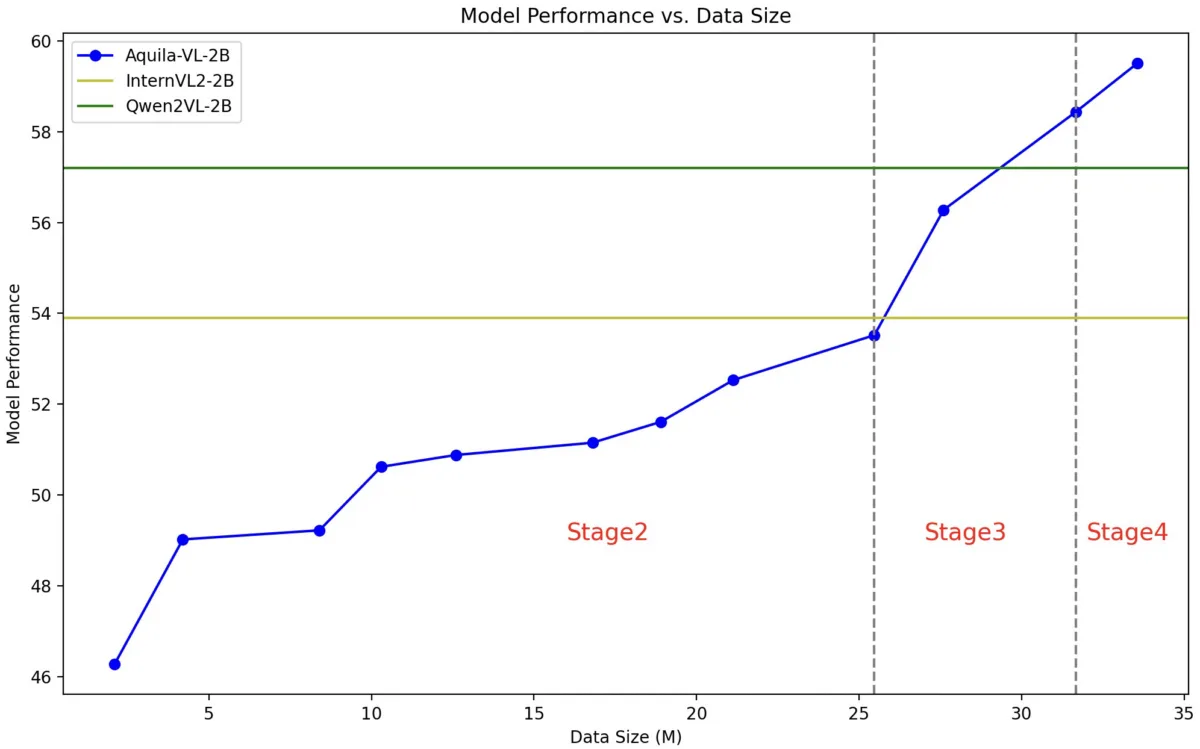
@
Michal Bryxí 🌱 And since you obviously haven't actually read anything I've linked to, here's a quote-post of my comment in which I dissect the first AI description.
Jupiter Rowland wrote the following post Tue, 05 Mar 2024 20:28:12 +0100 (This is actually a comment. Find another post further up in this thread.)Now let's pry LLaVA's image description apart, shall we?
The image appears to be a 3D rendering or a screenshot from a video game or a virtual environment.
Typical for an AI: It starts vague. That's because it isn't really sure what it's looking at.
This is not a video game. It's a 3-D virtual world.
At least, LLaVA didn't take this for a real-life photograph.
It shows a character
It's an
avatar, not a character.
standing on a paved path with a brick-like texture.
This is the first time that the AI is accurate without being vague. However, there could be more details to this.
The character is facing away from the viewer,
And
I can and do tell the audience in my own image description
why my avatar is facing away from the viewer. Oh, and that it's the avatar of the creator of this picture, namely myself.
looking towards a sign or information board on the right side of the image.
Nope. Like the AI could see the eyeballs of my avatar from behind. The avatar is actually looking at the cliff in the background.
Also, it's clearly an advertising board.
The environment is forested with tall trees and a dense canopy, suggesting a natural, possibly park-like setting.
If I'm generous, I can let this pass as not exactly wrong. Only that there is no dense canopy, and this is not a park.
The lighting is subdued, with shadows cast by the trees, indicating either early morning or late afternoon.
Nope again. It's actually late morning. The AI doesn't know because it can't tell that the Sun is in the southeast, and because it has got no idea how tall the trees actually are, what with almost all treetops and half the shadow cast by the avatar being out of frame.
The overall atmosphere is calm and serene.
In a setting inspired by thrillers from the 1950s and 1960s. You're adorable, LLaVA. Then again, it was quiet because there was no other avatar present.
There's a whole lot in this image that LLaVA didn't mention at all. First of all, the most blatant shortcomings.
First of all, the colours. Or the lack of them. LLaVA doesn't say with a single world that everything is monochrome. What it's even less aware of is that
the motive itself is monochrome, i.e. this whole virtual place is actually monochrome, and the avatar is monochrome, too.
Next, what does my avatar look like? Gender? Skin? Hair? Clothes?
Then there's that thing on the right. LLaVA doesn't even mention that this thing is there.
It doesn't mention the sign to the left, it doesn't mention the cliff at the end of the path, it doesn't mention the mountains in the background, and it's unaware of both the bit of sky near the top edge and the large building hidden behind the trees.
And it does not transcribe even one single bit of text in this image.
And now for what I think should really be in the description, but what no AI will ever be able to describe from looking at an image like this one.
A good image description should mention where an image was taken. AIs can currently only tell that when they're fed famous landmarks. AI won't be able to tell from looking at this image that it was taken at the central crossroads at Black White Castle, a sim in the OpenSim-based Pangea Grid anytime soon. And I'm not even talking about explaining OpenSim, grids and all that to people who don't know what it is.
Speaking of which, the object to the right. LLaVA completely ignores it. However, it should be able to not only correctly identify it as an OpenSimWorld beacon, but also describe what it looks like and explain to the reader what an OpenSimWorld beacon is, what OpenSimWorld is etc. because it should know that this can not be expected to be common knowledge. My own description does that in round about 5,000 characters.
And LLaVA should transcribe what's written on the touch screen which it should correctly identify as a touch screen. It should also mention the sign on the left and transcribe what's written on it.
In fact,
all text
anywhere within the borders of the picture should be transcribed 100% verbatim. Since there's no rule against transcribing text that's so small that it's illegible or that's so tiny that it's practically invisible or that's partially obscured or partially out of frame, a good AI should be capable of transcribing such text 100% verbatim in its entirety as well. Unless text is too small for me to read in-world, I can and do that.
And how about not only
knowing that the advertising board is an advertising board, but also mentioning and
describing what's on it? Technically speaking, there's actually a lot of text on that board, and in order to transcribe it, its context needs to be described. That is, I must admit I was sloppy myself and omitted a whole lot of transcriptions in my own description.
Still, AI has a very very long way to go. And it will never fully get there.
#
Long #
LongPost #
CWLong #
CWLongPost #
AltText #
ImageDescription #
ImageDescriptions #
ImageDescriptionMeta #
CWImageDescriptionMeta #
AI #
LLaVA #
Long #
LongPost #
CWLong #
CWLongPost #
VirtualWorlds #
AltText #
AltTextMeta #
CWAltTextMeta #
ImageDescription #
ImageDescriptions #
ImageDescriptionMeta #
CWImagDescriptionMeta #
LLaVA #
AI #
AIVsHuman #
HumanVsAI