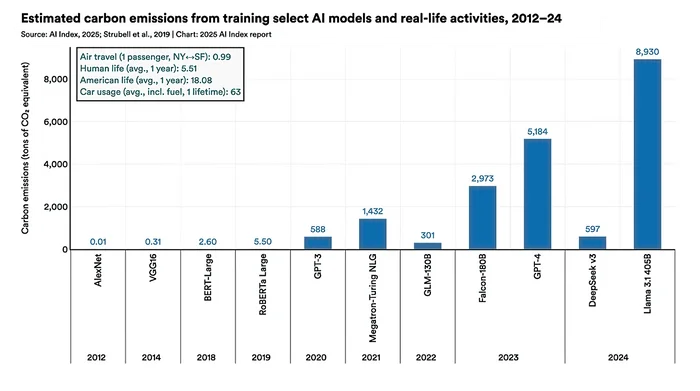
Большой тест 12 LLM моделей на арифметику (~100 тыс запросов)
Ловушка для бизнеса: почему LLM иногда 'угадывает' математику, а потом подводит? Часто вижу, как на моих ИИ-интенсивах пытаются автоматизировать нейросетями то, что легко делается без них – например, финансовый анализ из PDF. И поначалу LLM даже выдает верные цифры! Это создает опасную иллюзию, что им можно доверять расчеты. Поэтому решил получить конкретные значения: когда именно LLM начинает ошибаться в элементарных операциях – сложении, вычитании, умножении? Протестировал 12 моделей на числах разной длины. Результаты – внутри и почему калькулятор все еще ваш лучший друг, когда речь идет о числах больше 4 знаков.
https://habr.com/ru/articles/918138/
#математика #gpt #grok3 #antropic #llama #openai #sonet #gemini #ии