
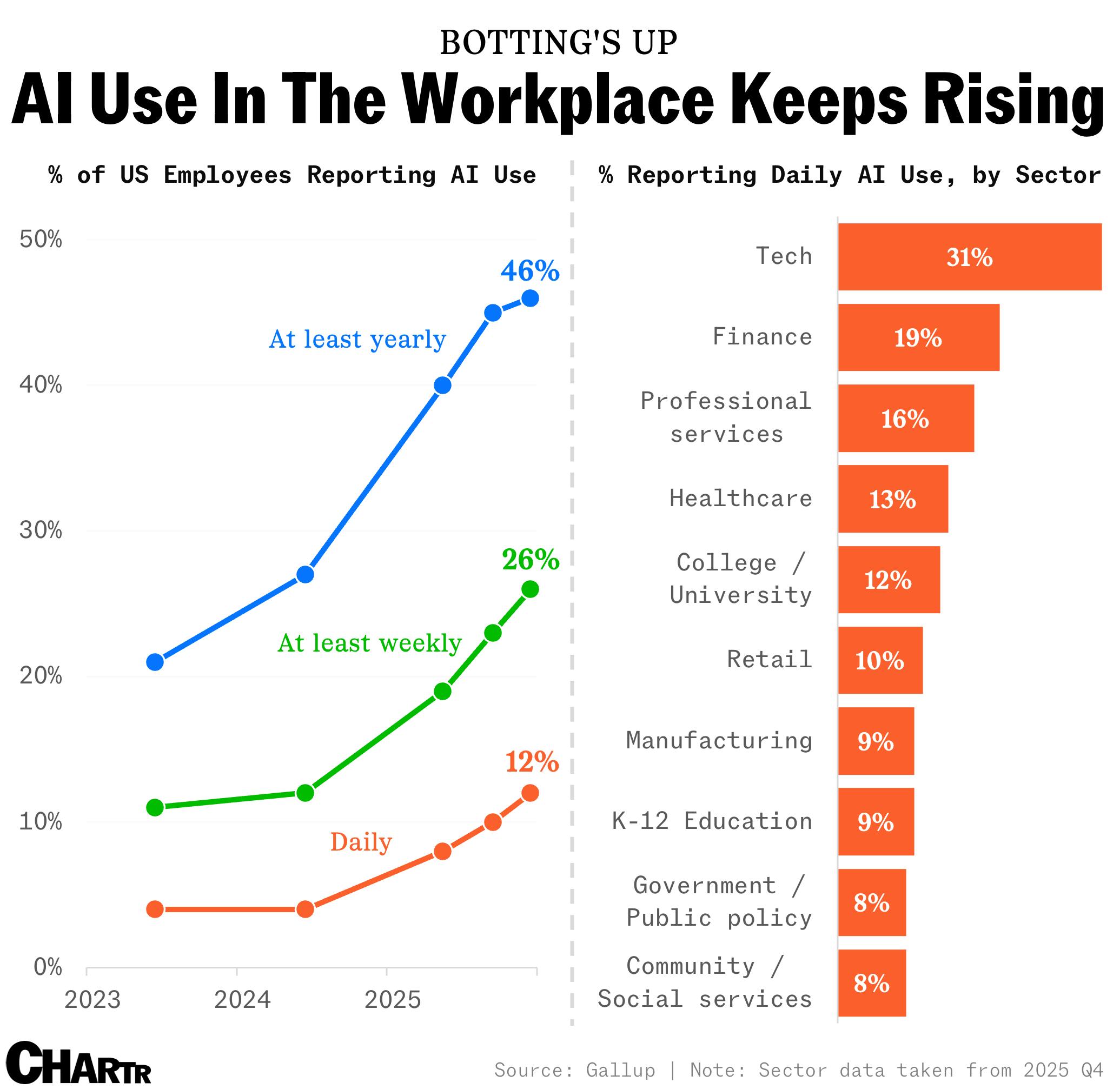
12% of American workers use artificial intelligence in their roles every day
#machine_learning

Почему ваш RAG не найдёт нужные документы: математический потолок embedding-моделей
Все говорят про embedding-модели в RAG: бенчмарки MTEB, размеры моделей, chunking-стратегии. Но никто не задаёт главный вопрос: а сколько вообще документов может найти single-vector retrieval? Google DeepMind посчитали. Оказалось, что даже 4096-мерные эмбеддинги упираются в математический потолок — есть задачи, где они физически не смогут найти нужный документ из топ-2, даже если модель идеально обучена. В статье разбирается исследование LIMIT, показаны примеры, где dense retrieval проваливается (а BM25 справляется), и объяснено, почему для production-систем нужен гибридный поиск, а не слепая вера в SOTA-эмбеддинги.
https://habr.com/ru/articles/987954/
#RAG #embedding #retrieval #machine_learning #BM25 #поиск #нейросети #векторные_базы_данных
Which AI Lies Best? A game theory classic designed by John Nash
https://so-long-sucker.vercel.app/
#ycombinator #AI_deception #AI_benchmark #Gemini_3 #GPT #LLM_evaluation #AI_safety #game_theory #John_Nash #betrayal_game #AI_alignment #machine_learning #artificial_intelligence #AI_behavior #deception_detection
Which AI Lies Best? LLMs play a 1950s betrayal game by John Nash
https://so-long-sucker.vercel.app/
#ycombinator #AI_deception #AI_benchmark #Gemini_3 #GPT #LLM_evaluation #AI_safety #game_theory #John_Nash #betrayal_game #AI_alignment #machine_learning #artificial_intelligence #AI_behavior #deception_detection
Покоряем гору временных рядов: делаем прогноз для 200+ рядов с библиотекой Etna
Я работаю дата-сайентистом 5 лет и до сих пор испытываю боль, когда нужно сделать MVP по временным рядам. Начиная с того, как построить несколько графиков одновременно без «слипшихся» меток по осям, заканчивая поиском подходящего метода очистки ряда от аномалий. И всё это венчает цикл по каждому ряду с бесконечным жонглированием данными между numpy, pandas, sklearn, yet_another_library. Если вы DS, и тоже, как и я, устали от вот этого всего, добро пожаловать под кат. Я покажу, как написать production-ready код для прогноза 200+ временных рядов от EDA до результата. Разберем на практике, как бороться с аномалиями, ловить смены тренда и в итоге – получить масштабируемое решение, а не очередной «велосипед».
https://habr.com/ru/companies/magnit/articles/985864/
#data_science #machine_learning #анализ_данных #временные_ряды #productionready_код #прогнозирование #прогнозирование_спроса #магнит #etna
Как 17-летний писал RAG-алгоритм для хакатона AI for Finance Hack: ретроспектива
Привет, Хабр! Мой путь в мире IT официально начался относительно недавно: в октябре 2025 года. До этого программирование вообще не выходило за рамки увлечений. Но однажды я решил испытать удачу и выйти на тропу приключений, после которой я уже не вернулся прежним...
https://habr.com/ru/articles/986180/
#data_science #python #ai #rag #github #соревнование #хакатон #райффайзенбанк #machine_learning #ai_engineering
Embedding — как машины понимают смысл текста
Я уверен, вы видели модели машинного обучения, которые принимают текст и предсказывают, является ли он спамом. Аналогично модель может проанализировать отзыв о фильме и определить его тональность — положительную или отрицательную, понимать что «груша» связана с «яблоком» куда больше, чем с «теплоходом». Первое правило обучения любой модели машинного обучения — это преобразование входных данных в числа. Цифровой объект можно представить числом: картинку, текст, аудио или видеофайл — практически всё что угодно. Для того чтобы ввести этот объект в нашу ML модель как некое понятие, мы должны преобразовать его в определённый набор чисел. По этому набор чисел мы сможем определить, что, например, этот объект «яблоко», а не «груша». С картинками все просто. В чёрно-белом изображении (в градациях серого) самый яркий пиксель имеет значение 1, самый тёмный — 0, а оттенки серого имеют значения от 0 до 1. Такое числовое представление упрощает обработку изображений. Преобразовав изображение в цифровую форму на основе значений пикселей, мы можем использовать его в качестве входных данных для обучения нашей модели, позволяя нейронной сети обучаться на значениях пикселей. Однако что делать с текстом? Как спроецировать буквы в числа?
https://habr.com/ru/companies/ruvds/articles/983958/
#embeddings #эмбеддинги #вектор #векторное_представление #машинное_обучение #ml #machine_learning #nlp #нлп #ruvds_статьи

Even Linus Torvalds Is Vibe Coding Now
Epoch AI released new data finding that global AI compute capacity is doubling every 7 months, with Nvidia chips accounting for over 60% of production since 2022
ML на Мосбирже — почему мой грааль не работает?
Время после нового года решил провести с пользой и окунуться в машинное обучение. Заняться Machine Learning — и посмотреть получится что‑то или нет с российским рынком акций на Московской бирже. Моей целью было построить такую систему, которая будет учиться на истории и в перспективе торговать лучше чем случайное блуждание 50/50. Но из‑за комиссий и спреда подобные блуждания изначально отрицательны — чтобы выйти в плюс надо как минимум покрывать комиссии. Если говорить о результатах очень кратко, то технически всё работает, но вот финансовый результат на грани безубыточности. Если Вы только интересуетесь этой темой Вы можете посмотреть какие‑то шаги в моей статье, а если Вы уже опытный разработчик подобных систем, то можете подсказать что‑нибудь в комментариях. Причём вся эта работа выглядит совершенно не так как показывается в фильмах про уолл‑стрит: фактически это написание скриптов и монотонный запуск и всё происходит полностью локально на компьютере.
https://habr.com/ru/articles/984190/
#machine_learning #deep_learning #московская_биржа #мосбиржа #auc #Сезон_ИИ_в_разработке #алгоритмическая_торговля
Reproducing DeepSeek's MHC: When Residual Connections Explode
https://taylorkolasinski.com/notes/mhc-reproduction/
#ycombinator #Taylor_Kolasinski #ML_systems #machine_learning #reinforcement_learning #robotics #Brooklyn #software_engineer

AI для PHP-разработчиков: практика без Python и data science
Про AI сейчас пишут много, мягко говоря. Причём пишут буквально все, кому не лень. Но если вы PHP-разработчик, то, скорее всего, ощущение примерно такое: тема вроде бы важная, но почти всё – не для вас, а двигаться в эту сторону нужно, ибо... ну, вы и сами понимаете. Большинство материалов сразу уезжают в Python, Jupyter, PyTorch, обучение моделей, математику и датасеты. Даже когда речь идёт не про data science, а про практику – примеры всё равно из другого мира. Я с этим столкнулся довольно быстро, когда попытался понять, как вообще можно использовать AI в обычной PHP-разработке. После нескольких практических кейсов в своих проектах у меня сложилось собственное понимание ситуации. Я понимаю, что Python сегодня де-факто стандарт в мире машинного обучения, но есть огромное количество ситуаций, когда можно использовать AI или ML из PHP без Python-стека, а кроме того мне, как PHP-разработчику, хочется самому разбираться в теме, а не просто делать API-запросы к ChatGPT.
https://habr.com/ru/articles/984042/
#php #machinelearning #ml #ai #backend #machine_learning #machinelearning #искусственный_интеллект #backendпрограммирование #backendразработка
AI drove 20% of all global orders 2025 holiday season, generating $262 billion in revenue through personalized recommendations
Machine Learning в экологии
В экологии происходит настоящая ML-революция. Число публикаций с использованием матмоделирования растёт по закону Мура, а наличие ML-моделей и прогнозов становится стандартом в статьях про биологические виды и их будущее. Появились модели, предсказывающие распространение видов в пространстве и во времени - на 100 лет вперёд или на 6000 лет назад. Экологи начали моделировать взаимодействие видов, сообществ - и целых экосистем. Расскажу, почему это произошло, как работают такие модели на практике - и к чему всё это нас приведёт.
https://habr.com/ru/articles/983756/
#SDM #Machine_learning #ML #Python #экологические_модели #биогеография
Memory Is All You Need: Активная память для трансформеров — мой новый подход к долгосрочным зависимостям в ИИ
Переосмысливаем память в ИИ: от пассивного контекста к активной, 'живой' системе. Мой проект MemNet с Hebbian-графом и 'сновидениями' решает задачи долгосрочных зависимостей. Код на GitHub + эксперименты внутри!
https://habr.com/ru/articles/983684/
#AI #machine_learning #transformers #memory_augmented_networks #continual_learning #neural_memory #longterm_dependencies #rag #neuroscience #paradigm_shift
BBC tested ChatGPT, Copilot, Gemini, and Perplexity on 100 of its own articles; 51% of answers had significant issues
Researchers figured out how to run a 120-billion parameter model across four regular desktop PCs
Opus 4.5 is going to change everything
Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst