If you want to understand the life cycle of software, this history of jemalloc is not a bad start
https://alecmuffett.com/article/113513
#SoftwareEcosystems #SoftwareEngineering #jemalloc
#jemalloc
If you want to understand the life cycle of software, this history of jemalloc is not a bad start
Remember: there is no bad or good here, and there is no intentionality. To assume there should have been a different outcome would be presumptuous.
There just “is”. Not everybody understands this.
Uff!
"jemalloc Postmortem", Jason Evans (https://jasone.github.io/2025/06/12/jemalloc-postmortem/).
Via HN: https://news.ycombinator.com/item?id=44264958
On Lobsters: https://lobste.rs/s/thpska/jemalloc_postmortem
#Malloc #Libc #jemalloc #MemoryManagement #Retrospective #OpenSource #FOSS #Facebook #Meta #FreeBSD #Linux #Windows #Allocators
Finally getting somewhere working on the next evolution step for #swad. I have a first version that (normally 🙈) doesn't crash quickly (so, no release yet, but it's available on the master branch).
The good news: It's indeed an improvement to have *multiple* parallel #reactor (event-loop) threads. It now handles 3000 requests per second on the same hardware, with overall good response times and without any errors. I uploaded the results of the stress test here:
https://zirias.github.io/swad/stress/
The bad news ... well, there are multiple.
1. It got even more memory hungry. The new stress test still simulates 1000 distinct clients (trying to do more fails on my machine as #jmeter can't create new threads any more...), but with delays reduced to 1/3 and doing 100 iterations each. This now leaves it with a resident set of almost 270 MiB ... tuning #jemalloc on #FreeBSD to return memory more promptly reduces this to 187 MiB (which is still a lot) and reduces performance a bit (some requests run into 429, overall response times are worse). I have no idea yet where to start trying to improve *this*.
2. It requires tuning to manage that load without errors, mainly using more threads for the thread pool, although *these* threads stay almost idle ... which probably means I have to find ways to make putting work on and off these threads more efficient. At least I have some ideas.
3. I've seen a crash which only happened once so far, no idea as of now how to reproduce. *sigh*. Massively parallel code in C really is a PITA.
Seems the more I improve here, the more I find that *should* also be improved. 🤪
Working on the next release of #swad, I just deployed an experimental build with the server-side #session completely removed.
Then I ran the same #jmeter stress test on it as before. It simulates 1000 distinct clients, all requesting the login form and then POSTing "guest:guest" login to trigger proof-of-work 50 times in a loop, timed in a way so an average of 1000 requests per second is sent.
After running this once, I thought I didn't gain much. The old version had a resident set of 95MiB, the new one 86MiB. But then running it two more times, the resident set just climbed to 96MiB and then 98Mib, while the old version ended up at something around 250MiB. 😳
So, definitely an improvement. Not sure why it still climbs to almost 100MiB at all, maybe this is #jemalloc behavior on #FreeBSD? 🤔
One side effect of removing the session is that the current jmeter test scenario doesn't hit any rate-limiting any more. So, next step will be to modify the scenario to POST invalid login credentials to trigger that again and see how it affects RAM usage.
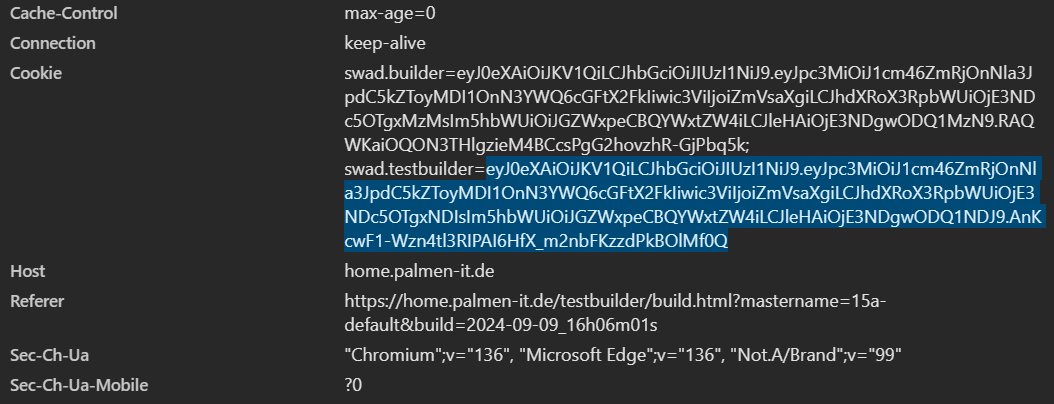
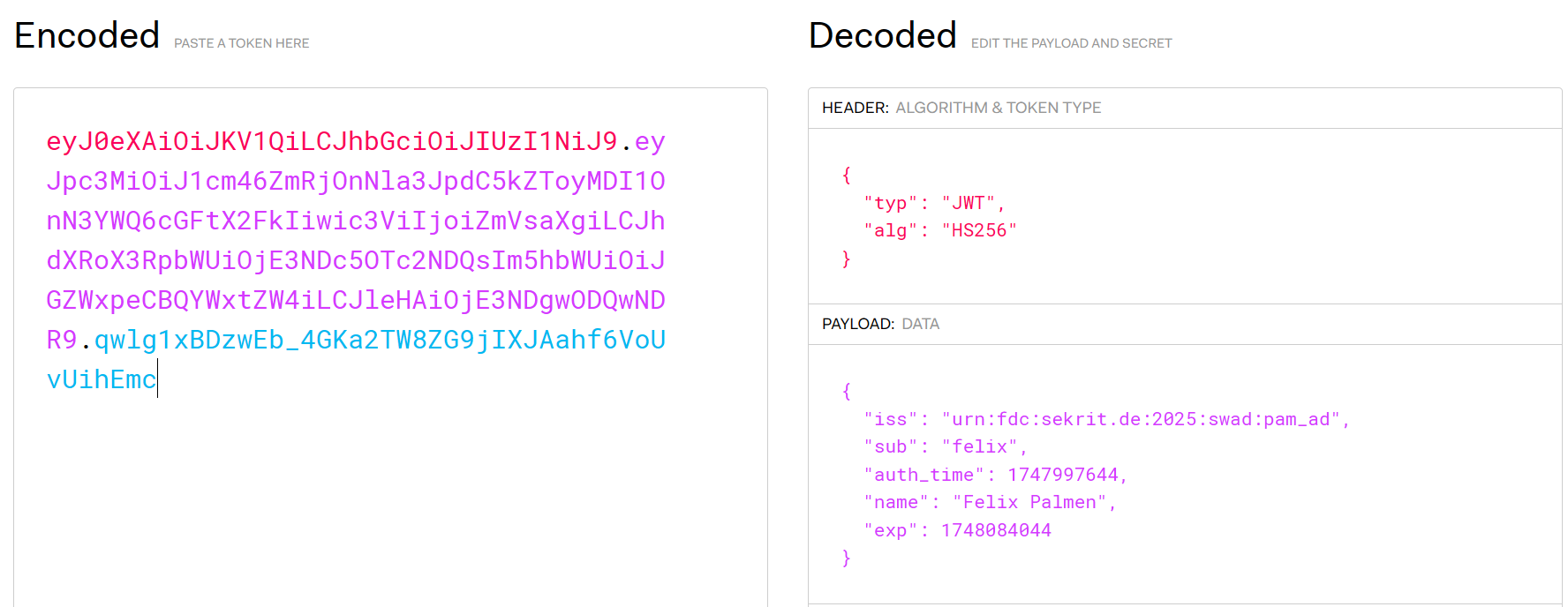
Have you ever dealt with this issue? Should I install #jemalloc right away or play detective? Setup: #ruby 2.7.8, #puma 3.12.6.
So, jetzt endlich scheint meine Instanz auf dem neuen Server rund zu laufen. Nach dem Wechsel auf den neuen Server gab es immer noch Problemchen und so richtig wurden die Anzahl der Instanzen, die meine Instanz kennen, nicht mehr.
Vor dem Umzug war ich bei ca. 28.000 Instanzen, nach dem Umzug "nur" noch ca. 18.000.
Gestern gab es dann mit einem Mal einen richtigen Schwung und man konnte zuschauen, wie die Anzahl der Instanzen immer weiter stieg. Heute sind wir dann bei 33.000, Tendenz steigend - und das bei einer Single-User-Instanz. 😅😁
Umstellung auf jemalloc war ebenfalls erfolgreich mittels dieser Anleitung.
Link: Using MariaDB with TCMalloc or jemalloc
Was MariaDB aktuell verwendet, kann man übrigens auch mittels
SHOW GLOBAL VARIABLES LIKE 'version_malloc_library';
herausfinden.

As my #Friendica server, my-place.social, has grown to some 315 active users in just 5 months, I'm starting to hit up against #mariaDB limitations relating to the default memory manager, #MALLOC. This weekend I'm going to replace it with #jemalloc to reduce stalls, memory fragmentation issues, out-of-memory problems, and instability.
Friendica puts a lot of pressure on the database, mariaDB in this case, much more than Mastodon apparently does on PostgreSQL. My feeling is that the Mastodon developers have done much better database tuning.
But, none-the-less, the update must be done. This will be done on an Ubuntu server.
Does anyone who has changed the MariaDB or mySQL memory manager have any advice to share to keep me out of trouble?
BTW, #TCMalloc is not an option as other admins have reported crashes using it with Friendica.
Released ruby-install 0.10.1 with a minor fix for homebrew users who also want to compile ruby with jemalloc support.
https://github.com/postmodern/ruby-install/releases/tag/v0.10.1
https://github.com/postmodern/ruby-install#readme
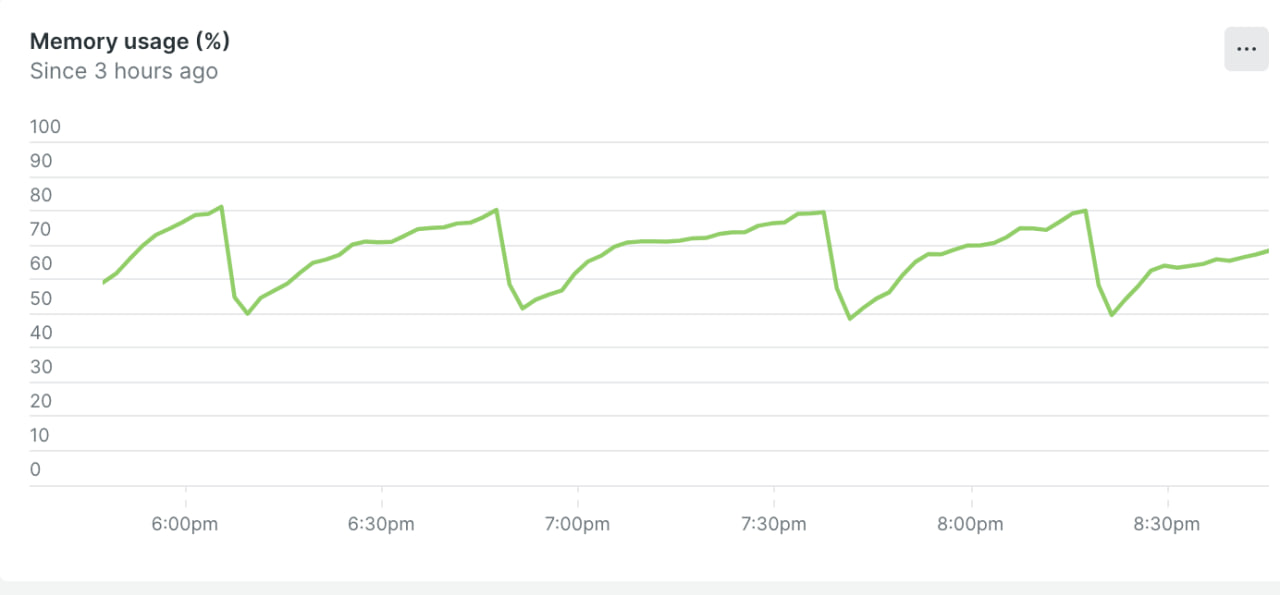
Add one more vote for using #jemalloc for #rails applications. This is our memory graph for the #Sidekiq workers.
Besides adding the linked buildpack and setting configuration options, we had nothing else to do.
https://elements.heroku.com/buildpacks/gaffneyc/heroku-buildpack-jemalloc
Released ruby-install 0.10.0! This release contains many small improvements to usability and better support for building CRuby with jemalloc or YJIT enabled.
$ ruby-install ruby -- --with-jemalloc
$ ruby-install ruby -- --enable-yjit
https://github.com/postmodern/ruby-install/releases/tag/v0.10.0
https://github.com/postmodern/ruby-install#readme
К вопросу использования #epoll вместо хорошо знакомых и «традиционных» select & poll. Т.е. асинхронной работы с чем-либо посредством polling’а и мультиплексирования.
Недавно пришлось заниматься реализацией очереди событий для AMQP-CPP. В одном из продуктов решено сделать связь агентских частей с основным «контроллером» через #AMQP, в качестве брокера #RabbitMQ (всё стандартно, обычный кластер и TLS-соединения).
Вот только агенты продукта активно используют асинхронно-реактивное программирование с хорошей «горизонтальной масштабируемостью». Когда достигнуто полноценное sharing nothing, не просто горизонтальная масштабируемость через lock-free или wait-free и закон Амдала. Исключается много всего и сразу, как старый-добрый cache ping-pong, так и печаль с false sharing.
Отсюда внутри агентов и своё управление потоками с выделениями памяти. Не только в плане heap (динамической памяти, со своими аллокаторами а-ля #jemalloc от #Facebook), но и приколы вокруг узлов #NUMA и даже huge pages (снижающих «давление» на #TLB, меньше промахов).
Первая же проблема выплыла почти сразу — не реально использовать библиотеку AMQP-CPP с уже предоставляющейся поддержкой #libev, #libuv, #libevent. Несовместимы эти очереди сообщений с имеющейся моделью управления потоками и организации задач на агентах.
Почему был взят epollПодход используемый в #epoll выглядит более современно, меньше копирований памяти между user space и kernel space. А при появлении данных в отслеживаемом файловом дескрипторе можно напрямую перейти по указателю на объект класса или структуру данных. Тем самым обходиться без поиска дескриптора по индексным массивам/контейнерам. Сразу же работать с экземплярами объектов оборачивающих нужное #tcp -соединение, того самого, в которое и пришли данные.
И тут обозначилась вторая проблема, что используема AMQP-библиотека не вычитывает данные целиком из потока сокета. Например, забирает данные лишь до тех пор, пока не насытится автомат состояний (finite-state machine), выполняющий парсинг сущностей AMQP-протокола.
Используя #epoll приходится выбирать на какой вариант обработки событий ориентироваться:
- срабатывание оповещений «по уровню» (level-triggered),
- выбрасывания событий «по фронту» (edge-triggered).
И беда с библиотекой в очередной раз показала, что нельзя использовать работу «по фронту» (edge-triggered) не изучив досконально работу подсистемы отвечающей за вычитывание данных из файловых дескрипторов. И появление флага EPOLLET в коде является маркером, о том, чтобы проводить аудит использовавшихся решений.
Про Edge Triggered Vs Level Triggered interrupts можно почитать в https://venkateshabbarapu.blogspot.com/2013/03/edge-triggered-vs-level-triggered.html)
rediscovering that jemalloc is now supported on alpine
https://github.com/jemalloc/jemalloc/issues/1443
When I was building docker images for mastodon on alpine was so hard to integrate that feature
Fun project: a #memory manager for multi-lang applications (#c, #cplusplus #assembly #fortran) in which workflow management is done by #Perl. Currently allocates using either #perl strings or #glibc malloc/calloc. Other allocators #jemalloc coming soon.
https://github.com/chrisarg/task-memmanager
Fun project: a #memory manager for multi-lang applications (#c, #cplusplus #assembly #fortran) in which workflow management is done by #Perl. Currently allocates using either #perl strings or #glibc malloc/calloc. Other allocators #jemalloc coming soon.
https://github.com/chrisarg/task-memmanager
Fun project: a #memory manager for multi-lang applications (#c, #cplusplus #assembly #fortran) in which workflow management is done by #Perl. Currently allocates using either #perl strings or #glibc malloc/calloc. Other allocators #jemalloc coming soon.
https://github.com/chrisarg/task-memmanager
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst