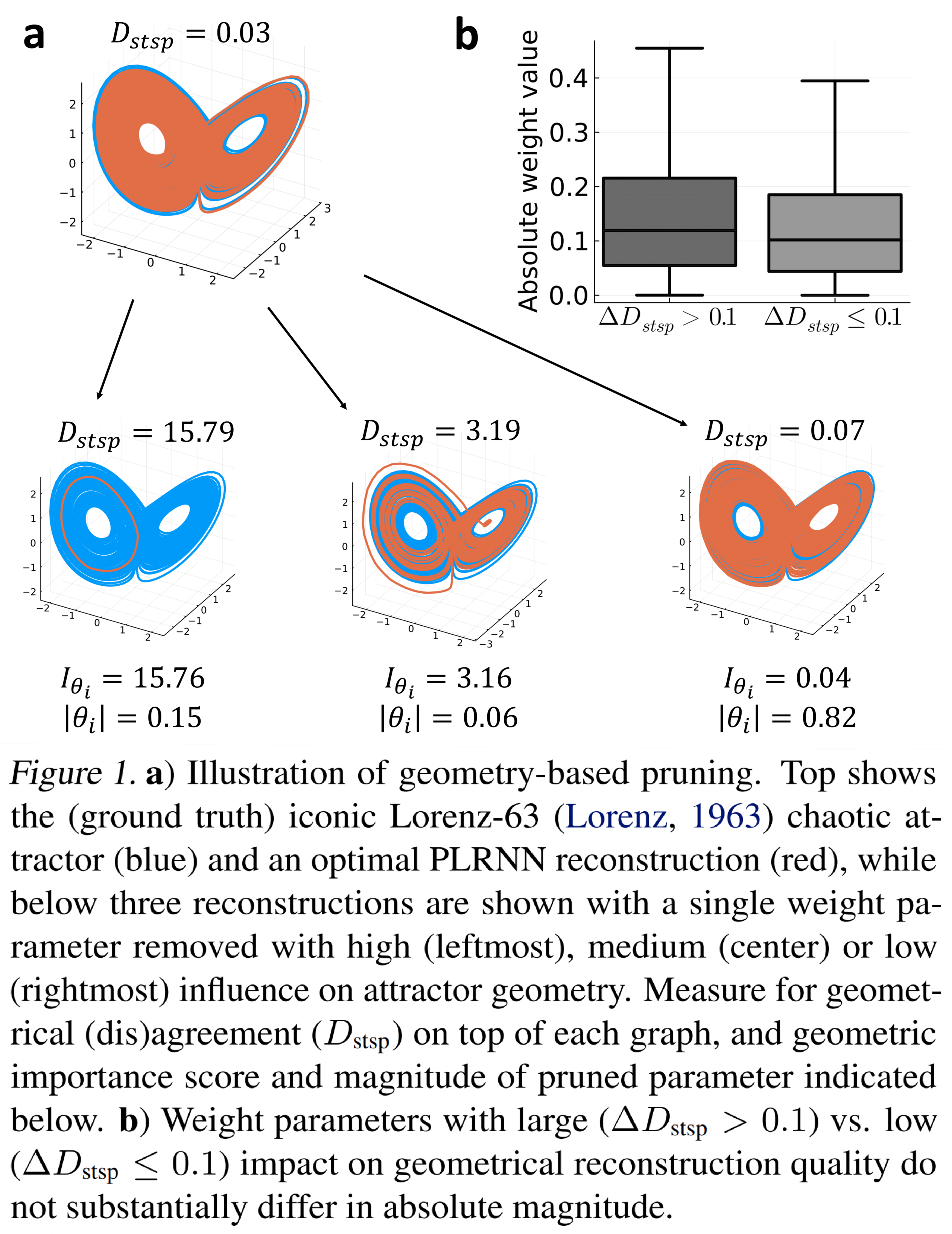
Magnitude-based pruning is a standard #ML #AI technique to produce sparse models, but in our @ICMLConf paper https://www.arxiv.org/abs/2406.04934 we find it doesn’t work for #DynamicalSystems reconstruction.
Instead, via geometry-based pruning we find the *network topology* is far more important!
It turns out that even RNN weights small in relative size can have a dramatic impact on system dynamics as measured by attractor agreement. In fact, there is not much difference between small and large magnitude weights in contribution to DS reconstruction quality. (Fig. 1)
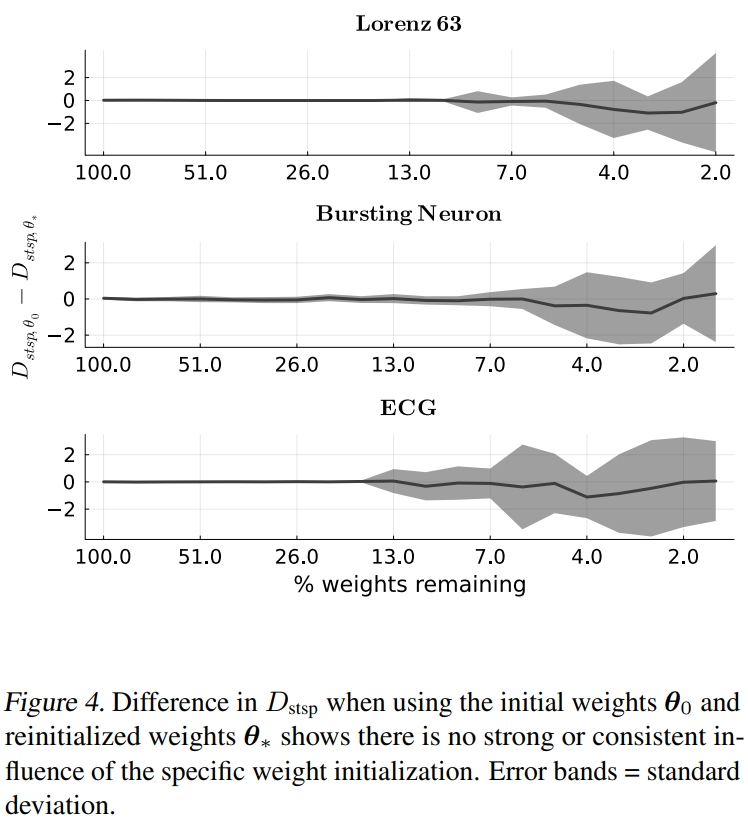
Following the lottery ticket hypothesis, we find that large RNNs still contain winning tickets that can be carved out by *geometry-based* pruning, but that these tickets are defined by *graph topology* with initial weight values hardly playing any role. (Fig. 4)
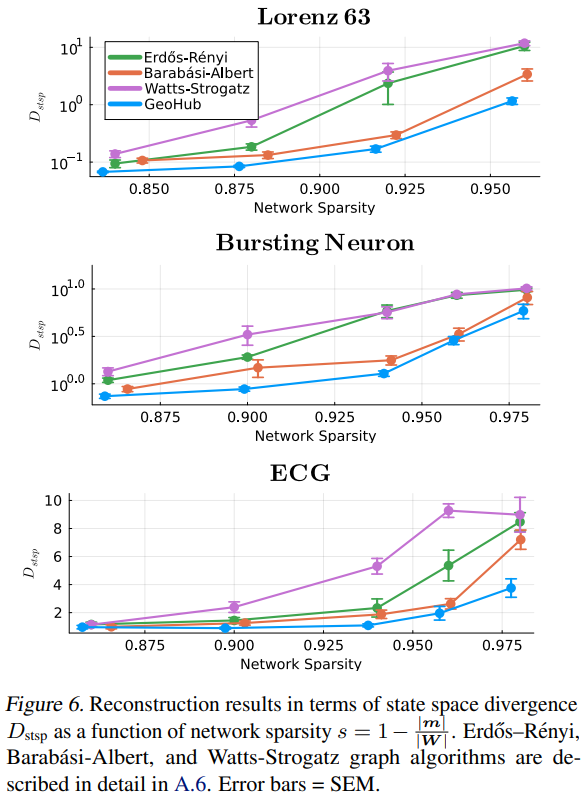
The ‘winning’ graph topology distilled from trained RNNs turns out to exhibit both hub-like and small world features. RNNs initialized with this topology perform significantly better than equally-sized RNNs with random, Watts-Strogatz or Barabási-Albert topology. (Fig. 6)
… and also train much faster. (Fig. 7)
This all makes sense: Natural and engineered DS often bear a specific sparse network topology that is crucial for shaping their dynamics!
Fantastic work lead by Christoph Hemmer with Manuel Brenner and Florian Hess!