HPCTransCompile: An AI Compiler Generated Dataset for High-Performance CUDA Transpilation and LLM Preliminary Exploration
#performanceportability
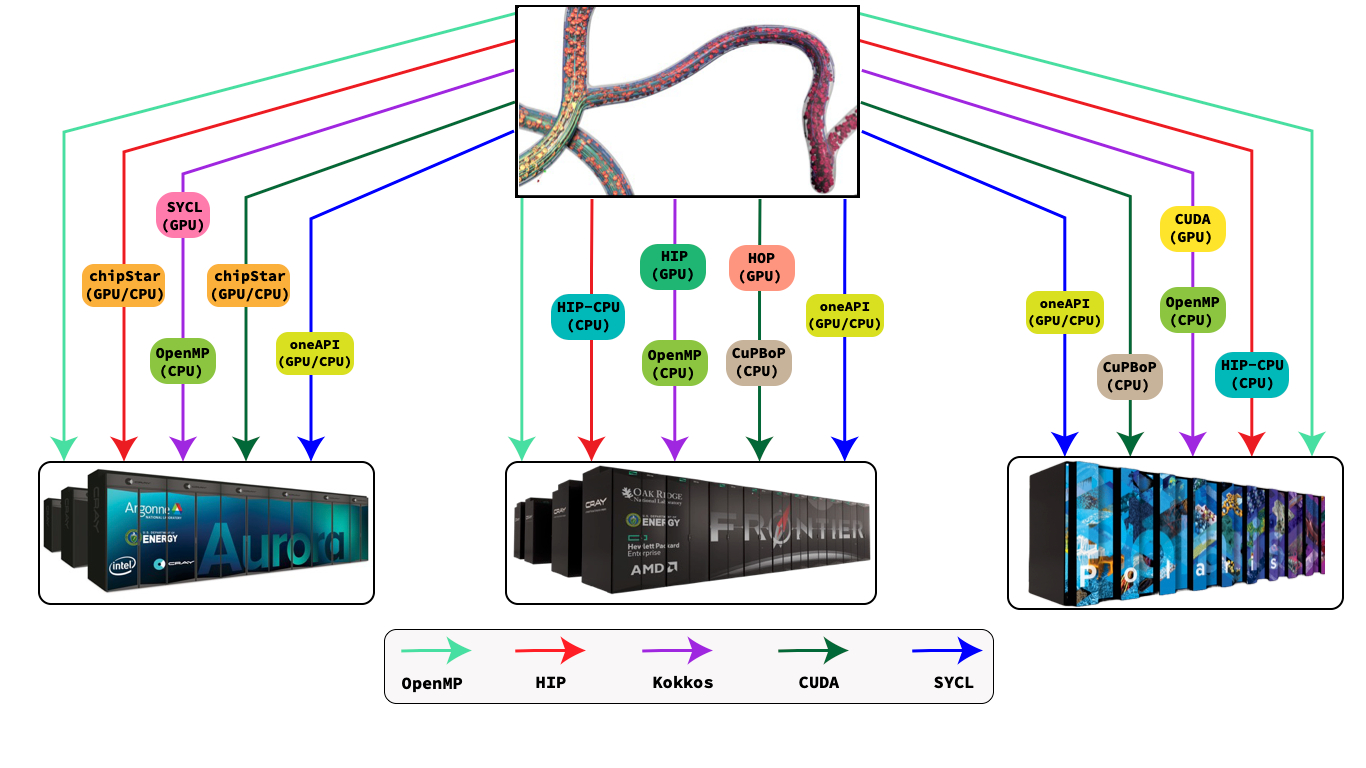
🧪Curious about high performance across GPUs? Our new paper benchmarks a parallel FSI code on CUDA, SYCL & OpenMP across top systems. See Aristotle Martin present it at #ISC2025 on June 11, 10:45 in Hamburg! #HPC #GPUcomputing #PerformancePortability
Thesis: Acceleration as a Service (XaaS) Source Containers
Exploring SYCL for batched kernels with memory allocations
Concurrent Scheduling of High-Level Parallel Programs on Multi-GPU Systems
CPU-GPU co-execution through the exploitation of hybrid technologies via SYCL
#SYCL #OpenCL #CUDA #LLVM #PerformancePortability #LoadBalancing #HybridComputing
We're used to leaning on children's books in Computer Science - with Gulliver's big-endian vs little-endian. Back at Supercomputing hashtag#SC24, I spoke at the hashtag#Intel booth all about open standards, performance portability, and the journey up the Yellow Brick Road to see the Wizard of Oz. Check out the video of the talk on YouTube:
https://youtu.be/xO8FGAOScpo?si=_BnVilvTBa0Ns6dX
#performanceportability #OpenMP #SYCL
Analyzing the Performance Portability of SYCL across CPUs, GPUs, and Hybrid Systems with Protein Database Search
#SYCL #oneAPI #Bioinformatics #Databases #HPC #PerformancePortability #Package
Performance portability via C++ PSTL, SYCL, OpenMP, and HIP: the Gaia AVU-GSR case study
#HIP #SYCL #OpenMP #CUDA #PerformancePortability #HPC #Astrophysics #Package
Kokkidio: Fast, expressive, portable code, based on Kokkos and Eigen
Thesis: Collection skeletons: declarative abstractions for data collections
Challenging Portability Paradigms: FPGA Acceleration Using SYCL and OpenCL
Thesis: Enhancing Code Portability, Problem Scale, and Storage Efficiency in Exascale Applicationsin Exascale Applications
#CUDA #OpenMP #MPI #HPC #PIC #ParticleInCell #PerformancePortability
Evaluating Operators in Deep Neural Networks for Improving Performance Portability of SYCL
Thesis: Automatic Code Rewriting for Performance Portability
Performance Portable Monte Carlo Particle Transport on Intel, NVIDIA, and AMD GPUs
#CUDA #OpenMP #MonteCarlo #PerformancePortability #Intel #AMD #NVIDIA #Package
Retargeting and Respecializing GPU Workloads for Performance Portability
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst