
Google đang bị chỉ trích vì dù có TPUs tự phát triển nhưng model Gemini lại kém hiệu quả. Người dùng cho rằng Gemini chỉ mạnh với câu hỏi đơn, tạo hình ảnh, nhưng yếu trong thấu hiểu dài, xử lý chủ đề liên tiếp, và tỷ lệ ảo tưởng cao gấp 3-5 lần so với Claude/ChatGPT. Nhiều người dùng phải tạo mới chủ đề liên tục khi dùng Gemini, trong khi 2 model kia duy trì cuộc trò chuyện hàng trăm bước. Google đáng lẽ nên đầu tư chip Nvidia. #Google #TPU #AIBenchmarks #AIModels #KhoaHocMayTinh #CongNgheAI
#AIbenchmarks

OpenAI releases GPT-5.2 after “code red” Google threat alert https://arstechni.ca/rdGC #largelanguagemodels #machinelearning #AIassistants #AIbenchmarks #GoogleGemini #agenticAI #samaltman #AIcoding #ChatGPT #Gemini3 #GPT-5.2 #Biz&IT #google #openai #GPT-5 #AI

Google released a benchmark to evaluate AI research agents—then topped its own leaderboard. The company built the infrastructure, defined the test, and declared itself the winner. Competitors without integrated search can't compete on tasks designed around Google's architecture.


Meta signals a shift: the upcoming Llama 4 may no longer be fully open‑source, with a fee‑based model hinted by Zuckerberg. Industry players like Scale AI and Superintelligence Labs are watching the impact on AI benchmarks and community collaboration. What does this mean for open‑source AI? Read more. #MetaAI #Llama4 #OpenSourceAI #AIbenchmarks
🔗 https://aidailypost.com/news/meta-may-charge-future-ai-model-shifting-from-llama-4-opensource

Phoronix công bố benchmarks Llama.cpp dùng Vulkan, so sánh hiệu suất chạy AI cục bộ. Kết quả cho thấy tiềm năng tối ưu hóa mô hình ngôn ngữ nhỏ gọn. #LlamaCpp #Vulkan #AIBenchmarks #CôngNghệAI #MachineLearning
https://www.reddit.com/r/LocalLLaMA/comments/1picehv/llamacpp_vulkan_benchmarks_by_phoronix/

New DeepSeek V3.2 Speciale Model Claims Reasoning Parity with Gemini 3 Pro
#AI #DeepSeek #GenAI #LLMs #AIBenchmarks #OpenSourceAI #GoogleGemini #Gemini3 #GPT5 #AgenticAI #AIReasoning #ChinaAI


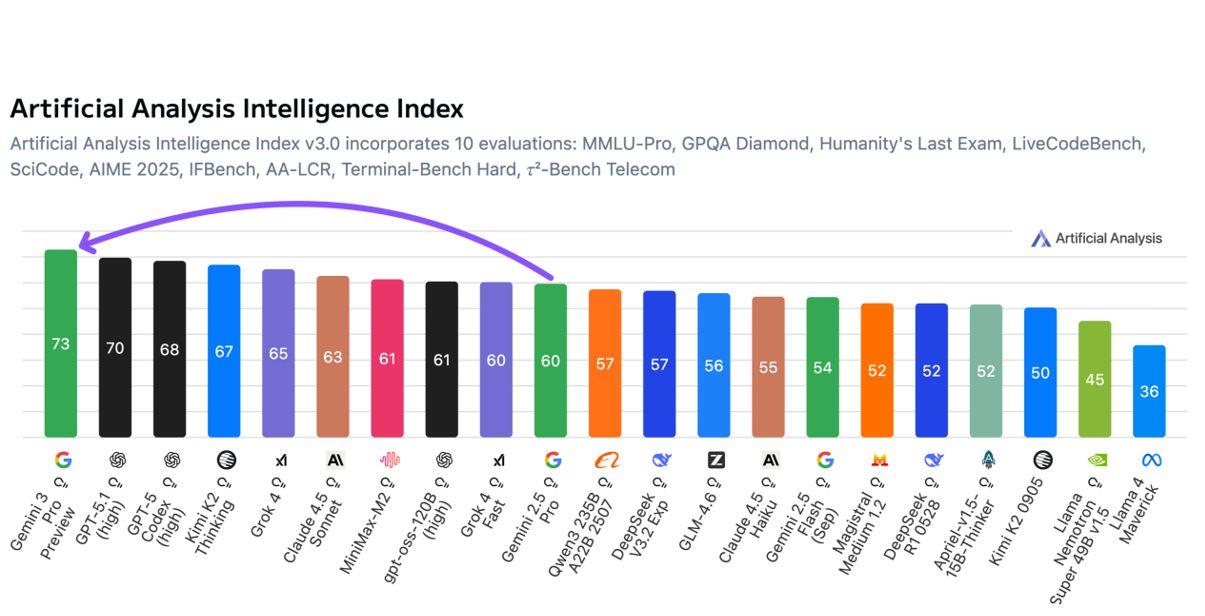
🚀 Google überholt OpenAI! Gemini 3 Pro ist laut Artificial Analysis das leistungsstärkste Sprachmodell.
👉 Meine Meinung: Starkes Modell, aber teuer. Der echte Vorteil liegt in Googles Integration in eigene Dienste. Diese wachsende Marktmacht sehe ich kritisch.
(Picture Credits to Artificial Analysis, 18.11.2025, via LI, "Gemini 3 Pro is the new leader in AI. Google has the leading language model for the first time, with Gemini 3 Pro debuting above GPT-5.1")
xAI Launches Grok 4.1, Targeting Emotional Intelligence and Reliability to Top AI Benchmarks
#AI #xAI #Grok #ElonMusk #Grok41 #AIBenchmarks #LMArena #MachineLearning #AIethics #AIhallucination


"As AI models get better at tasks and become more integrated into our work and lives, we need to start taking the differences between them more seriously. For individuals working with AI day-to-day, vibes-based benchmarking can be enough. You can just run your otter test. Though, in my case, otters on planes have gotten too easy, so I tried the prompt “The documentary footage from 1960s about the famous last concert of that band before the incident with the swarm of otters” in Sora 2 and got this impressive result.
But organizations deploying AI at scale face a different challenge. Yes, the overall trend is clear: bigger, more recent models are generally better at most tasks. But “better” isn’t good enough when you’re making decisions about which AI will handle thousands of real tasks or advise hundreds of employees. You need to know specifically what YOUR AI is good at, not what AIs are good at on average.
That’s what the GDPval research revealed: even among top models, performance varies significantly by task. And the GuacaDrone example shows another dimension - when tasks involve judgment on ambiguous questions, different models give consistently different advice. These differences compound at scale. An AI that’s slightly worse at analyzing financial data, or consistently more risk-seeking in its recommendations, doesn’t just affect one decision, it affects thousands.
You can’t rely on vibes to understand these patterns, and you can’t rely on general benchmarks to reveal them. You need to systematically test your AI on the actual work it will do and the actual judgments it will make. Create realistic scenarios that reflect your use cases. Run them multiple times to see the patterns and take the time for experts to assess the results. Compare models head-to-head on tasks that matter to you."
https://www.oneusefulthing.org/p/giving-your-ai-a-job-interview

Moonshot AI's Kimi K2 Thinking Model Surpasses OpenAI's GPT-5
https://techlife.blog/posts/moonshot-kimi-k2-thinking-model-surpasses-openai-gpt-5/

AI benchmarks are a bad joke – and LLM makers are the ones laughing
https://www.theregister.com/2025/11/07/measuring_ai_models_hampered_by/

A #study from the #Oxford Internet Institute analysed 445 #AIbenchmarks, finding that many #oversell #AIperformance and lack scientific rigour. The study highlights issues like #uncleardefinitions, #datareuse, and inadequate #statisticalmethods, calling for more rigorous and transparent benchmark criteria. https://www.nbcnews.com/tech/tech-news/ai-chatgpt-test-smart-capabilities-may-exaggerated-flawed-study-rcna241969?eicker.news #tech #media #news
Sorry, but I think this article is pretty weak in the sense that it's very vague/superficial and doesn't go in-depth into the results of the study...
"Experts have found weaknesses, some serious, in hundreds of tests used to check the safety and effectiveness of new artificial intelligence models being released into the world.
Computer scientists from the British government’s AI Security Institute, and experts at universities including Stanford, Berkeley and Oxford, examined more than 440 benchmarks that provide an important safety net.
They found flaws that “undermine the validity of the resulting claims”, that “almost all … have weaknesses in at least one area”, and resulting scores might be “irrelevant or even misleading”.
Many of the benchmarks are used to evaluate the latest AI models released by the big technology companies, said the study’s lead author, Andrew Bean, a researcher at the Oxford Internet Institute.
In the absence of nationwide AI regulation in the UK and US, benchmarks are used to check if new AIs are safe, align to human interests and achieve their claimed capabilities in reasoning, maths and coding."

Open source AI transparency leads this week's updates, with richer model cards, dataset notes, open evals, and stronger supply chain checks.
https://www.aistory.news/open-source-ai/open-source-ai-transparency-gains-momentum-this-week/

Anthropic’s Claude Haiku 4.5 matches May’s frontier model at fraction of cost https://arstechni.ca/Qz3A #largelanguagemodels #AIdevelopmenttools #machinelearning #AIprogramming #AmazonBedrock #AIbenchmarks #ClaudeSonnet #AIalignment #ClaudeHaiku #googlecloud #codeagents #Anthropic #AIcoding #AImodels #AIsafety #VertexAI #Biz&IT #GitHub #API #AI

AI leaderboards are collapsing under Goodhart’s Law. Discover why the next evolution is personal, decentralized, and self-centered. https://hackernoon.com/ai-benchmarks-why-useless-personalized-agents-prevail #aibenchmarks
Anthropic says its new AI model “maintained focus” for 30 hours on multistep tasks https://arstechni.ca/8P3R #Computer-UsingAgent #largelanguagemodels #AIdevelopmenttools #computerusemodel #machinelearning #AIcomputeruse #SimonWillison #AIassistants #AIbenchmarks #generativeai #Programming #codeagents #opensource #Anthropic #AIagents #AIcoding #Biz&IT #AI
Scale AI Launches ‘SEAL Showdown’ LLM Leaderboard - Can it Dethrone LMArena?
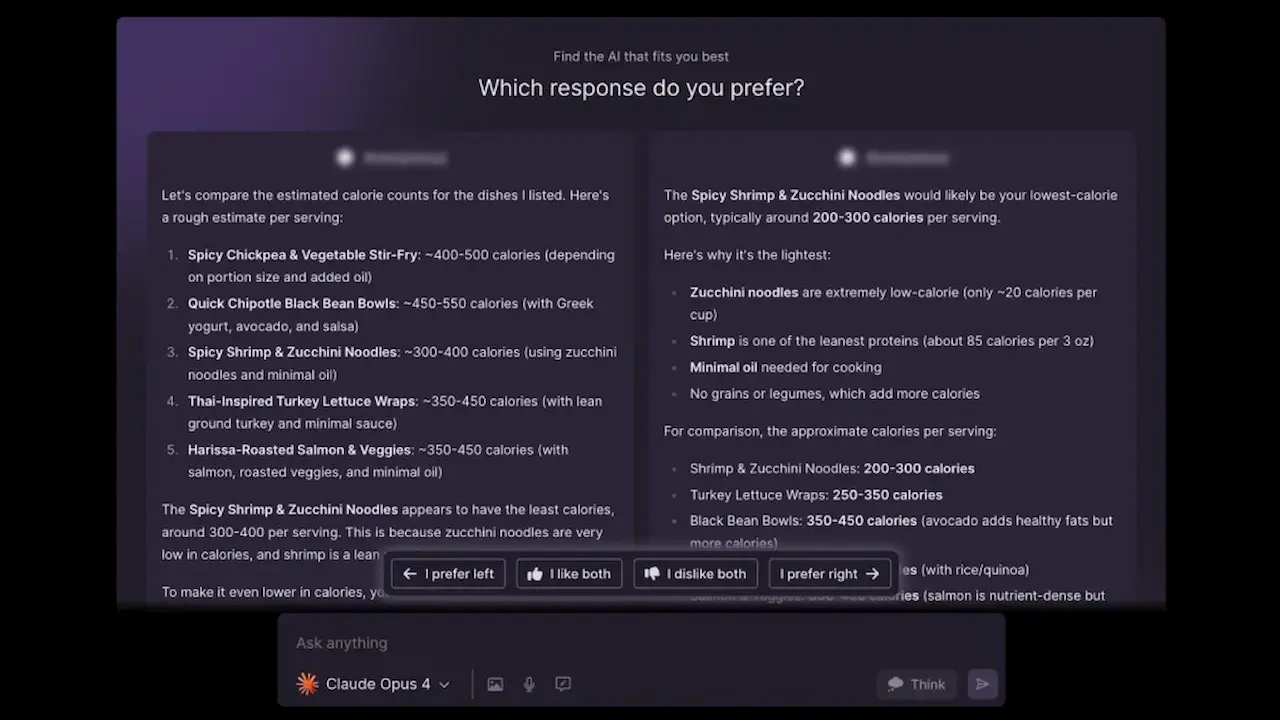


The proof that #benchmarks on #LLM models are utterly useless.
Maybe it's time to focus on real-world performance and practical applications instead of chasing numbers?
#llm #ai #aibenchmarks #llmbenchmark #machinelearning #artificialintelligence #openai #gpt5 #chatgpt
Client Info
Server: https://mastodon.social
Version: 2025.07
Repository: https://github.com/cyevgeniy/lmst