#OCR
手書きのテキストをpdfにして検索可能にできそう。pdfくんに完全勝利したぞ
#ocr
Optical Character Recognition, OCR: This should be easy in 2025, in particular with a software supposedly workable already in 1996 and developed since then.
I am using the tesseract command line (version 4.1.1) as it is readily available on my Ubuntu. I tried a variety of command line flags. The best output I got so far is:
OPEEEOD
where you must squint hard on the image to see the resemblance.
Any hint appreciated on how to tweak the command line.
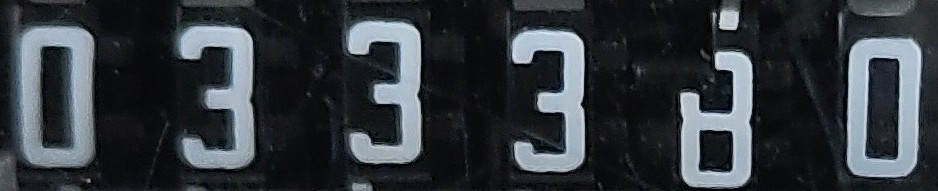
#MistralAI Document #AI: Advanced #OCR solution for complex document processing 📄
📺 https://www.youtube.com/watch?v=yrx5D5WosrU
🔧 Fine-tuned #VisionLanguageModel specifically designed for document understanding beyond traditional #OCR limitations that plague most business workflows
📊 Processes diverse file formats including #PDF files and images with complex layouts, tables, charts and poor quality scans that typically cause errors
🧵 👇

🔄 Significantly improves #RAG pipeline performance by creating context-rich, high-quality text from documents that enhances #AI application accuracy
💼 Addresses critical business challenges where traditional #OCR systems fail with slow processing speeds, prohibitive costs and error-prone results
🎬 Live demonstration by #DevRel team showcased successful processing of handwritten French doctor's notes and accurate financial data extraction
stole your meme, yaddayadda
https://mastodon.social/@lyndamerry484/114897865851198165
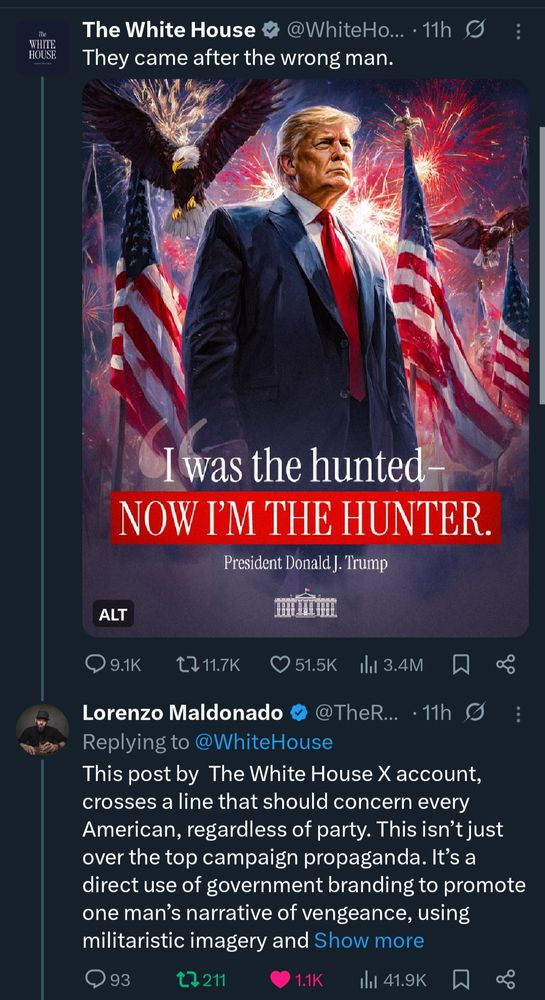
image of tweet from the Whitehouse account. it has image of Cheetolini standing in a sea of USA flags, 2 eagles and fireworks. underneath: “I was hunted. Now I’m The Hunter.”
underneath that, image of a comment: “This post by The White House X account, crosses a line that should concern every American, regardless of party. ”
full quote in the #AltTxt
#fascism #narcissism #revanchism
ps: about #OCR, the app
https://mastodon.social/@blogdiva/114869699671964023
Does anyone have recommendations for a good #Android #OCR app? I want to use it to more easily share quotes from a paper book. (so camera -> OCR -> Mastodon)
In the past I used Google Lens for this, but it has started to insist I need to search or translate immediately instead of just letting me grab the text.
I did find https://github.com/SubhamTyagi/android-ocr but it doesn't do as good a job as Google Lens. (Perhaps no privacy-respecting OCR app can?)
Today I learned that the Preview app on #MacOS can #OCR #PDF documents. When exporting or saving the document as PDF, a selection box appears to ‘Embed Text’. This will OCR your document and embed the text as the manual states: “Preview scans for text and embeds it in the PDF so that it can be selected in any PDF viewer.”
https://support.apple.com/en-gb/guide/preview/prvw1ddb1cdf/mac
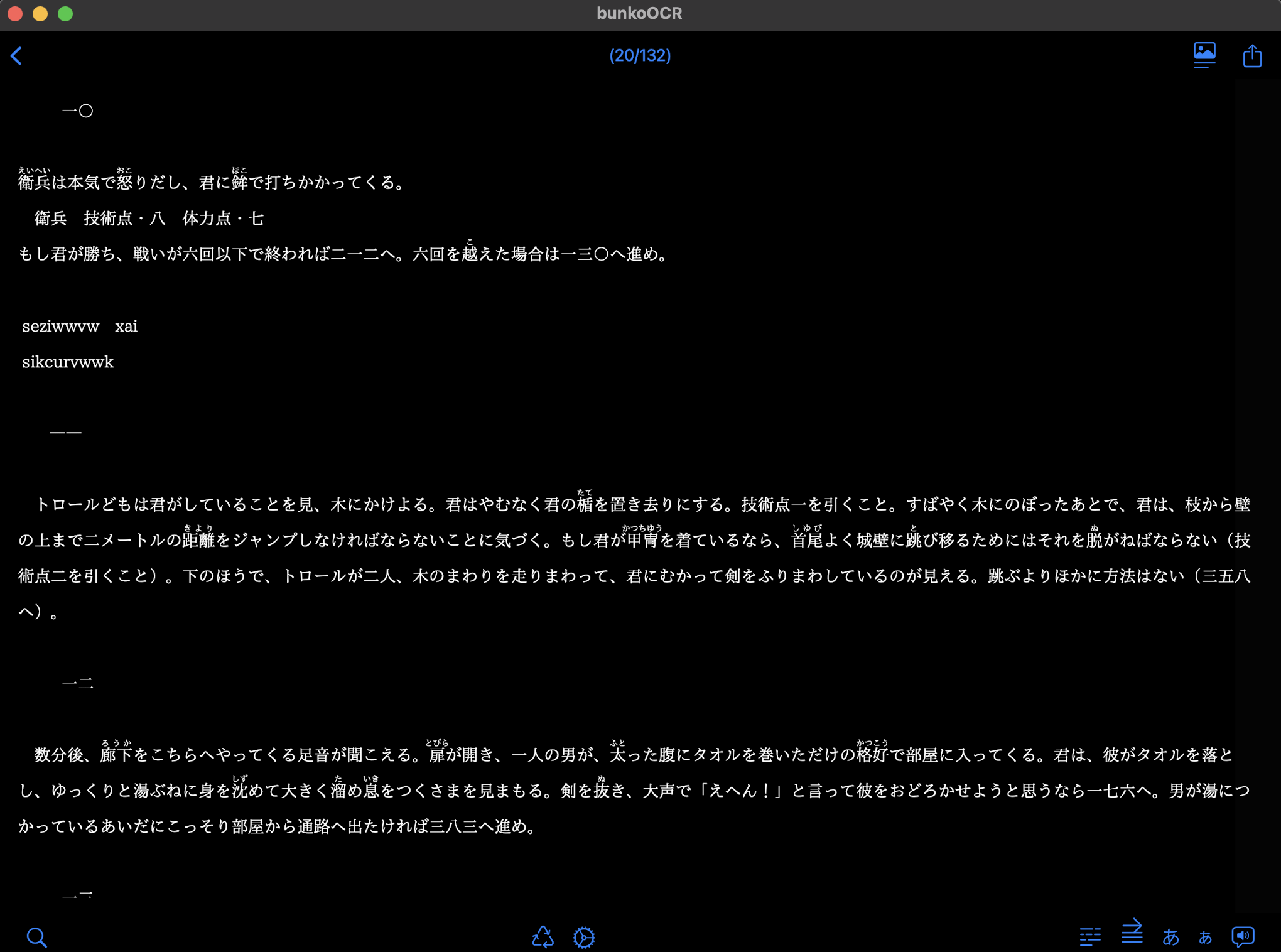
ゲームブックを #bunkoOCR で #OCR してみた。行を繋げるオプションを調節したら、まあまあ読める感じにスキャンできそう。
[出典]
現代教養文庫
1148
盗賊都市
ーアドベンチャーゲーム ブックー
I・リビングストン 著
喜多元子訳
社会思想社

#OCR
撮影してOCRすると、撮影条件によって精度が左右されちゃうのよね
ノドのところの曲がりが鬼門ですな。だいぶ対応させたけど、振り仮名とかは微妙に上下がズレて変なところにマッピングされちゃう
Έχετε βρει ποτέ κείμενο σε μια εικόνα ή ένα PDF που θέλατε απεγνωσμένα να αντιγράψετε και να επεξεργαστείτε; 😫 Τέρμα η κουραστική πληκτρολόγηση! ✨
Με τη νέα λειτουργία OCR με τεχνητή νοημοσύνη στον Επεξεργαστή PDF του @ONLYOFFICE, μπορείτε πλέον να μετατρέπετε οποιαδήποτε εικόνα σε πλήρως επεξεργάσιμο κείμενο με ένα μόνο κλικ. 🤖📄
Διαβάστε περισσότερα εδώ 👉 https://www.onlyoffice.com/blog/el/2025/07/ai-powered-ocr-in-onlyoffice-pdf-editor
#ONLYOFFICE #OCR #PDF #AI #Productivity #Tech #Λογισμικό #Παραγωγικότητα #ΤεχνητήΝοημοσύνη #ΜετατροπήΚειμένου
#OCR
イラストのページを、文字と誤爆したやつを消せるようにしてみた。
改ページもほぼ完璧に認識できるようになってきた(この本は)
そろそろリリースできそう
h/t to Gossi for the previous post
https://cyberplace.social/@GossiTheDog/114869284832294345
and i say this lovingly:
one of the most powerful apps you can have on any mobile device ―as well as all of your computers― is the #OCR scanner.
here’s the link at F-droid:
https://f-droid.org/packages/io.github.subhamtyagi.ocr
it’s in my top 10 apps & software to have & use.
and on dotSocial, AltTxt has actually 5 times the text capacity than a toot. i use and abuse it for that reason 😉
#OCR するのに、本を見開きで撮影するときにちょっと真ん中からズレてしまって、ページ分離のロジックを見直す必要がでてしまった。
ちゃんとページの境目の直線を検出するようにしてみたら、少々中心からズレてても動くようになったっぽ
@hauch Wenn einfach nur der Text transkribiert ist, dann ist das nie Handarbeit. Dann hat da jemand einfach nur irgendeine eingebaute OCR-Funktion verwendet, fire and forget, und das dann so abgeschickt.
Nur ist ein OCR-System keine voll ausgefuchste und allwissende Bildbeschreibungs-KI, die das ganze Bild beschreiben und womöglich auch noch mit 100%iger Sicherheit erkennen kann, was für ein User Interface von was für Software da auf dem Bild zu sehen ist.
Gleichzeitig sind die Leute eben faul. Kaum einer setzt sich wirklich hin und guckt sich Bilder genau an und beschreibt sie dann sauber und akkurat und hinreichend detailliert.
Es gibt ja diese Statistiken, auf welchen Mastodon-Servern wie groß der Anteil der Bilder mit Alt-Text ist (allerdings nur für Mastodon). Wenn solche Statistiken automatisch dafür generiert werden könnten, wieviele von diesen Bildern wirklich 100% akkurat und hinreichend detailliert beschrieben wurden, würde das wieder ganz anders aussehen.
(Für die Akten: Ich beschreibe meine Bilder immer per Hand. Ich transkribiere auch alle Texte per Hand. Und ich tue das extrem detailliert. Deswegen habe ich 2025 noch kein einziges neues Bild gepostet: Der zeitliche Aufwand pro Bild ist zu groß.)
#Long #LongPost #CWLong #CWLongPost #LangerPost #CWLangerPost #Bildbeschreibung #Bildbeschreibungen #BildbeschreibungenMeta #CWBildbeschreibungenMeta #KI #OCR
Nur ist ein OCR-System keine voll ausgefuchste und allwissende Bildbeschreibungs-KI, die das ganze Bild beschreiben und womöglich auch noch mit 100%iger Sicherheit erkennen kann, was für ein User Interface von was für Software da auf dem Bild zu sehen ist.
Gleichzeitig sind die Leute eben faul. Kaum einer setzt sich wirklich hin und guckt sich Bilder genau an und beschreibt sie dann sauber und akkurat und hinreichend detailliert.
Es gibt ja diese Statistiken, auf welchen Mastodon-Servern wie groß der Anteil der Bilder mit Alt-Text ist (allerdings nur für Mastodon). Wenn solche Statistiken automatisch dafür generiert werden könnten, wieviele von diesen Bildern wirklich 100% akkurat und hinreichend detailliert beschrieben wurden, würde das wieder ganz anders aussehen.
(Für die Akten: Ich beschreibe meine Bilder immer per Hand. Ich transkribiere auch alle Texte per Hand. Und ich tue das extrem detailliert. Deswegen habe ich 2025 noch kein einziges neues Bild gepostet: Der zeitliche Aufwand pro Bild ist zu groß.)
#Long #LongPost #CWLong #CWLongPost #LangerPost #CWLangerPost #Bildbeschreibung #Bildbeschreibungen #BildbeschreibungenMeta #CWBildbeschreibungenMeta #KI #OCR
British Library Digital Scholarship Blog: Automatic Text Recognition in Cultural Heritage Institutions survey: a brief analysis and a published dataset. “A few months ago, we circulated a brief survey to understand how other institutions use Automatic Text Recognition and to discuss the creation of a working group on the subject… I am happy to report that the anonymised data are available […]
💡 Wie lassen sich Methoden des Machine Learning sinnvoll in der Sammlungsdigitalisierung & -forschung einsetzen?
Im Interview spricht unser Kollege @mathias_zinnen über:
🔍 ML-Methoden für Text, Bild & strukturierte Daten
🛠️ Open-Source-Tools
💡 Vermittlungsangebote zu ML-Tools im Sammlungskontext
🌱 Warum ressourcenschonende ML-Ansätze wichtig sind
➡️ https://sammlungen.io/blog/interview-mit-fachexpertise-2d-und-machine-learning?utm_campaign=coschedule&utm_source=mastodon&utm_medium=SODa%40fedihum.org
#MachineLearning #2D #SODaZentrum #OCR #ML

Η δουλειά στο Android κινητό σας έγινε μόλις πιο εύκολη! 🚀
Το @ONLYOFFICE Documents 9.0 για Android είναι εδώ, φέρνοντας απίστευτες νέες δυνατότητες που θα αλλάξουν τον τρόπο που εργάζεστε εν κινήσει.
Είστε έτοιμοι να αναβαθμίσετε την παραγωγικότητά σας; 🤔
👇 Διαβάστε όλες τις λεπτομέρειες στο νέο άρθρο και κατεβάστε την εφαρμογή δωρεάν!
https://www.onlyoffice.com/blog/el/2025/07/documents-9-for-android
#ONLYOFFICE #Android #Update #Productivity #NewFeatures #OCR #DocSpace #Tech #Εφαρμογές #Παραγωγικότητα #Τεχνολογία
How-To Geek: How to Turn an Image Into Google Sheets Data With OCR in Google Drive. “Copying data from an image into a Google Sheets file manually can be time-consuming and increases the chances of typos. Luckily, you can extract the information into your spreadsheet in just a few simple steps using the Optical Character Recognition (OCR) tool in Google Drive. Here’s how.”
Related to my epub DRM gripe, gImageReader (a front-end for Tesseract) does a great job of OCRing screen shots.
I'd still prefer a sane, reliable way to strip Adobe's DRM from epubs, or for publishers to stop using it.
Client Info
Server: https://mastodon.social
Version: 2025.04
Repository: https://github.com/cyevgeniy/lmst