GitHub.
https://sciencebusiness.technewslit.com/?p=45409
#News #Press #Science #Business #Protein #Therapeutics #ArtificialIntelligence #NeuralNetwork #GenerativeAI #OpenSource #DiffusionModel #University
Generative KI hilft Robotern beim Packen. Die als Bildgeneratoren bekannten Diffusionsmodelle können auch komplexe Packaufgaben lösen. #KI #AI #Diffusionmodel #Roboter #KuenstlicheIntelligenz
https://www.scinexx.de/news/technik/generative-ki-hilft-robotern-beim-packen/
@SibylleBerg yes, so ist es leider.
Bei meiner Arbeit mit #stablediffusion für mein Projekt #techturk ist das immer wieder aufgefallen. Prompts funktionieren weit besser auf englisch und landet das #diffusionmodel in seinem Biasbereich zeigt es: weiße Männer zwischen 30-40 Jahren - eben die die federführend die Technologie bauen.
Allerhöchste Zeit gegenzusteuern!
New text2image model from Stability.ai available:
DeepFloyd IF is a modular neural network based on the cascaded approach.
Went back to tweak this image. I’m really happy with the finished result. 😍
#aiart #synthography #SDXL #stablediffusion #automatic1111 #stabilityai #texttoimage #diffusionmodel

GETMusic Uses Machine Learning to Generate Music, Understands Tracks https://hackaday.com/2023/07/27/getmusic-uses-machine-learning-to-generate-music-understands-tracks/ #ArtificialIntelligence #diffusionmodel #MusicalHacks #generative #tracks #music #midi #ai
"Implicit Transfer Operator Learning: Multiple Time-Resolution Surrogates for Molecular Dynamics"
https://arxiv.org/abs/2305.18046
#MolecularDynamics #ComputationalModel #SurrogateModel #TimeScale #Simulation #DiffusionModel
This wheat field with wild daisies does not exist.
#diffusionmodel #stablediffusion #generative

New text2image model from Stability.ai available:
DeepFloyd IF is a modular neural network based on the cascaded approach.
Imagining transitional forms. [overGround:underStory] process work.
#electronicLiterature #generativeArt #designResearch #diffusionModel #practiceBasedResearch #worldBuilding #visualKnowledges

640 Landscapes Ought To Be Enough For Anybody – a comparison of five #stablediffusion models for landscape paintings • http://thndrbrrr.zone/blog/640-landscapes-stable-diffusion-model-comparison/ • #aiart #generativeart #generativeAI #diffusionmodel #ai #digitalart
We start the new year telling you that the #Neuro #SummerSchool in Lipari/Sicily will happen again @neuromatch.social At the beginning of July. This was last year: https://www.neurosummerschool.org/ For now Chilling under the sea(enjoy my results from #Diffusionmodel colab :-) #stablediffusion #neuroimaging #Academicchatter

Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst