Preprint of the longest paper I ever contributed to: https://arxiv.org/abs/2505.08906 - it is a qualitative and quantitative comparison of various #functional #array languages, with a significant #gpgpu element.
#gpgpu
"Understanding PTX, The Assembly Language Of CUDA GPU Computing", Nvidia (https://developer.nvidia.com/blog/understanding-ptx-the-assembly-language-of-cuda-gpu-computing/).
#Nvidia #GPU #CUDA #PTX #AssemblyLanguage #IntermediateLanguage #IR #HPC #GPGPU
it is kind of wild to learn that #FluidMechanics played an integral role in the creation of #CUDA and in turn ushering in an era of #GPGPU and #AI
Ведущий разработчик ChatGPT и его новый проект — Безопасный Сверхинтеллект
Многие знают об Илье Суцкевере только то, что он выдающийся учёный и программист, родился в СССР, соосновал OpenAI и входит в число тех, кто в 2023 году изгнал из компании менеджера Сэма Альтмана. А когда того вернули, Суцкевер уволился по собственному желанию в новый стартап Safe Superintelligence («Безопасный Сверхинтеллект»). Илья Суцкевер действительно организовал OpenAI вместе с Маском, Брокманом, Альтманом и другими единомышленниками, причём был главным техническим гением в компании. Ведущий учёный OpenAI сыграл ключевую роль в разработке ChatGPT и других продуктов. Сейчас Илье всего 38 лет — совсем немного для звезды мировой величины.
https://habr.com/ru/companies/ruvds/articles/892646/
#Илья_Суцкевер #Ilya_Sutskever #OpenAI #10x_engineer #AlexNet #Safe_Superintelligence #ImageNet #неокогнитрон #GPU #GPGPU #CUDA #компьютерное_зрение #LeNet #Nvidia_GTX 580 #DNNResearch #Google_Brain #Алекс_Крижевски #Джеффри_Хинтон #Seq2seq #TensorFlow #AlphaGo #Томаш_Миколов #Word2vec #fewshot_learning #машина_Больцмана #сверхинтеллект #GPT #ChatGPT #ruvds_статьи
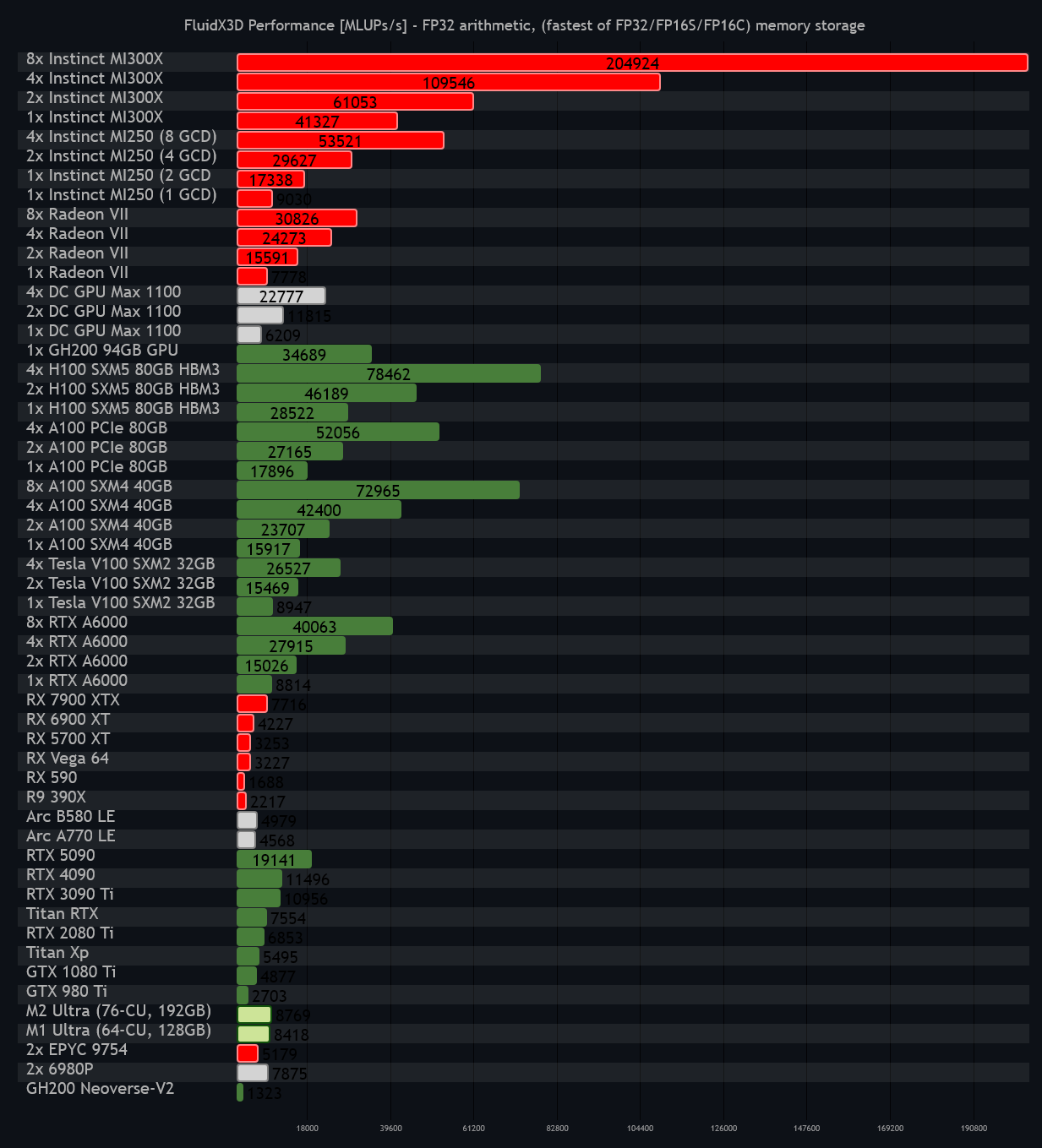
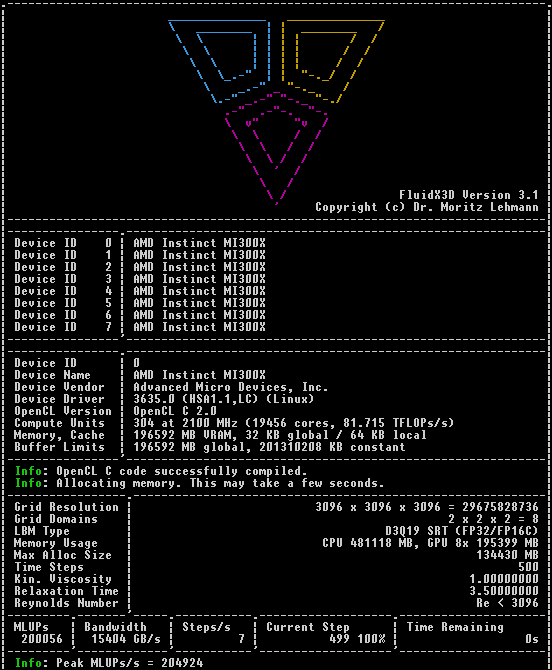
Hot Aisle's 8x AMD #MI300X server is the fastest computer I've ever tested in #FluidX3D #CFD, achieving a peak #LBM performance of 205 GLUPs/s, and a combined VRAM bandwidth of 23 TB/s. 🖖🤯
The #RTX 5090 looks like a toy in comparison.
MI300X beats even Nvidia's GH200 94GB. This marks a very fascinating inflection point in #GPGPU: #CUDA is not the performance leader anymore. 🖖😛
You need a cross-vendor language like #OpenCL to leverage its power.
FluidX3D on #GitHub: https://github.com/ProjectPhysX/FluidX3D
First day of the #GPGPU course at #UniCT. Class is small, but students seem curious, gave me the opportunity to discuss in more details some things that usually go unmentioned. Hopefully it'll hold.
Only negative side, I had to take a longer route home because the park between my house and the university was closed 8-(
I'm getting the material ready for my upcoming #GPGPU course that starts on March. Even though I most probably won't get to it,I also checked my trivial #SYCL programs. Apparently the 2025.0 version of the #Intel #OneAPI #DPCPP runtime doesn't like any #OpenCL platform except Intel's own (I have two other platforms that support #SPIRV, so why aren't they showing up? From the documentation I can find online this should be sufficient, but apparently it's not …)
Это же сколько заморочек на NVidia и Windows'ах чтобы поиграть в Го с нейронкой? (с KataGo, аналог AlphaGo).
В таких раскладах системы на ATI/AMD и линуксах выглядят разумным выбором.
Раз хочется комп, чтобы играть в Го, то берёшь с такой видяхой и такой ОС, на которых меньше всего суеты с использование GPU, точнее #GPGPU.
Вот по тегам что накопилось про игру в Го с компом — ничего принципиально сложного в настройке.
————
Видео, как на Windows настроить KataGo и потом использовать в #Sabaki (есть portable)
#^https://rutube.ru/video/de92c9e3ea5c7c1db2e1ec1b180219da/
И тоже самое на инглише
#^https://rutube.ru/video/a94c041bc840b58115ef42134f5d845c/
Понятно, что на youtube подобных видео ещё больше.
Видно, что используют простые варианты запуска KataGo в плане аргументов командной строки. Поскольку имеет свойство искать рядом с бинарником своим некий файл «default_model.bin.gz» содержащий ту нейросеть, что будет использоваться движком (если обратное не сказано через аргументы).
В моём случае жонглирую сетками и потому в GUI движок подключён слегка через более сложную строку:
————
Может кому и смешно, а я помню времена, когда пост-советские люди приобретали себе домой шахматные компьютеры. Чтобы сами играть в шахматы и детей приучать, в домах были что-то вроде «Электроника ИМ-01». Фигуры переставлять не умел и отображал координаты хода только на табло.
Такое приобретение было непростой вещью в те времена и в тех условиях. Современность же изобилует разнообразием интеллектуальных развлечений, которые и не сильно востребованы. Однако, найдутся люди рассматривающие десктоп или ноутбук именно с точки зрения средства для игры в оффлайне, а не только в онлайн. Или для анализа своих и чужих партий опять же через нейронные сети для обучения или отработки навыков игры.
#AMD #ATI #Nvidia #KataGo #games #gaming #го #igo #baduk #бадук #weiqi #вэйци #lang_ru @Russia
В таких раскладах системы на ATI/AMD и линуксах выглядят разумным выбором.
Раз хочется комп, чтобы играть в Го, то берёшь с такой видяхой и такой ОС, на которых меньше всего суеты с использование GPU, точнее #GPGPU.
Вот по тегам что накопилось про игру в Го с компом — ничего принципиально сложного в настройке.
————
Видео, как на Windows настроить KataGo и потом использовать в #Sabaki (есть portable)
#^https://rutube.ru/video/de92c9e3ea5c7c1db2e1ec1b180219da/
И тоже самое на инглише
#^https://rutube.ru/video/a94c041bc840b58115ef42134f5d845c/
Понятно, что на youtube подобных видео ещё больше.
Видно, что используют простые варианты запуска KataGo в плане аргументов командной строки. Поскольку имеет свойство искать рядом с бинарником своим некий файл «default_model.bin.gz» содержащий ту нейросеть, что будет использоваться движком (если обратное не сказано через аргументы).
В моём случае жонглирую сетками и потому в GUI движок подключён слегка через более сложную строку:
/usr/bin/katago gtp -model /abs/path/kata1-b28c512nbt-s8032072448-d4548958859.bin.gz -human-model /abs/path/b18c384nbt-humanv0.bin.gz -config /abs/path/gtp_human_search.cfg————
Может кому и смешно, а я помню времена, когда пост-советские люди приобретали себе домой шахматные компьютеры. Чтобы сами играть в шахматы и детей приучать, в домах были что-то вроде «Электроника ИМ-01». Фигуры переставлять не умел и отображал координаты хода только на табло.
Такое приобретение было непростой вещью в те времена и в тех условиях. Современность же изобилует разнообразием интеллектуальных развлечений, которые и не сильно востребованы. Однако, найдутся люди рассматривающие десктоп или ноутбук именно с точки зрения средства для игры в оффлайне, а не только в онлайн. Или для анализа своих и чужих партий опять же через нейронные сети для обучения или отработки навыков игры.
#AMD #ATI #Nvidia #KataGo #games #gaming #го #igo #baduk #бадук #weiqi #вэйци #lang_ru @Russia
So I found https://github.com/tracel-ai/cubecl which allows #gpgpu in #rust. Already using it to calculate some determinants for triangulations. Wondering if it can be leveraged to build a numeric #pde solver
This look at how many HLSL instructions different variations of an endian swap compile to with AMD tooling is... well, frankly, it's upsetting. All variations are similar, but compile down to anywhere from 1 to 13 IR ops. Contorting code to trigger desired compilation paths is familar to many GHC Haskellers, but it's an incredible deterrent to prioritizing performance. https://martinfullerblog.wordpress.com/2025/01/13/massaging-the-shader-compiler-to-emit-optimum-instructions/
@BenjaminHCCarr another article on #GPU code portability where people put their heads in the sand and pretend very hard that #OpenCL doesn't exist...
OpenCL has solved #GPGPU cross-compatibility 16 years ago already and today is in better shape than ever.

@enigmatico @lispi314 @kimapr @bunnybeam case in point:
#Bloatedness was the original post topic and yes, due to #TechBros "#BuildFastBreakThings" mentality, #Bloatware is increasing given that a shitty bloated 50+MB "#WebApp" with like nw.js is easy to slap together (and yes I did so myself!) than to put in way more thought and effort (as you can see on the slow progression of OS/1337...
Yes, #Accessibility is something that needs to be taken more seriously and it's good to see that there's at least some attemots at making #accessibility mandatory (at least in #Germany, where I know from some insider that a big telco is investing a lot in that!) for a growng number of industries and websites...
And whilst one can slap an #RTX5090 on any laptop that has a fully-functional #ExpressCard slot (with #PCIe interface, using some janky adaptors!) that'll certainly not make sense beyond some #CUDA or other #GPGPU-style workloads as it's bottlenecked to a single PCIe lane of 2.0 (500MB/s) or just 1.0a(250MB/s) speeds.
Needless to say there is a need to THINN DOWN things cuz the current speed of #Enshittifcation and bloatedness combined with #AntiRepairDesign and overpriced yet worse #tech in general makes it unsustainable for an ever increasing population!
Not everyone wants (or even can!) indebt themselves just to have a phone or laptop!
Should we aim for more "#FrugslComputing"?
- Abdolutely!
Is it realistic to expect things to be in a perfectly accessible TUI that ebery screenreader can handle?
- No!
That being said the apathy of consumers is real, and very frustrating:
People get nudged into accepting all the bs and it really pisses me off because they want me to look like ab outsider / asshole for not submitting to #consumerism and #unsustainable shite...
Still work in progress: debugging a reaction-diffusion compute shader for a GPU generated mesh.
Even better, in the afternoon I managed to find a workaround for my #GPGPU software building but hanging when trying to run it, which seems to be related to an issue with some versions of the #AMD software stack and many integrated GPUs, not just the #SteamDeck specifically. So exporting the HSA_ENABLE_SDMA=0 environment vriable was sufficient to get my software running again. I'm dropping the information here in case others find it useful.
2/2
GPU programming can be challenging. Join Engin Kayraklioglu’s live demo today (October 31st) at 10AM Pacific to see how the Chapel programming language makes it easier to program GPUs.
Find out more on the Upcoming Events page: https://chapel-lang.org/events.html
It's out, if anyone is curious
https://doi.org/10.1002/cpe.8313
This is a “how to” guide. #GPUSPH, as the name suggests, was designed from the ground up to run on #GPU (w/ #CUDA, for historical reasons). We wrote a CPU version a long time ago for a publication that required a comparison, but it was never maintained. In 2021, I finally took the plunge, and taking inspiration from #SYCL, adapted the device code in functor form, so that it could be “trivially” compiled for CPU as well.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst